---
title: " AIエージェントには2つの魂がある。制御できるのは1つだけ"
description: "LLMそのものよりもLLM周辺のコードが重要である理由。AIエージェントのセキュリティに対する考え方を変えたアーキテクチャの洞察。"
authors:
- name: "Andrea Chiarelli"
url: "https://auth0.com/blog/authors/andrea-chiarelli/"
date: "May 8, 2026"
category: "AI"
tags: ["ai agent", "ai"]
url: "https://auth0.com/blog/jp-ai-agents-have-two-souls-you-control-only-one/"
---
# AIエージェントには2つの魂がある。制御できるのは1つだけ
>本記事は「[AI Agents Have Two Souls. You Only Control One.](https://auth0.com/blog/ai-agents-have-two-souls-you-control-only-one/)」を翻訳した記事です。
現在、誰もがAIエージェントを構築しているようです。しかし、10人の開発者にAIエージェントとは実際に何であるかを尋ねると、10通りの異なる答えが返ってきます。ツールにアクセスできるLLMであると言う人もいます。自律的に行動を起こす能力によって定義する人もいます。既存のチャットボットを指してエージェントと呼ぶ人もいます。
定義の曖昧さは単なる学術的な問題ではありません。セキュリティ上の問題につながります。正確に説明できないシステムをどのように保護できるでしょうか。
## AIエージェントの定義を探る
意思決定における自律性のレベルを強調する一般的な定義を超えて、好ましいと考える少し技術的な定義を指摘します。[Microsoft](https://learn.microsoft.com/en-us/azure/cloud-adoption-framework/ai-agents/#what-is-an-ai-agent)によるものであり、[OWASPの定義](https://genai.owasp.org/glossary/)とかなり一致しているようです。
"*AIエージェントは、生成AIモデルを使用して入力を解釈し、\[...\]問題を推論し、最も適切なアクションを決定する柔軟なソフトウェアプログラムです。\[...\]エージェントは5つのコアコンポーネントに基づいて構築されています。*
* _ **生成AIモデル**はエージェントの推論エンジンとして機能します。命令を処理し、ツール呼び出しを統合し、他のエージェントへのメッセージまたは実行可能な結果として出力を生成します。_
* **命令**はエージェントの範囲、境界、および行動ガイドラインを定義します。明確な命令はスコープクリープを防ぎ、エージェントがビジネスルールを遵守することを保証します。*
* _ **検索**は正確な応答に必要なグラウンディングデータとコンテキストを提供します。関連性の高い高品質なデータへのアクセスは、ハルシネーションを減らし、関連性を確保するために不可欠です。_
* _ **アクション**はエージェントがタスクを実行するために使用する関数、API、またはシステムです。ツールはエージェントを受動的な情報検索者からビジネスプロセスへの能動的な参加者に変えます。_
* _ **メモリ**は会話の履歴と状態を保存します。メモリは対話全体での継続性を確保し、エージェントがマルチターン会話や長期実行タスクを効果的に処理できるようにします。_"
エージェントは固定ルールに基づく従来のアプリケーションとは異なります。リアルタイムのコンテキストに応じてワークフローを動的にオーケストレーションすることで、エージェントは従来のソフトウェアの能力を超える曖昧さと複雑さを管理できる適応性を獲得します。
定義を以下の図に視覚化できます。
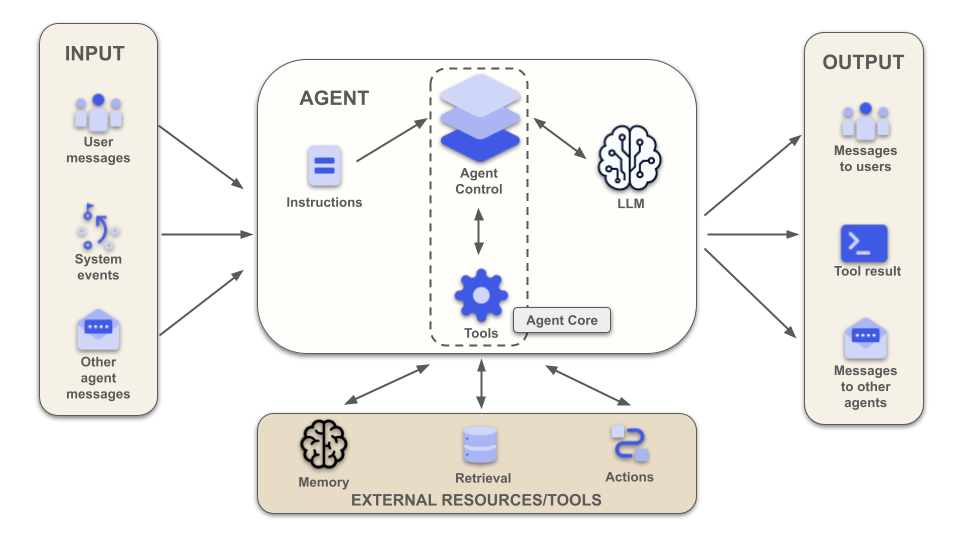 入力、出力、および外部リソースは別として、AIエージェントの中心となるのは命令のコレクション、LLM、およびAgent Coreです。
LLMは知っての通りエージェントの頭脳であり、必要な推論を実行して意思決定するコンポーネントです。Agent CoreはLLMと外界との相互作用をオーケストレーションするソフトウェアコンポーネントです。Agent CoreはLLMと相互作用するPython、JavaScript、C#などのアプリケーション内のコードです。
Agent Core内でAgent ControlとToolsの2つのコンポーネントを強調しました。Agent Controlはエージェントの中心であり、LLMと外界とのすべての相互作用を調整する部分です。Toolsコンポーネントは計算機能やファイルシステムアクセスなど、LLMが利用できるすべての機能を表します。Toolsコンポーネントは外部ツールやリソースへのインターフェースでもあります。Agent ControlとToolsコンポーネントの組み合わせによってAgent Coreが構築されます。インテリジェントな機能を持たない、単なる昔ながらのコードです。
図を見ると2つの興味深い点に気づきます。
* AIエージェントの真の2つのコンポーネントは、決定論的であるAgent Coreと、決定論的ではないLLMです。
* Agent CoreはLLMと相互作用する唯一のコンポーネントです。
2つの単純な観察結果は、AIエージェントの性質と保護方法を理解するための基礎となります。
## AIエージェントの2つの魂
最初の観察結果は、AIエージェントの2つのコアコンポーネントが従来の決定論的アプリケーションと決定論的ではないLLMであることを強調しています。
Agent Coreは決定論的なコードを実行することで、LLMに入力を送信し、機能を提供し、出力を処理します。分析やテストが可能であり、動作原理を理解し、特定の入力に対して常に同じ出力が得られることを把握できます。
LLMモデルは異なる性質を持っています。決定論的ではありません。2つの異なる機会に同じ入力が与えられた場合、生成AIモデルは異なる出力を生成する可能性があります。予期しない方向に推論し、曖昧な命令を予期しない方法で解釈し、構築した人々でさえ驚くような方法でコンテキストから情報を組み合わせられます。LLMの力であると同時に問題でもあります。
>LLMが**決定論的ではないと言うことは、非決定論的であると言うことと同じではありません**。一般的にLLMは非決定論的であると考えられていますが、計算の観点からは正しくありません。[LLMが非決定論的ではない理由については本記事を確認ください](https://theturingmachine.net/generative-ai-and-non-determinism)。
したがって、AIエージェントのアーキテクチャにおいて、**決定論的な魂**(Agent Core)と**確率論的な魂**(LLM)と呼ぶ2つの魂を特定できます。
>哲学の愛好家であれば、人間の魂の二面性への言及に気づくかもしれません。[プラトンの有翼の馬車の神話](https://en.wikipedia.org/wiki/Phaedrus_(dialogue)#Chariot_allegory)から[アウグスティヌス](https://en.wikipedia.org/wiki/Augustine_of_Hippo)の2つの意志、ニーチェの[アポロン的とディオニュソス的の概念](https://en.wikipedia.org/wiki/Apollonian_and_Dionysian)の区別に至るまでです。
入力、出力、および外部リソースは別として、AIエージェントの中心となるのは命令のコレクション、LLM、およびAgent Coreです。
LLMは知っての通りエージェントの頭脳であり、必要な推論を実行して意思決定するコンポーネントです。Agent CoreはLLMと外界との相互作用をオーケストレーションするソフトウェアコンポーネントです。Agent CoreはLLMと相互作用するPython、JavaScript、C#などのアプリケーション内のコードです。
Agent Core内でAgent ControlとToolsの2つのコンポーネントを強調しました。Agent Controlはエージェントの中心であり、LLMと外界とのすべての相互作用を調整する部分です。Toolsコンポーネントは計算機能やファイルシステムアクセスなど、LLMが利用できるすべての機能を表します。Toolsコンポーネントは外部ツールやリソースへのインターフェースでもあります。Agent ControlとToolsコンポーネントの組み合わせによってAgent Coreが構築されます。インテリジェントな機能を持たない、単なる昔ながらのコードです。
図を見ると2つの興味深い点に気づきます。
* AIエージェントの真の2つのコンポーネントは、決定論的であるAgent Coreと、決定論的ではないLLMです。
* Agent CoreはLLMと相互作用する唯一のコンポーネントです。
2つの単純な観察結果は、AIエージェントの性質と保護方法を理解するための基礎となります。
## AIエージェントの2つの魂
最初の観察結果は、AIエージェントの2つのコアコンポーネントが従来の決定論的アプリケーションと決定論的ではないLLMであることを強調しています。
Agent Coreは決定論的なコードを実行することで、LLMに入力を送信し、機能を提供し、出力を処理します。分析やテストが可能であり、動作原理を理解し、特定の入力に対して常に同じ出力が得られることを把握できます。
LLMモデルは異なる性質を持っています。決定論的ではありません。2つの異なる機会に同じ入力が与えられた場合、生成AIモデルは異なる出力を生成する可能性があります。予期しない方向に推論し、曖昧な命令を予期しない方法で解釈し、構築した人々でさえ驚くような方法でコンテキストから情報を組み合わせられます。LLMの力であると同時に問題でもあります。
>LLMが**決定論的ではないと言うことは、非決定論的であると言うことと同じではありません**。一般的にLLMは非決定論的であると考えられていますが、計算の観点からは正しくありません。[LLMが非決定論的ではない理由については本記事を確認ください](https://theturingmachine.net/generative-ai-and-non-determinism)。
したがって、AIエージェントのアーキテクチャにおいて、**決定論的な魂**(Agent Core)と**確率論的な魂**(LLM)と呼ぶ2つの魂を特定できます。
>哲学の愛好家であれば、人間の魂の二面性への言及に気づくかもしれません。[プラトンの有翼の馬車の神話](https://en.wikipedia.org/wiki/Phaedrus_(dialogue)#Chariot_allegory)から[アウグスティヌス](https://en.wikipedia.org/wiki/Augustine_of_Hippo)の2つの意志、ニーチェの[アポロン的とディオニュソス的の概念](https://en.wikipedia.org/wiki/Apollonian_and_Dionysian)の区別に至るまでです。
緊張関係は同じです。一方は制御され、もう一方は野生です。そして野生のものがすべての注目を集めます。
従来のソフトウェアセキュリティはほぼ完全に決定論の仮定に基づいて構築されています。有効な入力を把握し、期待される出力を把握し、エッジケースを網羅的にテストできます。*AIエージェントは仮定を打ち砕きます*。確率論的な魂は、どのテストスイートでも完全にカバーできない動作のカテゴリを導入します。
セキュリティへの影響は直接的です。モデル自体を保護できません。できることは、**確率論的な魂が到達できる範囲を制限するように決定論的な魂を設計する**ことです。
## 適用されるAIセキュリティの3原則
以前、[AIセキュリティの3原則に関する記事](https://auth0.com/blog/three-laws-ai-security/)を執筆しました。アシモフのロボット工学三原則を言い換え、AIの決定論的ではない部分を制御するための同様の原則を定義しました。本記事で分析した内容と同様に、安全なAIアプリケーションを構築する際の根本的な問題は、決定論的なソフトウェアで慣れ親しんできた[制御の喪失](https://auth0.com/blog/three-laws-ai-security/#The-Control-Problem-with-AI)であると観察しました。
これまでの議論に基づくと、AIエージェントのアーキテクチャには、意思決定を行い決定論的ではないコンポーネント(LLM)と、決定論的な方法で命令を実行するコンポーネント(Agent Core)が存在すると言えます。
逆説的ですが、意思決定部分は制御の及ばないところにあります。決定論的ではなく、期待する決定を下すかどうかを確実に予測するツールはありません。
しかし、シナリオにおいて重要なことを1つ忘れています。*意思決定するのはLLMだけではありません*。Agent Coreも意思決定できます。それだけではありません。先ほどの2番目の観察結果は、Agent CoreがLLMと相互作用する唯一のコンポーネントであることを示しています。ユーザー、他のエージェント、外部ツール、およびリソースからのすべての入力は、LLMに渡される前にAgent Coreによってフィルタリングされます。ユーザー、他のエージェント、外部ツール、およびリソースへのすべての出力は、Agent Coreを経由します。**LLMは外界と直接相互作用できません**。セキュリティの観点からは素晴らしいことです。
AIエージェントの魂に基づくアーキテクチャに各原則を適用する方法を見てみましょう。
## データ制御の原則
第1の原則はデータの制御を獲得することに関するものです。次のように述べています。
*AIエージェントは委託されたすべてのデータを保護しなければならず、作為または不作為によって、データを許可されていないユーザーに公開してはなりません。*
原則をAIエージェントのアーキテクチャの観点から言い換えると、ユーザーの代理として行動する場合、**確率論的な魂はユーザーがアクセスを認可されていないデータに決してアクセスしてはならない**と言えます。
原則を実装するには、LLMおよびユーザーや他のエージェントに送信されるすべてのデータをAgent Coreが制御できるようにします。プライベートデータがプライベートに保たれるようにします。LLM、ユーザー、または他のエージェントに送信する前にデータをフィルタリングします。ユースケースに応じてアクセス制御を適用します。
データ制御の必要性の典型的な例は、RAGシステムなどの検索アルゴリズムの実装にあります。ベクトルデータベースなどの外部データソースを使用してエージェントの知識を特化させ、ユーザーが認可されていないデータにアクセスするのを防ぎたいと考えます。
**エージェントの決定論的な魂には、LLMに渡す前にデータをフィルタリングする責任があります**。フィルタがない場合、「ドキュメントを要約して」と要求したユーザーが、誤って他のユーザーのドキュメントを受け取る可能性があります。LLM自体が決して捕捉できないデータ漏洩です。
RAGシステムにデータ制御の原則を実装する方法については、以下のブログ記事を確認ください。
* [Building a Secure RAG with Python, LangChain, and OpenFGA](https://auth0.com/blog/building-a-secure-rag-with-python-langchain-and-openfga/)
* [Secure Java AI Agents: Authorization for RAG Using LangChain4j and Auth0 FGA](https://auth0.com/blog/genai-langchain4j-java-openfga-rag/)
* [Secure a .NET RAG System with Auth0 FGA](https://auth0.com/blog/secure-dotnet-rag-system-with-auth0-fga/)
* [Build a Secure RAG Agent Using LlamaIndex and Auth0 FGA on Node.js](https://auth0.com/blog/genai-llamaindex-js-fga/)
## コマンド制御の原則
第2の原則はコマンドフローを制御し、AIエージェントが求められたタスクを確実に実行することに焦点を当てています。それ以上のことはしません。原則は次のように述べています。
*AIエージェントは必要な最小限の権限範囲内で機能を実行しなければなりません。自身の権限を昇格させたり、シークレットを共有したり、第1の原則と矛盾する命令に従ったりしてはなりません。*
原則をエージェントアーキテクチャの観点から言い換えてみましょう。
エージェントがシークレットを共有するのを防ぎたい場合は、エージェントとシークレットを共有しないでください。さらに言えば、**確率論的な魂(LLM)はシークレットやトークンに決してアクセスしてはなりません**。決定論的な魂はトークンを管理できますが、悪意のある者の手に渡る可能性を最小限に抑えるための対策を講じる必要があります。たとえば、有効期間の短いトークンを使用する必要がありますが、[リフレッシュトークン](https://auth0.com/blog/refresh-tokens-what-are-they-and-when-to-use-them/)による頻繁な更新が必要になります。エージェントが複数のサードパーティサービス(Gmail、Slack、Stripeなど)と相互作用する場合、各サードパーティサービスの有効期間の長いトークンをローカルに保存しないでください。代わりに[トークンボールト](https://auth0.com/features/token-vault)を使用してください。
エージェントが使用するトークンを保護するための最適なアプローチについては、以下の記事を確認ください。
* [Build an AI Assistant with LangGraph, Next.js, and Auth0 Connected Accounts](https://auth0.com/blog/ai-assistant-langgraph-nextjs-slack-github/)
* [Secure Third-Party Tool Calling in LlamaIndex Using Auth0](https://auth0.com/blog/third-party-tool-calling-llamaindex-auth0-python/)
* [MS Agent Framework and Python: Use the Auth0 Token Vault to Call Third-Party APIs](https://auth0.com/blog/microsoft-agent-framework-python-auth0-token-vault/)
エージェントに必要な権限のみを付与するには、アクセストークンでスコープを使用し、[最小権限の原則を適用](https://auth0.com/blog/oauth2-access-tokens-and-principle-of-least-privilege/)します。
しかし、第2の原則に対する脅威はトークンや権限の管理からだけ生じるわけではありません。エージェントが受け取る入力から生じる可能性があります。エージェントの確率論的な魂を欺き、特定の制約を回避する可能性のあるプロンプトインジェクションを考慮してください。
LLMによって生成された出力も、特にツールを呼び出すことを意図している場合、脅威となる可能性があります。
言い換えると、**決定論的な魂にはLLMの入力と出力をサニタイズする責任があります**。プロンプトインジェクションを防ぎ、不適切な出力を処理するためのテクニックについては、以下の記事を確認ください。
* [Hiding Prompts in Plain Sight: A New AI Security Risk](https://auth0.com/blog/prompt-injection-ai-browser/#Indirect-Prompt-Injections)
* [Trusting AI Output? Why Improper Output Handling is the New XSS](https://auth0.com/blog/owasp-llm05-improper-output-handling/)
## 意思決定制御の原則
第3の原則は意思決定の制御に関するものであり、次のように述べています。
*AIエージェントは、第1または第2の原則と矛盾しない限り、重要または不可逆的な決定の最終権限を人間のオペレーターに譲渡しなければなりません。*
従来のソフトウェアでは、特定の入力と出力の間のパスはある程度事前に決定されています。エージェントでは、入力と出力の間に無制限の組み合わせがあり、プロンプトを解釈する際のLLMの決定によってほぼ完全に決定されます。
AIエージェントのアーキテクチャでは、入力を解釈し、特定の目標を達成するために使用するツールを決定するタスクを確率論的な魂に委任しています。エージェントに多大な柔軟性を与えると同時に、大きな責任を負わせます。
意思決定制御の原則を実装するには、代理として実行できる最も重要なアクションを特定し、アクションの実行に対する確認を求めることで、エージェントの責任を制限する必要があります。**決定論的な魂には、重要な決定にユーザーを関与させる責任があります**。
構築しているエージェントのタイプに応じて、確認リクエストはインタラクティブまたは非同期になります。Claude CodeやGitHub Copilotがフォルダへの書き込みやコードの変更の許可を求めるようなインタラクティブなリクエストを考えてみてください。非同期の許可リクエストは、無人エージェントがメールやプッシュ通知を介して送信できるものです。
どのような場合でも、修復不可能な損害を防ぐためにはユーザーを関与させることが不可欠です。
Auth0を使用して非同期認可を処理する方法の例をいくつか示します。
* [Securing AI Agents: Mitigate Excessive Agency with Zero Trust Security](https://auth0.com/blog/mitigate-excessive-agency-ai-agents/)
* [Secure “Human in the Loop” Interactions for AI Agents](https://auth0.com/blog/secure-human-in-the-loop-interactions-for-ai-agents/)
* [Implementing Asynchronous Human-in-the-Loop Authorization in Python with LangGraph and Auth0](https://auth0.com/blog/async-ciba-python-langgraph-auth0/)
* [Use CIBA Authentication with Auth0 and .NET](https://auth0.com/blog/use-ciba-authentication-with-auth0-dotnet/)
## AIエージェントを保護するためのポイント
「2つの魂」モデルは、AIエージェントのセキュリティに関する具体的なメンタルモデルを提供します。本記事のセキュリティに関する洞察は直感に反しています。最も制御できないコンポーネント(LLM)は、セキュリティの取り組みを集中させる場所ではありません。**セキュリティは、確率論的な魂を制限するように決定論的な魂を設計することに焦点を当てる必要があります**。視点により、データのフィルタリング、入力と出力のサニタイズ、および重要なヒューマンインザループの決定の管理に対するAgent Coreの責任を強制することで、[AIセキュリティの3原則](https://auth0.com/blog/three-laws-ai-security/)を適用できます。
強調したい主なポイントは以下の通りです。
* **セキュリティはコードにある:** LLMを直接保護できません。LLMをラップして制御する決定論的なAgent Coreを保護します。
* **制約は制御である:** Agent Coreを使用して、データ、シークレット、トークン、および外部アクションへのLLMのアクセスに対する境界を厳密に適用します。
* **人間の介入:** すべての重要または不可逆的な決定に対して、決定論的な魂に「ヒューマンインザループ」プロトコルを実装します。
すべてをゼロから実装することは困難でリスクを伴う可能性があります。[Auth0 for AI Agents](https://auth0.com/ai)は、決定論的なセキュリティレイヤー(トークン管理、アクセス制御、およびヒューマンインザループフロー)の処理を支援するため、エージェントが実際に実行するタスクに集中できます。