---
title: "API認可における「欲求階層説」:AIエージェントへの対応がまだ不十分な理由"
description: "セキュアなエージェントワークフローを実現するための、API認可における欲求階層説の4つのレベルを解説します。"
authors:
- name: "Andrés Aguiar"
url: "https://auth0.com/blog/authors/andres-aguiar/"
date: "Jan 15, 2026"
category: "Identity & Security"
tags: ["ai", "authorization", "fga", "api"]
url: "https://auth0.com/blog/jp-api-authorization-hierarchy-needs/"
---
# API認可における「欲求階層説」:AIエージェントへの対応がまだ不十分な理由
すべてのエンジニアリングリーダーは、現在共通のプレッシャーに直面しています。「いつ自社製品をAIエージェントが利用できるようにするのか」という問いです。
そのビジョンは魅力的です。ユーザーがお気に入りのLLMを使用して「今週のチームの作業を要約して」と入力するだけで、AIが自律的にデータを取得し、推論し、結果を出すことを期待しています。しかし、アプリケーションをAIエージェントに公開する前に、厳しい現実に直面する必要があります。**認可に近道はありません。**
製品をLLMやエージェントから利用できるようにするには、製品の外部APIを提供する必要があります。API認可レイヤーが複雑な人間の階層構造を処理できるほど成熟していない場合、自律型エージェントによる負荷に耐えられず破綻します。AIエージェントは制御不能な存在になる可能性があり、ハルシネーションによって管理者権限を取得したり、テナントの境界を越えてデータを漏洩させたり、データベース全体を削除したりすることさえあります。
これを説明するために、API認可における欲求の階層説を見てみましょう。ここでは、一般的なB2Bプロジェクト管理システム(JiraやAsanaのようなもの)を例として進めます。目標は、エージェントが製品のAPIを使用して特定のタスクを実行できるようにすることです。
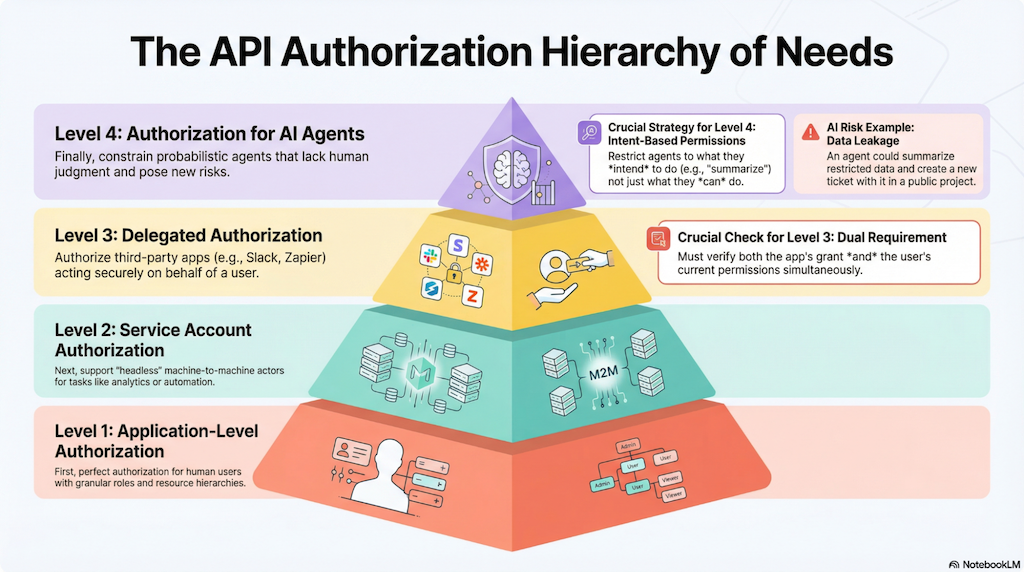 ## レベル1:基盤(アプリケーションレベルの認可)
機械について考える前に、人間に対する認可を完璧にする必要があります。これがピラミッドの土台です。アプリケーションレベルでの深い実装が必要であり、いくつかの複雑なレイヤーに対処します。
* **マルチテナンシー:**顧客間のデータ分離を確実にします。
* **きめ細かなロール:**テナントレベルのロール(管理者、請求担当マネージャー)、プロジェクトレベルのロール(オーナー、チームメンバー)、チケットレベルのロール(閲覧者、編集者)が必要です。
* **リソース階層:**権限はロジックを継承しなければなりません。テナント管理者はすべてを閲覧でき、プロジェクトオーナーは自身のプロジェクト内でのみチケットを作成できるようにします。一般ユーザーは、自身のチームのプロジェクトやチケット、あるいは直接共有されたチケットのみを確認できるようにします。
システムが単純なロールベースのフラットな権限に依存している場合、上のレベルに進む準備はできていません。
## レベル2:サービスアカウント(M2M)
人間によるアクセスが強固になったら、API認可レイヤーを、自身に代わって動作するサービスアカウントクライアントをサポートするように進化させる必要があります。これらは、通常のAPIクライアントまたはエージェントの場合があります。
顧客は、分析レポート(チケットの完了時間など)のためにデータを取得したり、特定のイベント(イシューのクローズ、プロジェクトの期限超過、サポートイシューのエンジニアリングへのエスカレーションなど)が発生したときにチケットを自動作成したりすることを望みます。
これには、APIキーまたは[OAuth Client Credentials](https://auth0.com/docs/ja-jp/get-started/authentication-and-authorization-flow/client-credentials-flow)を使用して、顧客がサービスアカウントの認証情報を作成できるようにする必要があります。これらのアカウントは、各テナントが設定できる定義済みの権限セットを持ち、単一のテナントにアクセスします。
## レベル3:委譲された認可(代理実行)
あるアプリケーションがユーザーに代わって別のアプリケーションを使用できるようにするたびに、[委譲された認可フロー](https://auth0.com/blog/jp/auth0-token-vault-secure-token-exchange-for-ai-agents/)を実行します。例えば、Slack内のGoogleカレンダーアプリにカレンダーへのアクセスを許可する場合です。これは、サードパーティがユーザーに代わって動作する標準的なOAuthパターンに依存しています。
例えば、Slackプラグインがシステム内でチケットを作成できるようにしたい場合があります。これらのアプリケーションは、特定のプロジェクトに対するユーザーの同意を取得する必要があります。
APIは、ユーザーとアプリケーションの両方を認可する必要があります。
* **付与(Grant):**APIは、ユーザーがプロジェクトでアクションを実行する権限をアプリケーションに許可したことを検証しなければなりません。
* **ユーザー権限:**APIは、ユーザーが現在そのプロジェクトで動作するための権限を保持していることも検証しなければなりません。
SlackアプリにプロジェクトAでのチケット作成を許可した場合、APIは、ユーザーがSlackにその操作を許可したこと、およびユーザーが依然としてプロジェクトAでチケットを作成できることを確認する必要があります。
ほとんどのAPIはOAuth委譲フローをサポートしておらず、サポートしていてもスコープは大まかです。例えば、スコープが"""create:ticket:project_A"""ではなく"""create:ticket"""になっている場合があります。きめ細かな同意フローがなければ、AIエージェントには実行するタスクに対して過剰な権限が割り当てられます。
## レベル4:AIエージェント
上記の懸念事項に対処して初めて、アプリケーションをAIエージェントに公開できます。
エージェントは新しいリスク要因をもたらします。エージェントは本質的にサービスアカウントの認証情報やユーザーに関連付けられた認証情報を使用しますが、人間のような判断力に欠けています。標準的なユーザーよりもさらに制限する必要があります。
エージェントは、一連のドキュメントに基づいて質問に答えるのが非常に得意です。関連情報を探すために検索拡張生成(RAG)技術を使用します。一連のチケットを要約する必要がある場合、ユーザーがそのタスクのためにアクセスできるプロジェクトのチケットのみを確実に要約させるにはどうすればよいでしょうか。
プロジェクト管理の例におけるリスクを検討してください。
* **データ漏洩:**ユーザーが要約を依頼します。エージェントは制限されたプロジェクトからチケットを読み取り、それらを要約し、会社全体に公開されているプロジェクトにその要約を含む新しいチケットを作成します。
* **認可されていないデータ:**ユーザーが要約を依頼します。エージェントはすべてのプロジェクトのチケットを含むベクトルデータベースを使用し、検索拡張生成(RAG)技術を適用して回答を作成します。この設計では、ユーザーがアクセスを認可されていないプロジェクトのデータが意図せず表示されることを保証します。
* **オーケストレーションの失敗:**ユーザーが「要約をマネージャーにメールで送って」と指示します。厳格な境界線がなければ、エージェントは会社全体や外部の連絡先にメールを送る可能性があります。これは、エージェントがユーザーの全権限を継承するために発生します。ユーザーが会社にメールを送れるなら、エージェントも送信できます。エージェントを、ユーザーの潜在的な全権限ではなく、特定のタスクに制限する必要があります。
業界全体として、これらのシナリオに対処するための特定のパターンを模索しています。
* ユーザーの権限に基づいて、ベクトルデータベースから返されるドキュメントを事前フィルタリングまたは事後フィルタリングすることで、RAGパイプラインに認可を追加します。
* 破壊的なアクションには人間を介在させます。これは、ユーザーがすべてに対して「はい」をクリックしてしまう承認疲れを招くことがよくあります。
* 登場しつつある解決策は、意図ベースの権限(Intent-Based Permissions)です。ここでは、エージェントが何を達成しようとしているかに基づいてアクセスを制限します。意図が「チケットの要約」であれば、エージェントは読み取り専用アクセス権を持ちます(チケットの作成はできません)。意図が「マネージャーに要約を送信」であれば、スコープはマネージャーのメールアドレスのみに制限されます。ただし、意図は、定義済みの意図のセットに基づいてLLMが推論する必要があります。論文[Delegated Authorization for Agents Constrained to Semantic Task-to-Scope Matching](https://arxiv.org/abs/2510.26702)は、この問題と可能な解決策を説明しています。
レベル3が決定論的なSlackボットを制約することであれば、レベル4は、ハルシネーションを起こしたり、特定の意図を追求したりする可能性がある確率論的なAIを制約することです。
業界では、これらのニーズに対処するために、[MCP Authorization](https://modelcontextprotocol.io/specification/2025-06-18)のような標準の定義、AI/MCPゲートウェイの作成、または[Cross App Access](https://www.okta.com/newsroom/press-releases/okta-introduces-cross-app-access-to-help-secure-ai-agents-in-the/)のような標準の実装を進めています。しかし、まだ初期段階であり、学ぶべきことが多くあります。
## 認可なくしてエージェントの未来はない
まだ初期段階であり、どのアーキテクチャパターンが普及するかは分かりません。しかし、議論の余地がないことが1つあります。**まずAPIレイヤーでユーザーとクライアントの認可を適切に処理しなければ、エージェントAIの未来はありません。**
基礎を固めずに屋根を建てることはできません。レベル3と4の複雑さ、つまり階層、委譲、およびきめ細かな意図のモデリングは、単純なロールやデータベースの列で管理するにはあまりにも困難です。
あらゆるレイヤーにおける認可の課題に対処するために、[Auth0 FGA](https://docs.fga.dev/getting-started)の使用方法を確認し、今すぐジャーニーを開始できます。すべてのシナリオに対処する方法を詳しく説明する次回の記事を待ってください。
## レベル1:基盤(アプリケーションレベルの認可)
機械について考える前に、人間に対する認可を完璧にする必要があります。これがピラミッドの土台です。アプリケーションレベルでの深い実装が必要であり、いくつかの複雑なレイヤーに対処します。
* **マルチテナンシー:**顧客間のデータ分離を確実にします。
* **きめ細かなロール:**テナントレベルのロール(管理者、請求担当マネージャー)、プロジェクトレベルのロール(オーナー、チームメンバー)、チケットレベルのロール(閲覧者、編集者)が必要です。
* **リソース階層:**権限はロジックを継承しなければなりません。テナント管理者はすべてを閲覧でき、プロジェクトオーナーは自身のプロジェクト内でのみチケットを作成できるようにします。一般ユーザーは、自身のチームのプロジェクトやチケット、あるいは直接共有されたチケットのみを確認できるようにします。
システムが単純なロールベースのフラットな権限に依存している場合、上のレベルに進む準備はできていません。
## レベル2:サービスアカウント(M2M)
人間によるアクセスが強固になったら、API認可レイヤーを、自身に代わって動作するサービスアカウントクライアントをサポートするように進化させる必要があります。これらは、通常のAPIクライアントまたはエージェントの場合があります。
顧客は、分析レポート(チケットの完了時間など)のためにデータを取得したり、特定のイベント(イシューのクローズ、プロジェクトの期限超過、サポートイシューのエンジニアリングへのエスカレーションなど)が発生したときにチケットを自動作成したりすることを望みます。
これには、APIキーまたは[OAuth Client Credentials](https://auth0.com/docs/ja-jp/get-started/authentication-and-authorization-flow/client-credentials-flow)を使用して、顧客がサービスアカウントの認証情報を作成できるようにする必要があります。これらのアカウントは、各テナントが設定できる定義済みの権限セットを持ち、単一のテナントにアクセスします。
## レベル3:委譲された認可(代理実行)
あるアプリケーションがユーザーに代わって別のアプリケーションを使用できるようにするたびに、[委譲された認可フロー](https://auth0.com/blog/jp/auth0-token-vault-secure-token-exchange-for-ai-agents/)を実行します。例えば、Slack内のGoogleカレンダーアプリにカレンダーへのアクセスを許可する場合です。これは、サードパーティがユーザーに代わって動作する標準的なOAuthパターンに依存しています。
例えば、Slackプラグインがシステム内でチケットを作成できるようにしたい場合があります。これらのアプリケーションは、特定のプロジェクトに対するユーザーの同意を取得する必要があります。
APIは、ユーザーとアプリケーションの両方を認可する必要があります。
* **付与(Grant):**APIは、ユーザーがプロジェクトでアクションを実行する権限をアプリケーションに許可したことを検証しなければなりません。
* **ユーザー権限:**APIは、ユーザーが現在そのプロジェクトで動作するための権限を保持していることも検証しなければなりません。
SlackアプリにプロジェクトAでのチケット作成を許可した場合、APIは、ユーザーがSlackにその操作を許可したこと、およびユーザーが依然としてプロジェクトAでチケットを作成できることを確認する必要があります。
ほとんどのAPIはOAuth委譲フローをサポートしておらず、サポートしていてもスコープは大まかです。例えば、スコープが"""create:ticket:project_A"""ではなく"""create:ticket"""になっている場合があります。きめ細かな同意フローがなければ、AIエージェントには実行するタスクに対して過剰な権限が割り当てられます。
## レベル4:AIエージェント
上記の懸念事項に対処して初めて、アプリケーションをAIエージェントに公開できます。
エージェントは新しいリスク要因をもたらします。エージェントは本質的にサービスアカウントの認証情報やユーザーに関連付けられた認証情報を使用しますが、人間のような判断力に欠けています。標準的なユーザーよりもさらに制限する必要があります。
エージェントは、一連のドキュメントに基づいて質問に答えるのが非常に得意です。関連情報を探すために検索拡張生成(RAG)技術を使用します。一連のチケットを要約する必要がある場合、ユーザーがそのタスクのためにアクセスできるプロジェクトのチケットのみを確実に要約させるにはどうすればよいでしょうか。
プロジェクト管理の例におけるリスクを検討してください。
* **データ漏洩:**ユーザーが要約を依頼します。エージェントは制限されたプロジェクトからチケットを読み取り、それらを要約し、会社全体に公開されているプロジェクトにその要約を含む新しいチケットを作成します。
* **認可されていないデータ:**ユーザーが要約を依頼します。エージェントはすべてのプロジェクトのチケットを含むベクトルデータベースを使用し、検索拡張生成(RAG)技術を適用して回答を作成します。この設計では、ユーザーがアクセスを認可されていないプロジェクトのデータが意図せず表示されることを保証します。
* **オーケストレーションの失敗:**ユーザーが「要約をマネージャーにメールで送って」と指示します。厳格な境界線がなければ、エージェントは会社全体や外部の連絡先にメールを送る可能性があります。これは、エージェントがユーザーの全権限を継承するために発生します。ユーザーが会社にメールを送れるなら、エージェントも送信できます。エージェントを、ユーザーの潜在的な全権限ではなく、特定のタスクに制限する必要があります。
業界全体として、これらのシナリオに対処するための特定のパターンを模索しています。
* ユーザーの権限に基づいて、ベクトルデータベースから返されるドキュメントを事前フィルタリングまたは事後フィルタリングすることで、RAGパイプラインに認可を追加します。
* 破壊的なアクションには人間を介在させます。これは、ユーザーがすべてに対して「はい」をクリックしてしまう承認疲れを招くことがよくあります。
* 登場しつつある解決策は、意図ベースの権限(Intent-Based Permissions)です。ここでは、エージェントが何を達成しようとしているかに基づいてアクセスを制限します。意図が「チケットの要約」であれば、エージェントは読み取り専用アクセス権を持ちます(チケットの作成はできません)。意図が「マネージャーに要約を送信」であれば、スコープはマネージャーのメールアドレスのみに制限されます。ただし、意図は、定義済みの意図のセットに基づいてLLMが推論する必要があります。論文[Delegated Authorization for Agents Constrained to Semantic Task-to-Scope Matching](https://arxiv.org/abs/2510.26702)は、この問題と可能な解決策を説明しています。
レベル3が決定論的なSlackボットを制約することであれば、レベル4は、ハルシネーションを起こしたり、特定の意図を追求したりする可能性がある確率論的なAIを制約することです。
業界では、これらのニーズに対処するために、[MCP Authorization](https://modelcontextprotocol.io/specification/2025-06-18)のような標準の定義、AI/MCPゲートウェイの作成、または[Cross App Access](https://www.okta.com/newsroom/press-releases/okta-introduces-cross-app-access-to-help-secure-ai-agents-in-the/)のような標準の実装を進めています。しかし、まだ初期段階であり、学ぶべきことが多くあります。
## 認可なくしてエージェントの未来はない
まだ初期段階であり、どのアーキテクチャパターンが普及するかは分かりません。しかし、議論の余地がないことが1つあります。**まずAPIレイヤーでユーザーとクライアントの認可を適切に処理しなければ、エージェントAIの未来はありません。**
基礎を固めずに屋根を建てることはできません。レベル3と4の複雑さ、つまり階層、委譲、およびきめ細かな意図のモデリングは、単純なロールやデータベースの列で管理するにはあまりにも困難です。
あらゆるレイヤーにおける認可の課題に対処するために、[Auth0 FGA](https://docs.fga.dev/getting-started)の使用方法を確認し、今すぐジャーニーを開始できます。すべてのシナリオに対処する方法を詳しく説明する次回の記事を待ってください。