

TL;DR: This article continues the journey we started with Azure DocumentDB. In this installment, we will learn how to build common query patterns and services with ASP.NET Core. A full working application sample is available as a GitHub repository.
Integration between Auth0 and Azure DocumentDB
In our previous article: Integration between Auth0 and Azure DocumentDB we configured an integration between Auth0 and Azure DocumentDB as a Custom Database Provider to store our enrolled users in JSON format, as documents.
Conceptually, in Azure DocumentDB, a database can be defined as a logical container of document collections; each collection can hold not only documents but stored procedures, triggers, and user-defined functions. The collection is the billable unit and defines the consistency level.
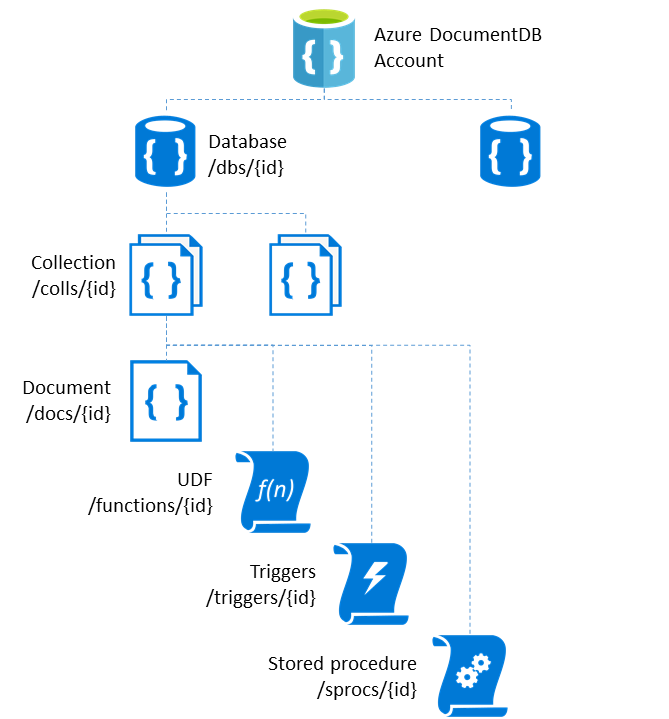
Querying and storing data on Azure DocumentDB
Azure DocumentDB collections have automatic attribute indexing, which can also be customized. This schema-free approach lets you store documents with different and dynamic structures that can evolve over time.
Since we are storing our users on DocumentDB, this means we can also store other object types in the same collection without their interfering with each other.
We will work with a practical pattern to achieve this multiple-type storage and build performance-wise querying examples; even though DocumentDB supports Node.js, Python, Java, and .Net SDKs, we'll be working on the latter. A full sample on GitHub is available running on ASP.NET Core.
Dependencies
Using ASP.NET Core, we will use the project.json to define dependencies. We will only need the Azure DocumentDB Nuget package on the latest version:
{ ... "Microsoft.Azure.DocumentDB.Core":"0.1.0-preview" ... }
Base Type Pattern
We start by creating a base abstract class with Type and Id attributes. All DocumentDB objects have an id attribute that can be auto generated (as a Guid) or set upon creation:
public abstract class Entity { public Entity(string type) { this.Type = type; } /// <summary> /// Object unique identifier /// </summary> [Key] [JsonProperty("id")] public string Id { get; set; } /// <summary> /// Object type /// </summary> public string Type { get; private set; } }
You might notice the JsonProperty decorator. This is because the "id" attribute on DocumentDB is always lowercase; the decorator will make sure the property name matches, no matter what your JSON serialization configuration is.
Now, every object type you want to store on DocumentDB can inherit from this class and set its own attributes:
public class NotificationPreferences : Entity { public NotificationPreferences():base("notificationpreferences") { Email = false; Push = false; SMS = false; } [JsonProperty("user")] public string User { get; set; } [JsonProperty("email")] public bool Email { get; set; } [JsonProperty("push")] public bool Push { get; set; } [JsonProperty("sms")] public bool SMS { get; set; } }
public class ContactAddress : Entity { public ContactAddress():base("address") { Primary = false; } [JsonProperty("user")] public string User { get; set; } [JsonProperty("address")] public string Address { get; set; } [JsonProperty("primary")] public bool Primary { get; set; } }
Performant Querying
Azure DocumentDB allows for insert, update, delete, and querying capabilities on different flavors, including LINQ and SQL syntax.
If you already have your data in another format / source, you can use the Azure DocumentDB Data Migration tool to migrate it to a collection.
The following operations are available as a full provider on the GitHub repository; we will highlight the snippets that will enable you to understand the basic operations.
To successfully connect to a DocumentDB collection we will need the service url endpoint and the password/key (when using the MongoDB protocol-enabled version it's called Password and when using a normal DocumentDB instance it's called Key) obtained on the Azure Portal. They will enable us to access the service through a DocumentClient.
Like we mentioned earlier, documents are grouped in collections within a database, each collection is accessed by a Resource URI syntax. The SDK provides helper methods to build URIs:
private Uri GetCollectionLink() { return UriFactory.CreateDocumentCollectionUri(_settings.DatabaseName, _settings.CollectionName); }
We always start by creating an instance of a DocumentClient and using it in every access operation. A common performance tip is to maintain a single DocumentClient for all our queries and operations:
public DocumentDbProvider(DocumentDbSettings settings) { _settings = settings; _collectionUri = GetCollectionLink(); _dbClient = new DocumentClient(_settings.DatabaseUri, _settings.DatabaseKey, new ConnectionPolicy(){ MaxConnectionLimit = 100 }); _dbClient.OpenAsync().Wait(); }
For other performance best practices, there is an entire article on this topic.
We will now cover the basic operations.
Inserting documents
For a generic insertion that works for any object type we can use:
public async Task<string> AddItem<T>(T document) { var result = await _dbClient.CreateDocumentAsync(_collectionUri, document); return result.Resource.Id; }
This will internally use Newtonsoft.Json to serialize your object to JSON and store it. If you set the id property it will be maintained; if you don't, it will create a new Guid string. This also means that you can exclude attributes from serialization with the JsonIgnore attribute.
Updating documents
The same simple procedure works on updates:
public async Task<string> UpdateItem<T>(T document, string id) { var result = await _dbClient.ReplaceDocumentAsync(GetDocumentLink(id), document); return result.Resource.Id; }
With a helper that obtains a document URI:
private Uri GetDocumentLink(string id) { return UriFactory.CreateDocumentUri(_settings.DatabaseName, _settings.CollectionName, id); }
Azure DocumentDB does not support partial updates at the time of this article's writing. If you try to do it, you will end up with a replaced document with fewer attributes than it had originally.
Deleting a document
Deleting a document is as simple as:
public async Task DeleteItem(string id) { await _dbClient.DeleteDocumentAsync(GetDocumentLink(id)); }
It requires a Document URI, which can be created with our previous helper method.
Querying documents
Queries can be performed using SQL syntax or LINQ to DocumentDB syntax. Building a generic query method is as simple as:
public IQueryable<T> CreateQuery<T>(FeedOptions feedOptions) { return _dbClient.CreateDocumentQuery<T>(_collectionUri, feedOptions); }
Or for a SQL syntax query:
public IQueryable<T> CreateQuery<T>(string sqlExpression, FeedOptions feedOptions) { return _dbClient.CreateDocumentQuery<T>(_collectionUri, sqlExpression, feedOptions); }
You might notice a FeedOptions attribute. This lets you define things like the size of result sets or pagination. If we are creating a query that will return just one result, it’s a performant good practice to set the MaxItemCount property to 1:
var feedOptions = new FeedOptions() { MaxItemCount = 1 };
IQueryable can be chained, meaning that following our Type object pattern, we can create queries for different object types based on the same internal function:
_provider.CreateQuery<OneType>(feedOptions).Where(x => x.Type == "onetype"); _provider.CreateQuery<OtherType>(feedOptions).Where(x => x.Type == "othertype");
On the related repository there are a couple of extensions that might simplify your queries, like a TakeOne, which returns a single object (or null) from a IQuerable:
var feedOptions = new FeedOptions() { MaxItemCount = 1 }; return _provider.CreateQuery<SomeClass>(feedOptions).Where(x => x.Type == "someclass" && x.OtherProperty == someValue).TakeOne();
Finally, pagination can be achieved through the RequestContinuation attribute on the FeedOptions. We obtain this value by querying first and then saving the ResponseContinuation attribute.
var documentQuery = myIQueryAble.AsDocumentQuery(); var queryResult = await documentQuery.ExecuteNextAsync<T>(); var responseContinuationToken = queryResult.ResponseContinuation;
The repository includes an extension to solve this scenario by a PagedResults wrapper:
public async Task<PagedResults<MyClass>> GetContactAddresses(int size = 10, string continuationToken = "") { var feedOptions = new FeedOptions() { MaxItemCount = size }; if (!string.IsNullOrEmpty(continuationToken)) { feedOptions.RequestContinuation = continuationToken; } return await _provider.CreateQuery<MyClass>(feedOptions).Where(x => x.Type == "myClass").ToPagedResults(); }
Notice how we set the page size by the MaxItemCount attribute of the FeedOptions.
Dependency injection
When working on ASP.NET Core, one of the core features is Dependency Injection. Because of this, it’s vital that our DocumentDB provider is wrapped in a service that can be injected by an interface.
A simple way to do this is to create a service class that receives an IConfiguration (possibly coming from your appsettings.json file) and creates an instance of our DocumentDbProvider:
private readonly DocumentDbProvider _provider; public DocumentDbService(IConfiguration configuration) { _provider = new DocumentDbProvider(new DocumentDbSettings(configuration)); }
By implementing an interface, we can maintain a single copy of our service through the IServiceCollection available on our Startup.cs file:
public void ConfigureServices(IServiceCollection services) { services.AddAuthentication( options => options.SignInScheme = CookieAuthenticationDefaults.AuthenticationScheme); services.AddSingleton<IDocumentDbService>(x=>new DocumentDbService(Configuration.GetSection("DocumentDb"))); services.Configure<Auth0Settings>(Configuration.GetSection("Auth0")); services.AddMvc(); services.AddOptions(); }
This way, it’s easy to inject it in an MVC Controller:
public class ProfileController : Controller { private readonly IDocumentDbService _dbService; public ProfileController(IDocumentDbService dbService) { _dbService = dbService; } }
Partitions and parallelism in Azure DocumentDB
Collections can scale dynamically with Azure DocumentDB’s partition support. Partitioned collections have a potentially higher throughput and require a Partition Key configuration. Single-partition collections cannot be changed to Partitioned collections, so plan ahead: if your application data might grow beyond 10GB or you need more than 10,000 Request Units per second, you might as well evaluate Partitioned collections.
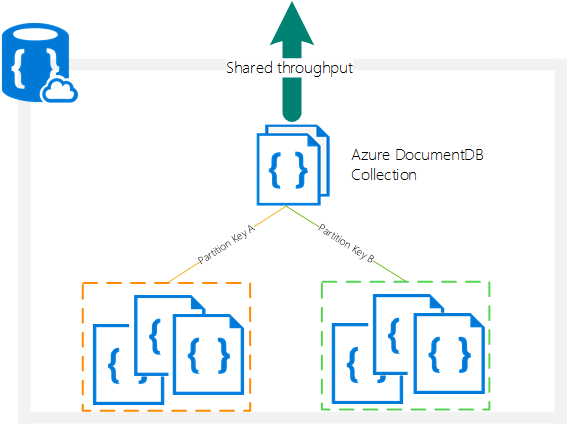
Furthermore, each of the operations we described earlier will require an additional Partition Key value as part of the RequestOptions class.
Partitions help optimize throughput by allowing us to take advantage of parallel queries on multiple collections by using .Net’s Task Parallel Library.
For a more detailed look at implementing Partition querying, take a look at the official sample GitHub repository.
Aside: Using Auth0 with Azure DocumentDB
Azure DocumentDB can be integrated as a custom database provider by using the MongoDB protocol.
Create a custom database connection by going to the Connections > Database in your Auth0 management dashboard and build your MongoDB connection string by obtaining the credentials from your Azure DocumentDB account on the Azure Portal:
mongodb://<your_service_name>:<your_password>==@<your_service_name>.documents.azure.com:10250/auth0?ssl=true
You can then use it on your Database Action Scripts sections.
For a step by step guide, you can view Planet-scale authentication with Auth0 and Azure DocumentDB
Conclusion
Azure DocumentDB is a fast and flexible cloud storage service that will work on almost any use case scenario and can work along with Auth0 in a highly streamlined fashion. Remember that a full sample, including extensions and providers, is available on GitHub.