


In the first part of the Glossary of Modern JS Concepts series, we'll gain an understanding of functional programming, reactive programming, and functional reactive programming. To do so, we'll learn about purity, statefulness and statelessness, immutability and mutability, imperative and declarative programming, higher-order functions, observables, and the FP, RP, and FRP paradigms.
Modern JavaScript has experienced massive proliferation over recent years and shows no signs of slowing. Numerous concepts appearing in JS blogs and documentation are still unfamiliar to many front-end developers. In this post series, we'll learn intermediate and advanced concepts in the current front-end programming landscape and explore how they apply to modern JavaScript.
Purity: Pure Functions, Impure Functions, Side Effects
Pure Functions
A pure function's return value is determined only by its input values (arguments) with no side effects. When given the same argument, the result will always be the same. Here is an example:
function half(x) {
return x / 2;
}The half(x) function takes a number x and returns a value of half of x. If we pass an argument of 8 to this function, the function will always return 4. When invoked, a pure function can be replaced by its result. For example, we could replace half(8) with 4 wherever used in our code with no change to the final outcome. This is called referential transparency.
Pure functions only depend on what's passed to them. For example, a pure function cannot reference variables from a parent scope unless they are explicitly passed into the function as arguments. Even then, the function can not modify the parent scope.
// some variable that is mutated
let someNum = 8;
// this is NOT a pure function
function impureHalf() {
return someNum / 2;
}In summary:
- Pure functions must take arguments.
- The same input (arguments) will always produce the same output (return).
- Pure functions rely only on local state and do not mutate external state (note:
console.logchanges global state). - Pure functions do not produce side effects.
- Pure functions cannot call impure functions.
Impure Functions
An impure function mutates state outside its scope. Any function that has side effects (see below) is impure.
Consider the following examples:
// impure function producing a side effect
function showAlert() {
alert('This is a side effect!');
}
// impure function mutating external state
var globalVal = 1;
function incrementGlobalVal(x) {
globalVal += x;
}
// impure function that resembles a pure function,
// but returns different results given the same inputs
function getRandomRange(min, max) {
return Math.random() * (max - min) + min;
}Side Effects in JavaScript
When a function or expression modifies state outside its own context, the result is a side effect. Examples of side effects include making a call to an API, manipulating the DOM, raising an alert dialog, writing to a database, etc. If a function produces side effects, it is considered impure. Functions that cause side effects are less predictable and harder to test since they result in changes outside their local scope.
Purity Takeaways
Plenty of quality code consists of impure functions that procedurally invoke pure functions. This still produces advantages for testing and immutability. Referential transparency also enables memoization: caching and storing function call results and reusing the cached results when the same inputs are used again. It can be a challenge to determine when functions are truly pure.
To learn more about purity, check out the following resources:
- Pure versus impure functions
- Master the JavaScript Interview: What is a Pure Function?
- Functional Programming: Pure Functions
State
State refers to the information a program has access to and can operate on at a point in time. This includes data stored in memory as well as OS memory, input/output ports, database, etc. For example, the contents of variables in an application at any given instant are representative of the application's state.
Stateful
Stateful programs, apps, or components store data in memory about the current state. They can modify the state as well as access its history. The following example is stateful:
// stateful
var number = 1;
function increment() {
return number++;
}
increment(); // global variable modified: number = 2Stateless
Stateless functions or components perform tasks as though running them for the first time, every time. This means they do not reference or utilize any information from earlier in their execution. Statelessness enables referential transparency. Functions depend only on their arguments and do not access or need knowledge of anything outside their scope. Pure functions are stateless. See the following example:
// stateless
var number = 1;
function increment(n) {
return n + 1;
}
increment(number); // global variable NOT modified: returns 2Stateless applications do still manage state. However, they return their current state without mutating previous state. This is a tenet of functional programming.
State Takeaways
State management is important for any complex application. Stateful functions or components modify state and store history, but are more difficult to test and debug. Stateless functions rely only on their inputs to produce outputs. A stateless program returns new state rather than modifying existing state.
To learn more about state, check out the following resources:
- State
- Advantages of stateless programming
- Stateful and stateless components, the missing manual
- Redux: predictable state container for JavaScript apps
Immutability and Mutability
The concepts of immutability and mutability are slightly more nebulous in JavaScript than in some other programming languages. However, you will hear a lot about immutability when reading about functional programming in JS. It's important to know what these terms mean classically and also how they are referenced and implemented in JavaScript. The definitions are simple enough:
Immutable
If an object is immutable, its value cannot be modified after creation.
Mutable
If an object is mutable, its value can be modified after creation.
By Design: Immutability and Mutability in JavaScript
In JavaScript, strings and number literals are immutable by design. This is easily understandable if we consider how we operate on them:
var str = 'Hello!';
var anotherStr = str.substring(2);
// result: str = 'Hello!' (unchanged)
// result: anotherStr = 'llo!' (new string)Using the .substring() method on our Hello! string does not modify the original string. Instead, it creates a new string. We could reassign the str variable value to something else, but once we've created our Hello! string, it will always be Hello!.
Number literals are immutable as well. The following will always have the same result:
var three = 1 + 2;
// result: three = 3Under no circumstances could 1 + 2 evaluate to anything other than 3.
This demonstrates that immutability by design does exist in JavaScript. However, JS developers are aware that the language allows most things to be changed. For example, objects and arrays are mutable by design. Consider the following:
var arr = [1, 2, 3];
arr.push(4);
// result: arr = [1, 2, 3, 4]
var obj = { greeting: 'Hello' };
obj.name = 'Jon';
// result: obj = { greeting: 'Hello', name: 'Jon' }In these examples, the original objects are mutated. New objects are not returned.
To learn more about mutability in other languages, check out Mutable vs Immutable Objects.
In Practice: Immutability in JavaScript
Functional programmingin JavaScript has gained a lot of momentum. But by design, JS is a very mutable, multi-paradigm language. Functional programming emphasizes immutability. Other functional languages will raise errors when a developer tries to mutate an immutable object. So how can we reconcile the innate mutability of JS when writing functional or functional reactive JS?
When we talk about functional programming in JS, the word "immutable" is used a lot, but it's the responsibility of the developer to write their code with immutability in mind. For example, Redux relies on a single, immutable state tree. However, JavaScript itself is capable of mutating the state object. To implement an immutable state tree, we need to return a new state object each time the state changes.
JavaScript objects can also be frozen with Object.freeze(obj) to make them immutable. Note that this is shallow, meaning object values within a frozen object can still be mutated. To further ensure immutability, functions like Mozilla's deepFreeze() and npm deep-freeze can recursively freeze objects. Freezing is most practical when used in tests rather than in application JS. Tests will alert developers when mutations occur so they can be corrected or avoided in the actual build without Object.freeze cluttering up the core code.
There are also libraries available to support immutability in JS. Mori delivers persistent data structures based on Clojure. Immutable.js by Facebook also provides immutable collections for JS. Utility libraries like Underscore.js and lodash provide methods and modules to promote a more immutable functional programming style.
Immutability and Mutability Takeaways
Overall, JavaScript is a very mutable language. Some styles of JS coding rely on this innate mutability. However, when writing functional JS, implementing immutability requires mindfulness. JS will not natively throw errors when you modify something unintentionally. Testing and libraries can assist, but working with immutability in JS takes practice and methodology.
Immutability has advantages. It results in code that is simpler to reason about. It also enables persistency, the ability to keep older versions of a data structure and copy only the parts that have changed.
The disadvantage of immutability is that many algorithms and operations cannot be implemented efficiently.
To learn more about immutability and mutability, check out the following resources:
- Immutability in JavaScript
- Immutable Objects with Object Freeze
- Mutable vs Immutable Objects
- Using Immutable Data Stuctures in JavaScript
- Getting Started with Redux (includes examples for addressing immutable state)
Imperative and Declarative Programming
While some languages were designed to be imperative (C, PHP) or declarative (SQL, HTML), JavaScript (and others like Java and C#) can support both programming paradigms.
Most developers familiar with even the most basic JavaScript have written imperative code: instructions informing the computer how to achieve a desired result. If you've written a for loop, you've written imperative JS.
Declarative code tells the computer what you want to achieve rather than how, and the computer takes care of how to achieve the end result without explicit description from the developer. If you've used Array.map, you've written declarative JS.
Imperative Programming
Imperative programming describes how a program's logic works in explicit commands with statements that modify the program state.
Consider a function that increments every number in an array of integers. An imperative JavaScript example of this might be:
function incrementArray(arr) {
let resultArr = [];
for (let i = 0; i < arr.length; i++) {
resultArr.push(arr[i] + 1);
}
return resultArr;
}This function shows exactly how the function's logic works: we iterate over the array and explicitly increase each number, pushing it to a new array. We then return the resulting array. This is a step-by-step description of the function's logic.
Declarative Programming
Declarative programming describes what a program's logic accomplishes without describing how.
A very straightforward example of declarative programming can be demonstrated with SQL. We can query a database table (People) for people with the last name Smith like so:
SELECT * FROM People WHERE LastName = 'Smith'This code is easy to read and describes what we want to accomplish. There is no description of how the result should be achieved. The computer takes care of that.
Now consider the incrementArray() function we implemented imperatively above. Let's implement this declaratively now:
function incrementArray(arr) {
return arr.map(item => item + 1);
}We show what we want to achieve, but not how it works. The Array.map() method returns a new array with the results of running the callback on each item from the passed array. This approach does not modify existing values, nor does it include any sequential logic showing how it creates the new array.
Note: JavaScript's
map,reduce, andfilterare declarative, functional array methods. Utility libraries like lodash provide methods liketakeWhile,uniq,zip, and more in addition tomap,reduce, andfilter.
Imperative and Declarative Programming Takeaways
As a language, JavaScript allows both imperative and declarative programming paradigms. Much of the JS code we read and write is imperative. However, with the rise of functional programming in JS, declarative approaches are becoming more common.
Declarative programming has obvious advantages with regard to brevity and readability, but at the same time it can feel magical. Many JavaScript beginners can benefit from gaining experience writing imperative JS before diving too deep into declarative programming.
To learn more about imperative and declarative programming, check out the following resources:
- Imperative vs Declarative Programming
- What's the Difference Between Imperative, Procedural, and Structured Programming?
- Imperative and (Functional) Declarative JS In Practice
- JavaScript's Map, Reduce, and Filter
Higher-order Functions
A higher-order function is a function that:
- accepts another function as an argument, or
- returns a function as a result.
In JavaScript, functions are first-class objects. They can be stored and passed around as values: we can assign a function to a variable or pass a function to another function.
const double = function(x) {
return x * 2;
}
const timesTwo = double;
timesTwo(4); // result: returns 8One example of taking a function as an argument is a callback. Callbacks can be inline anonymous functions or named functions:
const myBtn = document.getElementById('myButton');
// anonymous callback function
myBtn.addEventListener('click', function(e) { console.log(`Click event: ${e}`); });
// named callback function
function btnHandler(e) {
console.log(`Click event: ${e}`);
}
myBtn.addEventListener('click', btnHandler);We can also pass a function as an argument to any other function we create and then execute that argument:
function sayHi() {
alert('Hi!');
}
function greet(greeting) {
greeting();
}
greet(sayHi); // alerts "Hi!"Note: When passing a named function as an argument, as in the two examples above, we don't use parentheses
(). This way we're passing the function as an object. Parentheses execute the function and pass the result instead of the function itself.
Higher-order functions can also return another function:
function whenMeetingJohn() {
return function() {
alert('Hi!');
}
}
var atLunchToday = whenMeetingJohn();
atLunchToday(); // alerts "Hi!"Higher-order Function Takeaways
The nature of JavaScript functions as first-class objects make them prime for facilitating functional programming.
To learn more about higher-order functions, check out the following resources:
- Functions are first class objects in JavaScript
- Higher-Order Functions in JavaScript
- Higher-order functions - Part 1 of Functional Programming in JavaScript
- Eloquent JavaScript - Higher-order Functions
- Higher Order Functions
Functional Programming
Now we've learned about purity, statelessness, immutability, declarative programming, and higher-order functions. These are all concepts that are important in understanding the functional programming paradigm.
In Practice: Functional Programming with JavaScript
Functional programming encompasses the above concepts in the following ways:
- Core functionality is implemented using pure functions without side effects.
- Data is immutable.
- Functional programs are stateless.
- Imperative container code manages side effects and executes declarative, pure core code.*
*If we tried to write a JavaScript web application composed of nothing but pure functions with no side effects, it couldn't interact with its environment and therefore wouldn't be particularly useful.
Let's explore an example. Say we have some text copy and we want to get its word count. We also want to find keywords that are longer than five characters. Using functional programming, our resulting code might look something like this:
const fpCopy = `Functional programming is powerful and enjoyable to write. It's very cool!`;
// remove punctuation from string
const stripPunctuation = (str) =>
str.replace(/[.,\/#!$%\^&\*;:{}=\-_`~()]/g, '');
// split passed string on spaces to create an array
const getArr = (str) =>
str.split(' ');
// count items in the passed array
const getWordCount = (arr) =>
arr.length;
// find items in the passed array longer than 5 characters
// make items lower case
const getKeywords = (arr) =>
arr
.filter(item => item.length > 5)
.map(item => item.toLowerCase());
// process copy to prep the string, create an array, count words, and get keywords
function processCopy(str, prepFn, arrFn, countFn, kwFn) {
const copyArray = arrFn(prepFn(str));
console.log(`Word count: ${countFn(copyArray)}`);
console.log(`Keywords: ${kwFn(copyArray)}`);
}
processCopy(fpCopy, stripPunctuation, getArr, getWordCount, getKeywords);
// result: Word count: 11
// result: Keywords: functional,programming,powerful,enjoyableThis code is available to run at this JSFiddle: Functional Programming with JavaScript. It's broken into digestible, declarative functions with clear purpose. If we step through it and read the comments, no further explanation of the code should be necessary. Each core function is modular and relies only on its inputs (pure). The last function processes the core to generate the collective outputs. This function, processCopy(), is the impure container that executes the core and manages side effects. We've used a higher-order function that accepts the other functions as arguments to maintain the functional style.
Functional Programming Takeaways
Immutable data and statelessness mean that the program's existing state is not modified. Instead, new values are returned. Pure functions are used for core functionality. In order to implement the program and handle necessary side effects, impure functions can call pure functions imperatively.
To learn more about functional programming, check out the following resources:
- Introduction to Immutable.js and Functional Programming Concepts
- Functional Programming For The Rest of Us
- Functional Programming with JavaScript
- Don't be Scared of Functional Programming
- So You Want to be a Functional Programmer
- lodash - Functional Programming Guide
- What is the difference between functional and imperative programming languages?
- Eloquent JavaScript, 1st Edition - Functional Programming
- Functional Programming by Example
- Functional Programming in JavaScript - Video Series
- Introduction to Functional JavaScript
- How to perform side effects in pure functional programming
- Preventing Side Effects in JavaScript
Observables
Observables are similar to arrays, except instead of being stored in memory, items arrive asynchronously over time (also called streams). We can subscribe to observables and react to events emitted by them. JavaScript observables are an implementation of the observer pattern. Reactive Extensions (commonly known as Rx*) provides an observables library for JS via RxJS.
To demonstrate the concept of observables, let's consider a simple example: resizing the browser window. It's easy to understand observables in this context. Resizing the browser window emits a stream of events over a period of time as the window is dragged to its desired size. We can create an observable and subscribe to it to react to the stream of resize events:
// create window resize stream
// throttle resize events
const resize$ =
Rx.Observable
.fromEvent(window, 'resize')
.throttleTime(350);
// subscribe to the resize$ observable
// log window width x height
const subscription =
resize$.subscribe((event) => {
let t = event.target;
console.log(`${t.innerWidth}px x ${t.innerHeight}px`);
});The example code above shows that as the window size changes, we can throttle the observable stream and subscribe to the changes to respond to new values in the collection. This is an example of a hot observable.
Hot Observables
User interface events like button clicks, mouse movement, etc. are hot. Hot observables will always push even if we're not specifically reacting to them with a subscription. The window resize example above is a hot observable: the resize$ observable fires whether or not subscription exists.
Cold Observables
A cold observable begins pushing only when we subscribe to it. If we subscribe again, it will start over.
Let's create an observable collection of numbers ranging from 1 to 5:
// create source number stream
const source$ = Rx.Observable.range(1, 5);
// subscribe to source$ observable
const subscription = source$.subscribe(
(value) => { console.log(`Next: ${value}`); }, // onNext
(event) => { console.log(`Error: ${event}`); }, // onError
() => { console.log('Completed!'); } // onCompleted
);We can subscribe() to the source$ observable we just created. Upon subscription, the values are sent in sequence to the observer. The onNext callback logs the values: Next: 1, Next: 2, etc. until completion: Completed!. The cold source$ observable we created doesn't push unless we subscribe to it.
Observables Takeaways
Observables are streams. We can observe any stream: from resize events to existing arrays to API responses. We can create observables from almost anything. A promise is an observable with a single emitted value, but observables can return many values over time.
We can operate on observables in many ways. RxJS utilizes numerous operator methods. Observables are often visualized using points on a line, as demonstrated on the RxMarbles site. Since the stream consists of asynchronous events over time, it's easy to conceptualize this in a linear fashion and use such visualizations to understand Rx* operators. For example, the following RxMarbles image illustrates the filter operator:
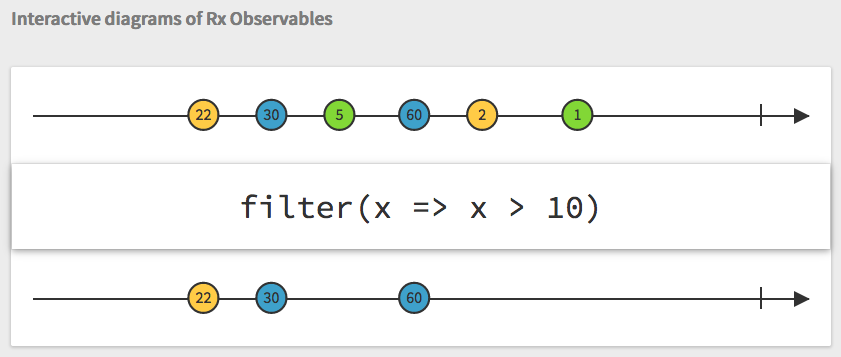
To learn more about observables, check out the following resources:
- Reactive Extensions: Observable
- Creating and Subscribing to Simple Observable Sequences
- The introduction to Reactive Programming you've been missing: Request and Response
- Introducing the Observable
- RxMarbles
- Rx Book - Observable
- Introducing the Observable
Reactive Programming
Reactive programming is concerned with propagating and responding to incoming events over time, declaratively (describing what to do rather than how).
Reactive programming is often associated with Reactive Extensions, an API for asynchronous programming with observable streams. Reactive Extensions (abbreviated Rx*) provides libraries for a variety of languages, including JavaScript (RxJS).
In Practice: Reactive Programming with JavaScript
Here is an example of reactive programming with observables. Let's say we have an input where the user can enter a six-character confirmation code and we want to print out the latest valid code attempt. Our HTML might look like this:
<!-- HTML -->
<input id="confirmation-code" type="text">
<p>
<strong>Valid code attempt:</strong>
<code id="attempted-code"></code>
</p>We'll use RxJS and create a stream of input events to implement our functionality, like so:
// JS
const confCodeInput = document.getElementById('confirmation-code');
const attemptedCode = document.getElementById('attempted-code');
const confCodes$ =
Rx.Observable
.fromEvent(confCodeInput, 'input')
.map(e => e.target.value)
.filter(code => code.length === 6);
const subscription = confCodes$.subscribe(
(value) => attemptedCode.innerText = value,
(event) => { console.warn(`Error: ${event}`); },
() => { console.info('Completed!'); }
);This code can be run at this JSFiddle: Reactive Programming with JavaScript. We'll observe events from the confCodeInput input element. Then we'll use the map operator to get the value from each input event. Next, we'll filter any results that are not six characters so they won't appear in the returned stream. Finally, we'll subscribe to our confCodes$ observable and print out the latest valid confirmation code attempt. Note that this was done in response to events over time, declaratively: this is the crux of reactive programming.
Reactive Programming Takeaways
The reactive programming paradigm involves observing and reacting to events in asynchronous data streams. RxJS is used in Angular and is gaining popularity as a JavaScript solution for reactive programming.
To learn more about reactive programming, check out the following resources:
- The introduction to Reactive Programming you've been missing
- Introduction to Rx
- The Reactive Manifesto
- Understanding Reactive Programming and RxJS
- Reactive Programming
- Modernization of Reactivity
- Reactive-Extensions RxJS API Core
Functional Reactive Programming
In simple terms, functional reactive programming could be summarized as declaratively responding to events or behaviors over time. To understand the tenets of FRP in more depth, let's take a look at FRP's formulation. Then we'll examine its use in relation to JavaScript.
What is Functional Reactive Programming?
A more complete definition from Conal Elliot, FRP's formulator, would be that functional reactive programming is "denotative and temporally continuous". Elliot mentions that he prefers to describe this programming paradigm as denotative continuous-time programming as opposed to "functional reactive programming".
Functional reactive programming, at its most basic, original definition, has two fundamental properties:
- denotative: the meaning of each function or type is precise, simple, and implementation-independent ("functional" references this)
- continuous time: variables have a particular value for a very short time: between any two points are an infinite number of other points; provides transformation flexibility, efficiency, modularity, and accuracy ("reactive" references this)
Again, when we put it simply: functional reactive programming is programming declaratively with time-varying values.
To understand continuous time / temporal continuity, consider an analogy using vector graphics. Vector graphics have an infinite resolution. Unlike bitmap graphics (discrete resolution), vector graphics scale indefinitely. They never pixellate or become indistinct when particularly large or small the way bitmap graphics do.
"FRP expressions describe entire evolutions of values over time, representing these evolutions directly as first-class values."
—Conal Elliot
Functional reactive programming should be:
- dynamic: can react over time or to input changes
- time-varying: reactive behaviors can change continually while reactive values change discretely
- efficient: minimize amount of processing necessary when inputs change
- historically aware: pure functions map state from a previous point in time to the next point in time; state changes concern the local element and not the global program state
Conal Elliot's slides on the Essence and Origins of FRP can be viewed here. The programming language Haskell lends itself to true FRP due to its functional, pure, and lazy nature. Evan Czaplicki, the creator of Elm, gives a great overview of FRP in his talk Controlling Time and Space: Understanding the Many Formulations of FRP.
In fact, let's talk briefly about Evan Czapliki's Elm. Elm is a functional, typed language for building web applications. It compiles to JavaScript, CSS, and HTML. The Elm Architecture was the inspiration for the Redux state container for JS apps. Elm was originally considered a true functional reactive programming language, but as of version 0.17, it implemented subscriptions instead of signals in the interest of making the language easier to learn and use. In doing so, Elm bid farewell to FRP.
In Practice: Functional Reactive Programming and JavaScript
The traditional definition of FRP can be difficult to grasp, especially for developers who don't have experience with languages like Haskell or Elm. However, the term has come up more frequently in the front-end ecosystem, so let's shed some light on its application in JavaScript.
In order to reconcile what you may have read about FRP in JS, it's important to understand that Rx*, Bacon.js, Angular, and others are not consistent with the two primary fundamentals of Conal Elliot's definition of FRP. Elliot states that Rx* and Bacon.js are not FRP. Instead, they are "compositional event systems inspired by FRP".
Functional reactive programming, as it relates specifically to JavaScript implementations, refers to programming in a functional style while creating and reacting to streams. This is fairly far from Elliot's original formulation (which specifically excludes streams as a component), but is nevertheless inspired by traditional FRP.
It's also crucial to understand that JavaScript inherently interacts with the user and UI, the DOM, and often a backend. Side effects and imperative code are par for the course, even when taking a functional or functional reactive approach. Without imperative or impure code, a JS web application with a UI wouldn't be much use because it couldn't interact with its environment.
Let's take a look at an example to demonstrate the basic principles of FRP-inspired JavaScript. This sample uses RxJS and prints out mouse movements over a period of ten seconds:
// create a time observable that adds an item every 1 second
// map so resulting stream contains event values
const time$ =
Rx.Observable
.timer(0, 1000)
.timeInterval()
.map(e => e.value);
// create a mouse movement observable
// throttle to every 350ms
// map so resulting stream pushes objects with x and y coordinates
const move$ =
Rx.Observable
.fromEvent(document, 'mousemove')
.throttleTime(350)
.map(e => { return {x: e.clientX, y: e.clientY} });
// merge time + mouse movement streams
// complete after 10 seconds
const source$ =
Rx.Observable
.merge(time$, move$)
.takeUntil(Rx.Observable.timer(10000));
// subscribe to merged source$ observable
// if value is a number, createTimeset()
// if value is a coordinates object, addPoint()
const subscription =
source$.subscribe(
// onNext
(x) => {
if (typeof x === 'number') {
createTimeset(x);
} else {
addPoint(x);
}
},
// onError
(err) => { console.warn('Error:', err); },
// onCompleted
() => { console.info('Completed'); }
);
// add element to DOM to list out points touched in a particular second
function createTimeset(n) {
const elem = document.createElement('div');
const num = n + 1;
elem.id = 't' + num;
elem.innerHTML = `<strong>${num}</strong>: `;
document.body.appendChild(elem);
}
// add points touched to latest time in stream
function addPoint(pointObj) {
// add point to last appended element
const numberElem = document.getElementsByTagName('body')[0].lastChild;
numberElem.innerHTML += ` (${pointObj.x}, ${pointObj.y}) `;
}You can check out this code in action in this JSFiddle: FRP-inspired JavaScript. Run the fiddle and move your mouse over the result area of the screen as it counts up to 10 seconds. You should see mouse coordinates appear along with the counter. This indicates where your mouse was during each 1-second time interval.
Let's briefly discuss this implementation step-by-step.
First, we'll create an observable called time$. This is a timer that adds a value to the collection every 1000ms (every second). We need to map the timer event to extract its value and push it in the resulting stream.
Next, we'll create a move$ observable from the document.mousemove event. Mouse movement is continuous. At any point in the sequence, there are an infinite number of points in between. We'll throttle this so the resulting stream is more manageable. Then we can map the event to return an object with x and y values to represent mouse coordinates.
Next we want to merge the time$ and move$ streams. This is a combining operator. This way we can plot which mouse movements occurred during each time interval. We'll call the resulting observable source$. We'll also limit the source$ observable so that it completes after ten seconds (10000ms).
Now that we have our merged stream of time and movement, we'll create a subscription to the source$ observable so we can react to it. In our onNext callback, we'll check to see if the value is a number or not. If it is, we want to call a function called createTimeset(). If it's a coordinates object, we'll call addPoint(). In the onError and onCompleted callbacks, we'll simply log some information.
Let's look at the createTimeset(n) function. We'll create a new div element for each second interval, label it, and append it to the DOM.
In the addPoint(pointObj) function, we'll print out the latest coordinates in the most recent timeset div. This will associate each set of coordinates with its corresponding time interval. We can now read where the mouse has been over time.
Note: These functions are impure: they have no return value and they also produce side effects. The side effects are DOM manipulations. As mentioned earlier, the JavaScript we need to write for our apps frequently interacts with scope outside its functions.
Functional Reactive Programming Takeaways
FRP encodes actions that react to events using pure functions that map state from a previous point in time to the next point in time. FRP in JavaScript doesn't adhere to the two primary fundamentals of Conal Elliot's FRP, but there is certainly value in abstractions of the original concept. JavaScript relies heavily on side effects and imperative programming, but we can certainly take advantage of the power of FRP concepts to improve our JS.
Finally, consider this quote from the first edition of Eloquent JavaScript (the second edition is available here):
"Fu-Tzu had written a small program that was full of global state and dubious shortcuts. Reading it, a student asked 'You warned us against these techniques, yet I find them in your program. How can this be?'
Fu-Tzu said 'There is no need to fetch a water hose when the house is not on fire.' {This is not to be read as an encouragement of sloppy programming, but rather as a warning against neurotic adherence to rules of thumb.}"
—Marijn Haverbeke, Eloquent JavaScript, 1st Edition, Chapter 6
To learn more about functional reactive programming (FRP), check out the following resources:
- Functional Reactive Programming for Beginners
- The Functional Reactive Misconception
- What is Functional Reactive Programming?
- Haskell - Functional Reactive Programming
- Composing Reactive Animations
- Specification for a functional reactive programming language
- A more elegant specification for FRP
- Functional Reactive Programming for Beginners
- Elm - A Farewell to FRP
- Early inspirations and new directions in functional reactive programming
- Breaking Down FRP
- Rx* is not FRP
Aside: JavaScript use at Auth0
At Auth0 we are heavy users of JavaScript. From our Lock library to our backend, JavaScript powers the core of our operations. We find its asynchronous nature and the low entry barrier for new developers essential to our success. We are eager to see where the language is headed and the impact it will have in its ecosystem.
Sign up for a free Auth0 accountand take a first-hand look at a production ready ecosystem written in JavaScript. And don't worry, we have client libraries for all popular frameworks and platforms!
Auth0 offers a generous free tier to get started with modern authentication.
Recently, we have released a product called Auth0 Extend. This product enable companies to provide to their customers an easy to use extension point that accepts JavaScript code. With Auth0 Extend, customers can create custom business rules, scheduled jobs, or connect to the ecosystem by integrating with other SaaS systems, like Marketo, Salesforce, and Concur. All using plain JavaScript and NPM modules.
Conclusion
We'll conclude with another excellent quote from the first edition of Eloquent JavaScript:
"A student had been sitting motionless behind his computer for hours, frowning darkly. He was trying to write a beautiful solution to a difficult problem, but could not find the right approach. Fu-Tzu hit him on the back of his head and shouted 'Type something!' The student started writing an ugly solution. After he had finished, he suddenly understood the beautiful solution."
—Marijn Haverbeke, Eloquent JavaScript, 1st Edition, Chapter 6
The concepts necessary for understanding functional programming, reactive programming, and functional reactive programming can be difficult to grasp, let alone master. Writing code that takes advantage of a paradigm's fundamentals is the initial step, even if it isn't entirely faithful at first. Practice illuminates the path ahead and also reveals potential revisions.
With this glossary as a starting point, you can begin taking advantage of these concepts and programming paradigms to increase your JavaScript expertise. If anything is still unclear regarding these topics, please consult the links in each section for additional resources. We'll cover more concepts in the next Modern JS Glossary post!


