



OAuth 2 Core does not say what an access token (AT) should look like, only what it should be used for. Left to their own devices, the most important OAuth-based services and products chose to encode access tokens as JWTs. Without guidance from standards, however, they ended up producing as many incompatible variants.
This article is the story of how this issue bugged me so much that I took it on myself to work with the IETF standards community to try fixing it, culminating in the publication of a new standard document describing how to encode and validate an OAuth 2.0 AT in JWT format.
I am taking this opportunity to give you a glimpse of how the standardization process works, but most importantly: I hope this will show you that today anyone has the power to contribute to the community.
Preamble: Why Are Issuers Encoding Access Tokens as JWTs?
In the first version of OAuth, the access token issuer and the resource-consuming it (service provider and the protected resource, respectively, in OAuth 1 parlance) were co-located: the consumer (old name for client) would request an access token from https://photos.example.net/access\_token?.. and use it to access the resource at http://photos.example.net/photo?...
OAuth 2 introduced better role separation, making it possible for the authorization server (AS) and resource server (RS) to live on different domains and be run by different owners. However, the scenario where AS and RS live together was still the quintessential use case, think Google issuing tokens to protect Google APIs.
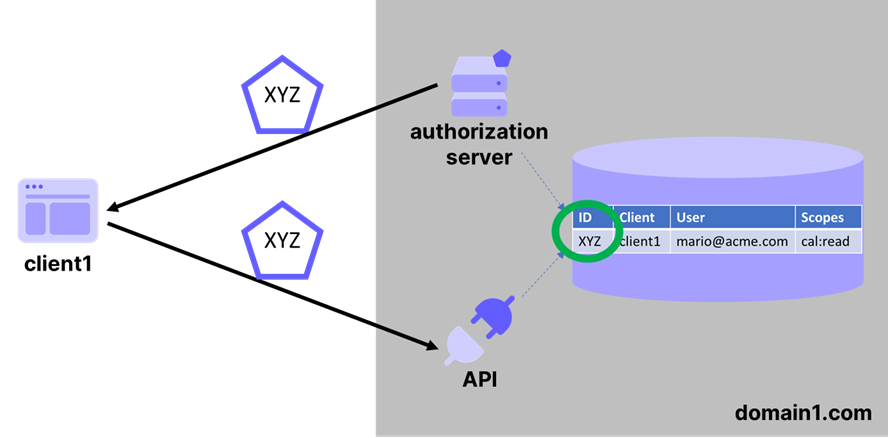
When the token issuer and token consumer are essentially the same entity, validating tokens is an easy problem (see Figure 1). Say that a client asks and obtains delegated authorization to read your Google Calendar. At authorization request time, Google can write somewhere in its backend that you granted consent for that client, and return as AT the ID of the row where it recorded your preference. When the client wants to access the calendar, it just presents the AT to the API: the API turns around, looks up the ID in the DB it shares with the AS, and consults the record to decide whether to grant access. This is definitely oversimplified (and I have no insight on how google really does things, I just picked a relatable example) but should give a rough idea.
This trick clearly doesn’t work if the AS and RS are separate and don’t share any common state (figure 2). Just like it’s common for web apps to outsource authentication to a separate entity, it’s common for API to integrate with 3rd party services (such as IDaaS, local IdP software, etc) running elsewhere. And of course, APIs can be deployed anywhere (Lambda, Azure Functions, etc). The case in which AS and RS are separate is completely mainstream nowadays.
Imagine you are such an API. A caller sends you a request, including an AT allegedly indicating that they should be authorized to perform that request. Strictly adhering to the core spec, the AT is just an opaque blob. How are you going to determine whether you should serve the request?
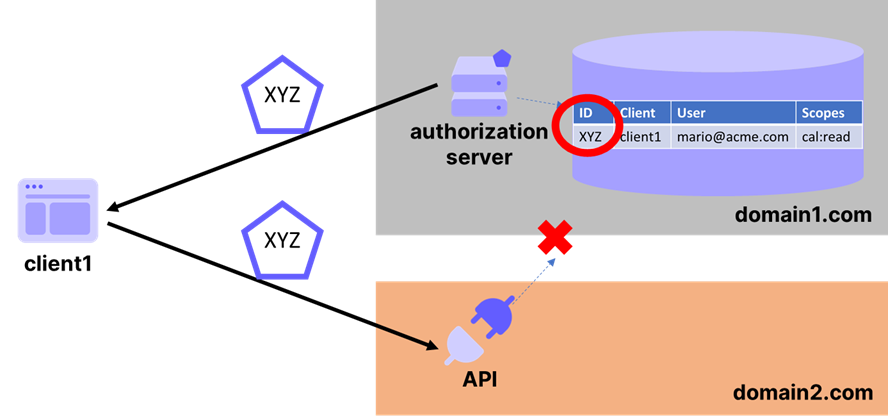
Absent the luxury of shared state with the AS, you mostly have two alternatives: calling back the AS asking for help, or trying to make that determination by looking at the AT content. Neither approach were included in the core OAuth 2 specification.
- The “calling back the AS asking for help” route is known as introspection. The idea is that your API can open a direct SSL channel with the AS, present the AT and find out whether the token is valid, what relevant information it contains/refers to, and so on.
That’s a perfectly valid method, which has the advantage of immediately reflecting the revocation state of a token. It does however come with some tradeoffs: doing network IO from the API every time it gets a token is expensive, and puts network latency/failures/throttling risks on the API critical path. It’s expensive for the AS, too. - The “looking at the AT content” route is just an extension of what other boundary-crossing protocols have been doing for decades. If AS and the RS/API can agree on a format for encoding ATs, and associated validation methods, the API can now independently validate the incoming AT, without depending on network performance, AS availability, throttling, and so on. This approach is extraordinarily popular, adopted by hyperscale IDaaS and nimble SDKs alike.
That hopefully clarifies why it’s handy to use a format for ATs. Why JWT in particular? I believe that’s because most AS also implement OpenID Connect, hence already needed to use the JWT format to issue ID tokens. Same deal on the consumer side: lots of OpenID Connect SDKs relying on lower-level components implementing JWT, at the ready to be used in APIs.
Whatever the reason, everywhere I looked I saw products and companies issuing ATs as JWTs: and that’s where our story begins.
Framing the Problem: JWT, JWT ATs Everywhere
Throughout my years of tenure at Microsoft, I have consistently seen API calls secured using tokens in a known format, JWT in particular. I helped many product teams build features predicated on that, and hundreds of customers to achieve their goals via architectures that included encoding access tokens as JWTs. Doing so wasn’t against any standards, it just didn’t benefit from standard guidance. All the practices and implementation decisions had to be derived from the concrete experience of running solutions predicated on that approach.
When I moved to Auth0, I found the approach used to secure the customer’s API to be very similar to the one I was already used to. Two hyperscale services, handling API authorization in the same way… make you think, doesn’t it?
And yet, there were small differences- details that made reusing exactly the same SDKs to handle the two different JWT ATs impossible. For example, Azure AD placed the scopes granted to the client in a claim called scp, whereas Auth0 used a claim called scope. Exact same functionality, but incompatible formats for a pure matter of formatting. Makes you think some more! If other well-adopted vendors are using JWT to encode ATs, and are all mostly sending the same info with some minor syntactic differences, perhaps devising a common profile might be a good thing! It was a hypothesis worth investigating.
In March 2019 I reached out to friends and contacts working at key providers I knew were using JWT as AT format. I explained my hypothesis and asked if they’d share with me sample ATs.
I got answers and samples from Dominick Baier (IdentityServer), Brian Campbell (PingIdentity), Daniel Dobalian (Microsoft), Karl McGuinness (Okta- this was years before the merger news) and I of course sourced Auth0 ATs myself. For good measure, I threw in JWT ATs from AWS as extracted from their public documentation.
Putting all the AT claims in a table, I found more similarities than differences.
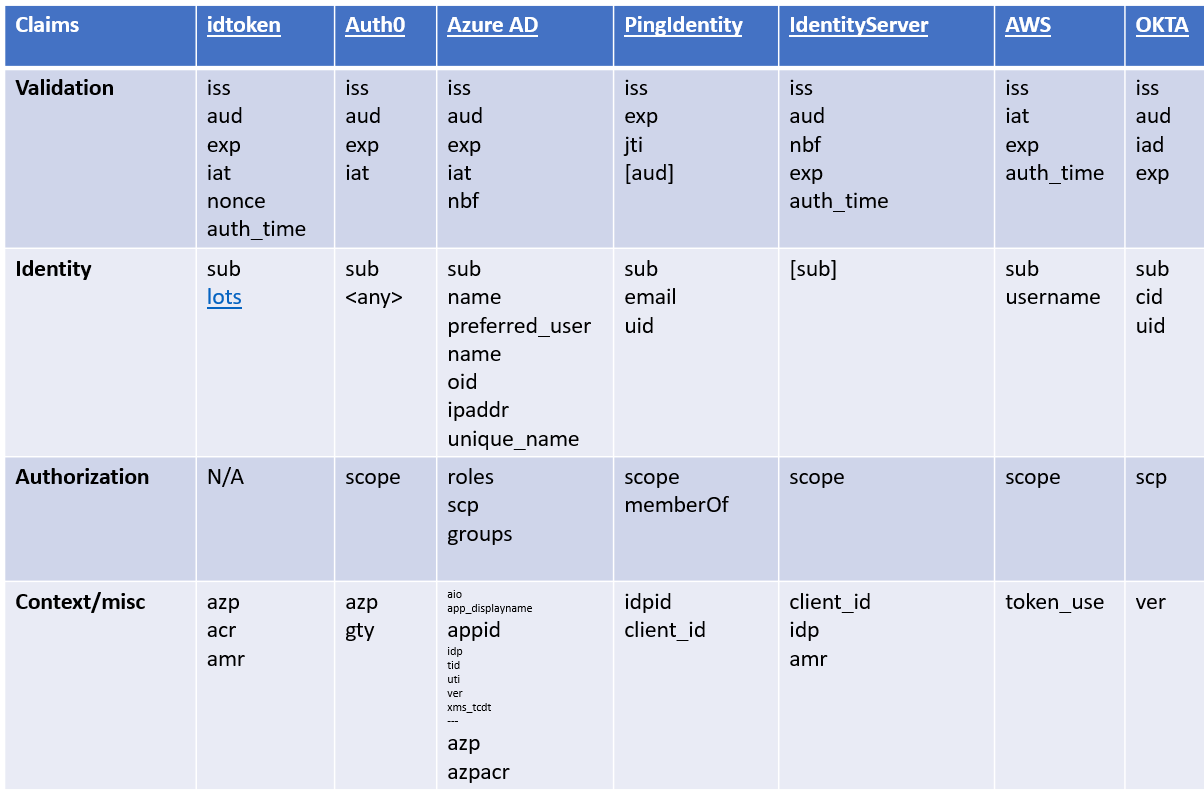
I found that the claims could be roughly classified into 4 categories:
- Validation. Structural claims used to validate the token, largely echoing the ones defined by OpenID Connect for IDTokens
- Identity. Contrary to popular belief, which insists on ATs being exclusively (delegated) authorization constructs, nearly everyone included identity attributes (and the one instance who didn’t, allowed them as optional)
- Authorization. Besides the scope claim, present in all samples albeit in varying formats, various providers allowed the inclusion of other classic authorization artifacts (groups, roles)
- Context/misc. A loose category carrying miscellaneous information, with some common elements like client identifiers and authentication methods info.
This further confirmed my hypothesis that everyone was roughly pursuing the same goals and using the same attributes, but just happened to use a different syntax for pure happenstance.
To me that was interesting evidence that deserved being shared with the OAuth community. Luckily, there was just the right forum coming up: the OAuth Security Workshop.
Probing Interest: the Stuttgart Pitch

In late March 2019, I flew to Stuttgart, Germany, to attend the OAuth Security Workshop. It is a fantastic conference, a watering hole toward which the most brilliant (and generous) experts in the OAuth community converge once a year. That made it the absolute ideal place and time to explore whether others saw the problem and the opportunity.
I grabbed a one-hour slot and presented my research. You can still find the deck I used here.
I got a lot of nodding, the room definitely already knew what I was talking about: the data I presented was consistent with their experience. I did one more session on the topic, this time focusing on what an interop profile could look like, and got tons of enthusiastic contributions to it. The interest was there: it was time to get serious about starting formal work on the problem.
The IETF was going to meet just a few days later for IETF104: the OAuth chairs were open to let me put this in front of the working group via remote presentation, but in order to do that I had to jot down my proposal as an "individual draft" (see below). That’s where I started to realize just how much process I was going to have to deal with!
From Individual Draft to Working Group Adoption: IETF 104
Have you ever seen an RFC? They live at addresses like https://datatracker.ietf.org/doc/html/rfc9068 and have a characteristic look (tho they can be visualized in many formats).
As it turns out, documents that eventually become RFCs usually start their life as an individual draft, containing an initial proposal of an author on how to tackle something that, in the author’s opinion, deserves to become formal guidance. That is a document that must be authored in a very specific format and must be submitted using the tooling and processes that the IETF provides (and enforces). The result is something that looks very similar to an RFC, as it looks the same and lives on the IETF pages, but that at this stage has no formal weight whatsoever. For a funny example, check this out (and this one, too).
Nonetheless, an individual draft was what I had to produce in order to even suggest the idea to the IETF meeting. I had to do it FAST, likely while on the plane back from Germany. And I had to do it right, given that anything incorrectly formatted would have been rejected by the uploading tools.
I took a look at the official guidance here, and it was just overwhelming. Luckily, the identity community is full of good people who are generous with their time. My good friend Brian Campbell was incredibly helpful, leading me through the labyrinth of tools, options, and templates, helping me to troubleshoot when things broke down, and in general, making it possible for me to produce a draft on time for the presentation.
As is the case for all things IETF, where the story of everything is pretty much always available, you can still find that first individual draft at https://datatracker.ietf.org/doc/html/draft-bertocci-oauth-access-token-jwt. At that point that was just my own thoughts, not reflecting any working group discussion. A true individual draft. The secret to recognizing those is to look at the name of the file. If it’s of the form draft-< lastname >-*, it’s just the opinion of the author- nothing more.
Once I uploaded the draft, an automated mail informed the OAuth WG mailing list of its existence and location. Shortly after, I gave my presentation at the IETF104 conference: you can find the rather terse minutes here. It was well-received there, too, but the real test came a few days after the conference. The working group chairs sent a message to the mailing list, issuing what is known as a call for adoption: the group members are asked to share whether they accept or object to the adoption of the draft document as a starting point for work in the OAuth working group. To my delight, the support for the adoption was strong- no one objected, and the motion passed. I re-submitted the draft, which changed into https://datatracker.ietf.org/doc/html/draft-ietf-oauth-access-token-jwt-00. That’s another stage of our pokemon here: from the individual draft, the document turned into an internet draft. When you see a document whose name is in the form draft-ietf-*[-< digits >], you know it’s a document that is being worked on by a working group. That is NOT yet a standard, it is still very likely to change, but already received some degree of scrutiny (at the very least, it successfully went through a call for adoption as a work item).
That was when the REAL fun began.
The Working Group Discussion
The raison d’etre of this work was that one important area of OAuth was left underspecified, so I was strongly motivated to swing the pendulum in the other direction and generate truly actionable guidance that would help developers achieve an end to end interop in no uncertain terms. That meant going beyond just defining the layout of an AT encoded as a JWT, but also defining how the authorization server should take request parameters into account when populating ATs, and providing clear guidance about how resource servers should validate JWT ATs. On top of that, there were years of lessons learned in terms of security and privacy practices that had to be codified in the spec recommendations. All noble goals! As I was about to discover, however, the cost of consensus doesn’t grow linearly with the amount of stuff a group needs to agree on: if it’s not exponential, it’s pretty darn close.
I contributed to the discussion on the working group many times before, but this was the first time I felt responsible to ensure things moved forward and in the right way. No more bystander effect!
I don’t want to bore you with a detailed chronicle of how the discussion went, but just give you a feel of what the process looks like. In broad strokes, it was something along the lines of
- Send to the mailing list a writeup about some detail of the document, proposing something or seeking opinions: whether a certain claim should be optional or mandatory, whether a certain recommendation should be included in the security considerations, and so on. At times, someone else will do this- asking a question about the document, sharing an opinion.
- Actively engage in the discussion, soliciting points of view, asking for clarifications, summarizing to steer toward consensus or uncover remaining disagreements, spawn separate threads when necessary, facilitate closure when things don’t seem to converge on their own
- Reflect the outcome of the conversations in the draft and upload new versions
- At key milestones (IETF F2F events, conferences, etc) present to the group in high bandwidth settings, bringing up issues that are hard to close in email form
- Repeat as many times as it is necessary to reach a form that enjoys widespread consensus, no longer generates disagreements
I found all of the above a challenging, humbling, and profoundly formative experience.
One of the most important lessons I got was that I didn't know nearly as much as I thought on the topic. After years of hands-on experience using JWT ATs with many customers in the most diverse circumstances, I thought the bulk of the work was going to be putting down that experience in spec form. Goodness was I wrong. I think I did supply a solid starting point, but I was absolutely blown away by the diversity of viewpoints, goals, scenarios, and ways to look at the problem that were just as valid and backed by concrete experience as mine. The working group sports some really, really smart members. Luckily I was fully committed to identifying the right guidance and channel consensus rather than “being right”, so I genuinely enjoyed learning those things - even when they required some reframing.
Extracting the insight was not always easy. Not everyone follows the discussion closely (we all have day jobs) so it wasn’t uncommon for someone to comment on something that has been already discussed, often presenting the same arguments - to which I had to either summarize the outcome of the discussion and/or provide pointers to the relevant threads in the mail archive, hoping they would read it before diving further. Of course that occasionally caused people unsatisfied with the outcome of the former discussion to give it another shot, relitigating issues large and small in what at times felt like a Sisyphean task. I remember the chill in my spine when during the QA of my presentation at an in-person IETF meeting, someone walked up to the microphone and opened with “I didn’t read the specification or follow the discussion, but here there’s my take on this…” :D that caused an avalanche of comments along those lines, largely repeating a discussion that already occurred on the mailing list, and ate all the precious face time I had. ARGH :D
For a while, it looked like most of the work was on tracking down, digesting, and curating context and content to ensure that the opinions being shared were well informed rather than the result of incomplete understanding. Throw in the mix the occasional individual pursuing their own agenda regardless of what spec is being discussed, and you get the picture. Ultimately, things always worked out in a way or another- but it was HARD. I admit that for a while seeing new messages appear in the OAUTH WG folder in my inbox caused me little anxiety spikes :’)
But, as I said- formative experience. I developed a stoic stance toward the endeavor, resolving to do my best without expecting fast progress. There was incredible insight being shared in the discussion, and even if the process felt at times painful, I had faith in its ability to eventually distill the collective wisdom.
The Last Stretch: Last Calls, IESG, RFC Editor
Working Group Last Call(s)
At a certain point in the process, the working group chairs establish that the draft is close enough to completion, and issue what it’s known as a working group last call (WGLC): it basically says that if by a certain date no one had anything of substance to discuss, the draft will move to the next stage. My spec went through not one, but THREE WGLCs.
The first one, issued on March 23, 2020, and ending on April 6, 2020, generated LOTS of comments from many people, on fundamental matters.
The second, from 4/15 to 4/29, got less substantive traffic but still useful observations. It also got WAY more drama than I would have ever expected to witness in the process of developing a standard, but there’s no point rehashing any of that here. The mailing list records are public, and you can always catch me at some conference to get a TL;DR- especially if I have an adult beverage in my hands.
The third one, from 5/5 to 5/12, was meant to be the last, last… but in fact, the next stage didn’t really start in earnest until January 2021.
The IESG
The next stage is a review from the IESG, a group of experts (area directors) with scope beyond OAuth that will give very detailed commentary and formally vote whether to move the doc forward or if they need to get further clarifications.
In order to pass the buck to IESG, the working group chair has to produce a “shepherd writeup”- basically a backgrounder preempting a fixed series of questions about the specification, from the standard track the document is in, to whether all the intellectual properties considerations have been cleared. Mine was authored and submitted in October 2020 by the always excellent Hannes Tschofenig, you can find it here.
One particularly interesting aspect the shepherd writeup needs to cover is whether there are already implementations of the draft in actual products- I was delighted to discover that there were already FOUR products offering support for the profile! There was IdentityServer, Filip Skokan’s Node OIDC library, ConnectID, Glewlwyd OIDC plugin... That placed a huge smile on my face.
The IESG review went very smoothly. As expected, some of the questions were repeats of things already discussed; others were brand new, and very insightful. And there were LOTS of them, it was a thorough combing. What made it go smoothly was that every reviewer was familiar with the process, paid very close attention to the replies, and relentlessly drove toward resolution. I was pretty worried about that phase, but it turned out to be one of the best parts of this experience.
RFC Editor and Publication
After their approval, the last stage (I am skipping some stuff here, notably the IANA parts pertaining to the registration of new media and claim types the spec defines) was the RFC editor- an extraordinarily thorough editorial review, for some reason (and confusingly, for identity people) called AUTH48, where the author is asked to review every proposed edit (all good edits that enhance clarity). Once that’s done, the document receives a number and becomes an official IETF standard, assuming the characteristic https://datatracker.ietf.org/doc/html/rfc9068 form.
The publication happened during the AuthenticateCon/FIDO plenary conference - that made me miss the magical window for tweeting about it (Mike did the honors) but it also created the awesome opportunity to celebrate on that very evening with many of my identity friends, also in town for the conference.
Where to Go from Here
Our brief tour de force showed us how it really is possible to go from an idea, a pet peeve to an official standard. Even better, if you exclude the time I and the other WG members offered when working on this, and the occasional trip to in-person IETF events, this was substantially free - no hefty corporate membership required. The rational question you should ask, dear reader, is: was it worth it?
After all this brouhaha to make the JWT profile a standard, everyone’s going to drop what they’re doing and change their existing JWT encoding logic for ATs to comply with the profile, right? ...right?
Not likely. What companies have today, my starting point, already works for their scenarios. Moreover, their customers are taking at least some degree of dependency on it. The incentive for a wholesale swap isn’t strong. But frankly, it was never the main point of standardizing this. Describing what a JWT AT would look like in the platonic ideal scenario gave the working group a chance to provide guidance on the security and privacy implications of using a JWT (and, more generally, a parseable format) for encoding ATs. That’s guidance that can be successfully applied to existing solutions, without having to fully commit to the profile in its entirety. Furthermore, the profile provides an authoritative reference for important functionality ATs are expected to perform: if all existing implementations pick up from rfc9068 is what claim type and format to use to transmit scopes, opening the way for SDKs to offer scope based policies reliably applicable to multiple vendors, that alone would be worth the effort of pushing this heavy boulder to completion.
And of course, new SDK work will hopefully build on the guidance. There are already products supporting the profile: besides the four products I listed earlier in this post, Auth0’s very own Node JS API middleware offers a strict option that will enforce the profile.
To me, that makes all the effort absolutely worth it. The process might be at times frustrating, maddeningly slow… but it is open, thorough, and effective. It’s not perfect and it doesn’t yield perfect results, but it’s pretty much the best we have today. I feel grateful to have had (and have) the chance to contribute. I am constantly amazed at the generosity of so many world-class identity experts freely offering their insights: besides the chance of steering the community in the right direction, all they can hope for is an entry in the spec’s acknowledgment section, with a non zero chance to have their names misspelled.
I hope this was more inspiring than discouraging. If you are interested in contributing to the IETF standards work, please always feel free to reach out at twitter.com/vibronet: I received so much help that I don’t think I’ll ever be able to pay it back. Your experience and scenarios are important, and I assure you many people are eager to hear about them!
Thanks to Aaron Parecki for his thorough review and feedback on this article!


