
In this post in the microservices series we will talk about the service registry. In part 2 we discussed the API gateway, where we mentioned that services are registered in a database. The gateway dispatches requests according to the information contained in that database. Below we will explore how that database is populated and in which way services, clients and the gateway interact with it.
The service registry
The service registry is a database populated with information on how to dispatch requests to microservice instances. Interactions between the registry and other components can be divided into two groups, each with two subgroups:
- Interactions between microservices and the registry (registration)
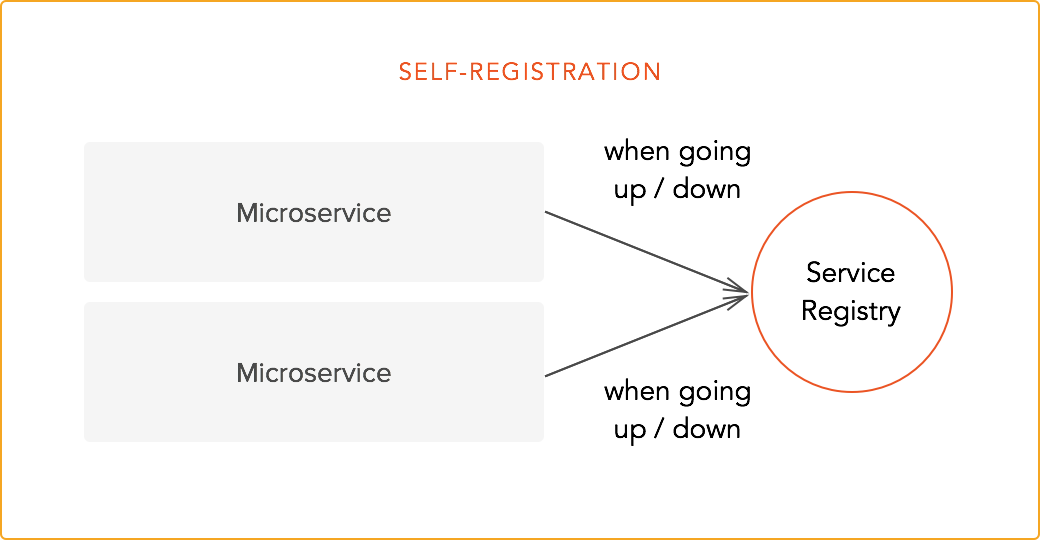
- Self-registration
- Third-party registration
- Interactions between clients and the registry (discovery)
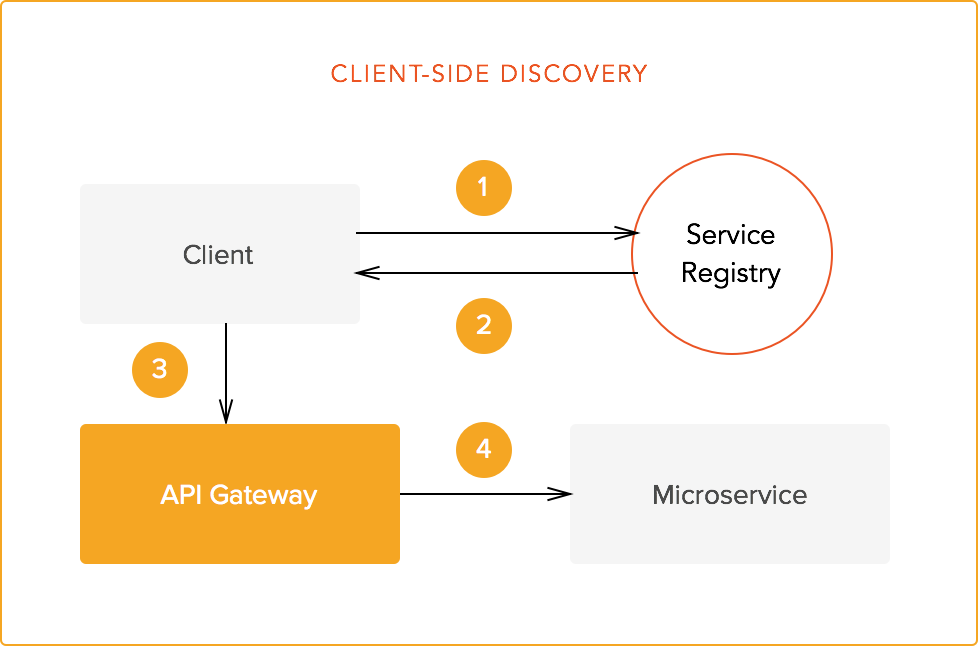
- Client-side discovery
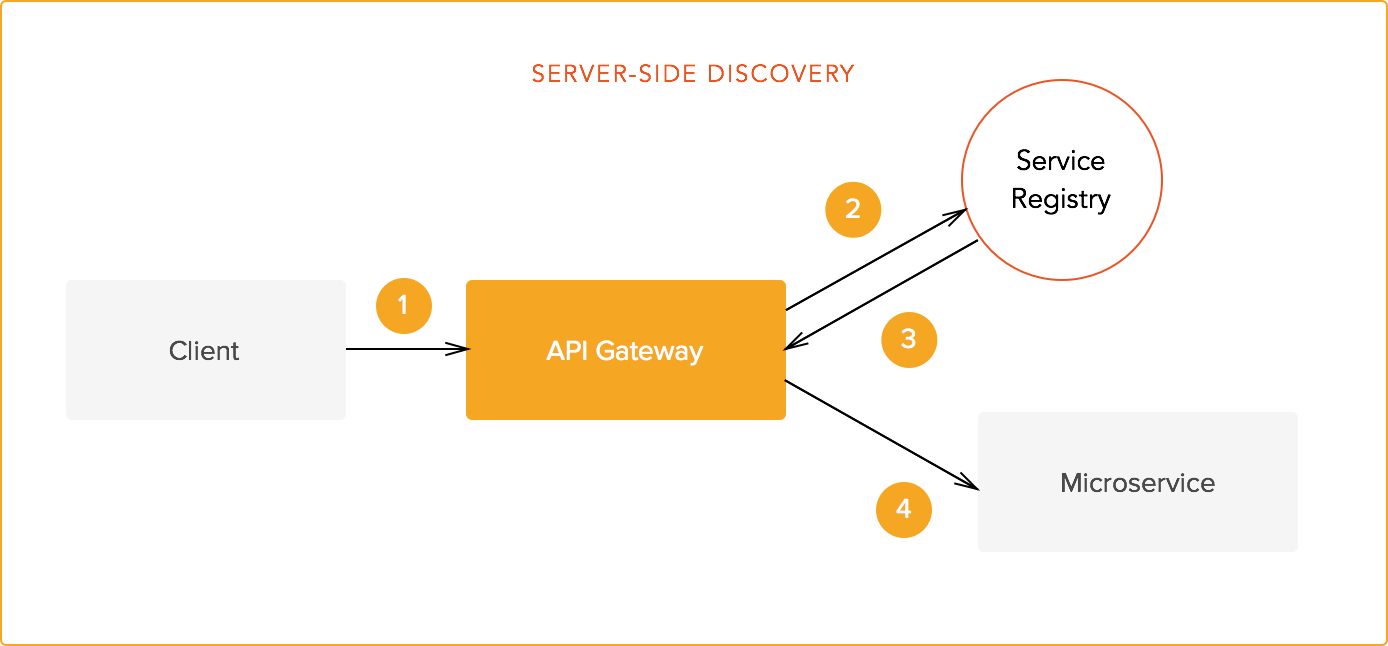
- Server-side discovery
Registration
Most microservice-based architectures are in constant evolution. Services go up and down as development teams split, improve, deprecate and do their work. Whenever a service endpoint changes, the registry needs to know about the change. This is what registration is all about: who publishes or updates the information on how to reach each service.
Self-registration forces microservices to interact with the registry by themselves. When a service goes up, it notifies the registry. The same thing happens when the service goes down. Whatever additional data is required by the registry must be provided by the service itself. If you have been following this series, you know that microservices are all about dealing with a single concern, so self-registration might seem like an anti-pattern. However, for simple architectures, self-registration might be the right choice.
Third-party registration is normally used in the industry. In this case, there is a process or service that manages all other services. This process polls or checks in some way which microservice instances are running and it automatically updates the service registry. Additional data might be provided in the form of per-service config files (or policy), which the registration process uses to update the database. Third-party registration is commonplace in architectures that use tools such as Apache ZooKeeper or Netflix Eureka and other service managers.
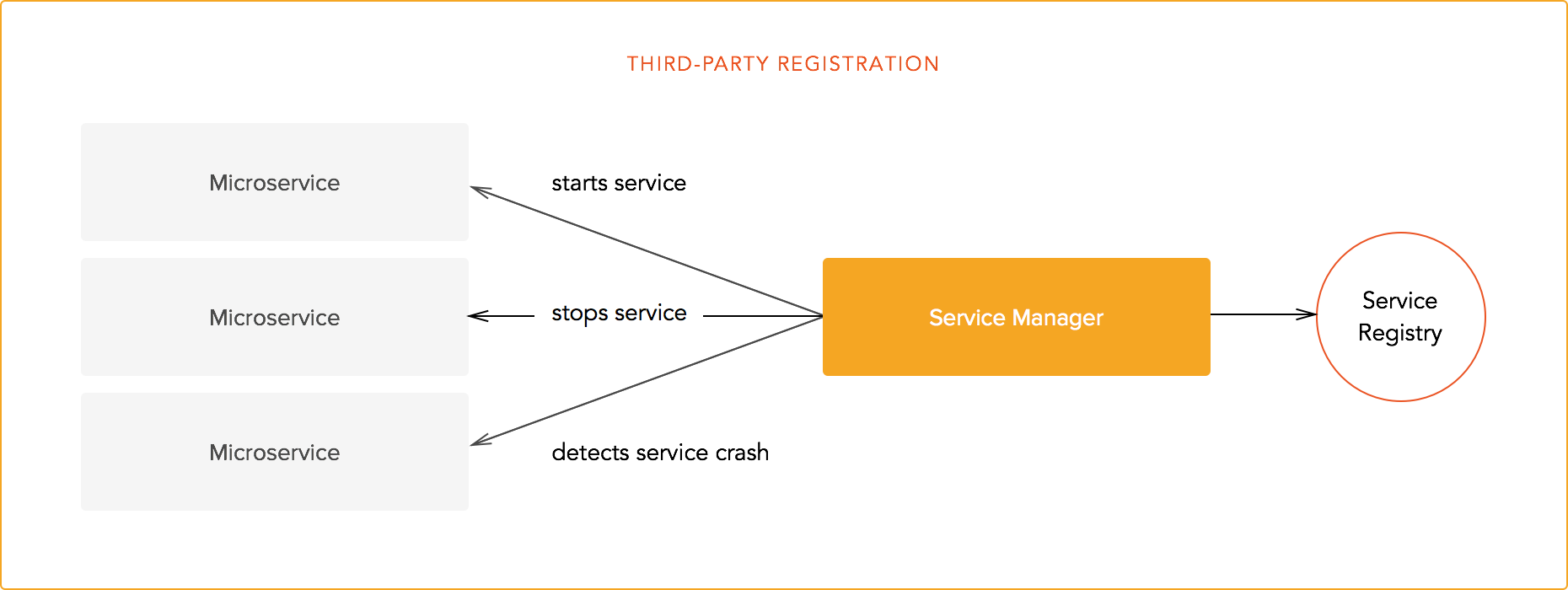
Third-party registration also provides other benefits. For instance, what happens when a service goes down? A third-party registration service might be configured to provide safe fallbacks for services that fail. Other policies might be implemented for other cases. For instance, the service registry process might be notified of a high-load condition and automatically add a new endpoint by requesting the instantiation of a new microservice-process or VM. As you can imagine, these possibilities are critical for big architectures.
Discovery
As you can imagine, discovery is the counterpart to registration from the point of view of clients. When a client wants to access a service, it must find out where the service is located (and other relevant information to perform the request).
Client-side discovery forces clients to query a discovery service before performing the actual requests. As happens with self-registration, this requires clients to deal with additional concerns other than their main objective. The discovery service may or may not be located behind the API gateway. If it is not located behind the gateway, balancing, authentication and other cross-cutting concerns may need to be re-implemented for the discovery service. Additionally, each client needs to know the fixed endpoint (or endpoints) to contact the discovery service. These are all disadvantages. The one big advantage is not having to code the necessary logic in the gateway system. Study this carefully when picking your discovery method.
Server-side discovery makes the API gateway handle the discovery of the right endpoint (or endpoints) for a request. This is normally used in bigger architectures. As all requests are directly sent to the gateway, all the benefits discussed in relation to it apply (see part 2). The gateway may also implement discovery caching, so that many requests may have lower latencies. The logic behind cache invalidation is specific to an implementation.
“Server-side discovery makes the API gateway handle the discovery of the right endpoint for a request.”
Tweet This
Example: A registry service
In part 2 we worked on a simple API gateway implementation. In that example we implemented dynamic dispatching of requests through queries to a service database. In other words, we implemented server-side discovery. For this example, we will extend our microservice architecture by working on the registration aspect. We will do so in two ways:
- By providing a simple registration library that any development team can integrate into their microservice to perform self-registration.
- By providing a sample systemd unit that registers a service during startup or shutdown (third-party registration using systemd as a service manager).
Why systemd? It has become the de-facto service manager in most Linux installations. There are other alternatives for managing your services but all require installation and configuration. For simplicity, we picked the one that comes preinstalled in most distros, and that is systemd.
A registration library
Our microservice example from previous posts was developed for node.js, so our library will be for it as well. Here is the main logic of our library:
module.exports.register = function(service, callback) { if(!validateService(service)) { callback(new Error("Invalid service")); } findExisting(service.name, function(err, found) { if(found) { callback(new Error("Existing service")); return; } var dbService = new Service({ name: service.name, url: service.url, endpoints: service.endpoints, authorizedRoles: service.authorizedRoles }); dbService.save(function(err) { callback(err); }); }); } module.exports.unregister = function(name, callback) { findExisting(name, function(err, found) { if(!found) { callback(new Error("Service not found")); return; } found.remove(function(err) { callback(err); }); }); }
Microservices that perform self-registration need to call these functions during startup or shutdown (including abnormal shutdowns). We have integrated this library into our existing microservice example in the following way (set the SELF_REGISTRY variable to any value to enable this function). Startup code:
// Standalone server setup var port = process.env.PORT || 3001; http.createServer(app).listen(port, function (err) { if (err) { logger.error(err); } else { logger.info('Listening on http://localhost:' + port); if(process.env.SELF_REGISTRY) { registry.register({ name: serviceName, url: '/tickets', endpoints: [ { type: 'http', url: 'http://127.0.0.1:' + port + '/tickets' } ], authorizedRoles: ['tickets-query'] }, function(err) { if(err) { logger.error(err); process.exit(); } }); } } });
And shutdown code:
function exitHandler() { if(process.env.SELF_REGISTRY) { registry.unregister(serviceName, function(err) { if(err) { logger.error(err); } process.exit(); }); } else { process.exit(); } } process.on('exit', exitHandler); process.on('SIGINT', exitHandler); process.on('SIGTERM', exitHandler); process.on('uncaughtException', exitHandler);
Third-party registration using systemd
Our gateway example reads service information from a Mongo database. Mongo provides a command-line interface that we can use to register services during startup or shutdown. Here is a sample systemd unit (remember to disable the SELF_REGISTRY environment variable if you are using the sample microservice from this post):
[Unit] Description=Sample tickets query microservice #Uncomment the following line when not running systemd in user mode #After=network.target [Service] #Uncomment the following line to run the service as a specific user #User=seba Environment="MONGO_URL=mongodb://127.0.0.1:27018/test" ExecStart=/usr/bin/node /home/seba/Projects/Ingadv/Auth0/blog-code/microservices/server.js ExecStartPost=/usr/bin/mongo --eval 'db.services.insert({"name": "Tickets Query Service", "url": "/tickets", "endpoints": [{"type": "http", "url": "http://127.0.0.1:3001/tickets"}], "authorizedRoles": ["tickets-query"] });' 127.0.0.1:27017/test ExecStopPost=/usr/bin/mongo --eval 'db.services.remove({"name": "Tickets Query Service"});' 127.0.0.1:27017/test [Install] WantedBy=default.target
Registration is handled by the ExecStartPost and ExecStopPost directives by calling the command-line Mongo client (included in all standard MongoDB installations).
Get the code.
Aside: use Auth0 for your microservices
Auth0 and microservices go hand-in-hand thanks to the magic of JWT. Check it out:
var express = require('express'); var app = express(); var jwt = require('express-jwt'); var jwtCheck = jwt({ secret: new Buffer('your-auth0-client-secret', 'base64'), audience: 'your-auth0-client-id' }); app.use('/api/path-you-want-to-protect', jwtCheck); // (...)
Your client id and client secret are available through the Auth0 dashboard. Create a new account and start hacking!
Conclusion
The service registry is an essential part of a microservice-based architecture. There are different ways of handling registration and discovery that fit different architectural complexities. Consider the pros and cons described above for each alternative before committing to one. In Part 4 we will study service dependencies in detail and how to manage them efficiently.
Related Documentation
About the author

Sebastian Peyrott
Senior Engineer