We believe that Auth0 Fine Grained Authorization (FGA) will fundamentally change how applications are going to be built over the next decade. At Okta, we aim to solve authorization for both application builders and workforce IT administrators, and FGA is a key piece of that strategy.
Scalability is crucial when designing a global-scale authorization system. It must be capable of delivering the performance and capacity expected from top-tier cloud services, like modern distributed databases. An authorization system capable of supporting a global scale must:
- Be highly available,
- Scale to support the most visited websites in the world,
- Provide low latency, as every millisecond you spend in authorization will impact the application’s overall latency,
- Be able to store a very large amount of data.
This Google Zanzibar paper describes how Google achieves those goals. We built FGA with these goals in mind, and our early tests of the Auth0 FGA validated that it could handle anything our beta and early access customers could throw at it.
As FGA gained traction among customers, we realized that we needed to push FGA even further to prove out this scale.
So, we decided to run a test with 1 million Requests per Second (RPS) and 100 billion relationship tuples to evaluate how the system behaves.
Auth0 FGA Primer : Model + Relationship Tuples
When implementing authorization using Auth0 FGA, you need to define an authorization model that describes the different entities in your system that are relevant when making authorization decisions and provide the data required to instantiate the model in the form of relationship tuples.
For example, in the model below, we define groups that can contain users, documents that can have an owner, and viewers that can point to specific users or all members of a specific group:
type user type group relations define member : [user] type document relations define owner : [user] define viewer : [user, group#member]
Relationship tuples would look like:
| user | relation | object |
|---|---|---|
| user:anne | member | group:marketing |
| user:peter | owner | document:sales-plan |
| group:marketing#member | viewer | document:sales-plan |
FGA defines an API method called Check() that will let you ask the system if a user is related to an object in a specific way.
For example, we can call Check(user:anne, viewer, document:sales-plan) and we’ll get “{ allowed: true }” as a result, given anne is a member of the marketing group, and their members are related to the sales-plan document as viewers.
If you want to learn more, check out how to model with Auth0 FGA here.
Modeling Authorization
When using FGA, the performance characteristics of a specific implementation will depend on the authorization model and relationship tuples in the system.
The flexibility of FGA means that customers with varying use cases, traffic, and business models are able to harness the full power of FGA. In initial implementations, we’ve seen that customers with a Business-to-Business (B2B) use case tend to have more complex models but with far fewer active users and less traffic. And we’ve seen that customers with a Business-to-Consumer (B2C) use case tend to have less complex requirements but with more data, active users, and traffic. We decided to target these B2C use cases for our performance testing since these are the businesses that are more likely to require a scale of 1 million RPS and 100 billion tuples.
We modeled a social network where users can post content and other users can interact with it. One example of this would be publishing a tweet and commenting on it. The model is described below:
type user relations # Users can have followers, can block specific users, # and can decide if they are visible to all users or just to their followers define _self: [user] define follower: [user] define blocked: [user] define visibility: [user:*, user#follower] define viewer: visibility but not blocked # User profiles can be viewed by the user itself or by the users who have access to their profile define can_view: _self or viewer type content relations # Content is owned by the user that published it define owner: [user] # The content can be visible for anyone or just their followers, for users that are not blocked, and by the owner itself define visibility: [user:*, user#follower] define viewer: visibility but not blocked from the owner define can_view: owner or viewer type interaction relations # Content iterations (e.g., comments) have a creator and a content piece as their parent define creator: [user] define parent: [content] # interactions can be viewed if the user can view the creator's profile and the content itself or if they are the creator of the interaction define viewer: can_view from creator and can_view from parent define can_view: creator or viewer
After defining the model, we had to decide how to distribute the relationship tuples in the system. We decided to use a Pareto distribution where:
- 20% of users are generating 80% of content, and 80% of users are generating 20% of content
- Similarly, 20% of users are doing 80% of the interaction, and 80% of users are doing 20% of the interaction
The tests focused on the Check() endpoint because this endpoint is the one that will be called more often and have the most impact on the customer's applications. We checked if a user is able to view specific content, a specific user profile, or a specific interaction (e.g., Check(user:john, can_view, interaction:1) ).
Modeling User Activity
Another critical decision point on how to perform the test was how to model user activity.
FGA has a cache that is set to 10 seconds. If we decide that a very small set of users is going to be active, we’d be able to serve all the requests from the cache. That would make it very easy to misrepresent the test results, as serving everything from memory would only happen in very specific use cases and won’t take into consideration the execution paths that require database access.
We decided to run the tests in three ways:
- Disabling the caches
- With a 50% cache ratio, which seems realistic based on what we observed as an average ratio across all of our customers.
- With a 75% cache ratio, assuming that for a specific customer, ratios can be higher.
One Million RPS and Beyond
We were very happy with the results and achieved the outcome we hoped for with only minor tweaks to the product.
We allocated three weeks to complete it, and most of the time was spent on generating the dataset, importing them into the database, and making sure we could launch all the clients that called FGA API.
We completed the test run in just two days without any significant adjustments in our code.
The tests ran for over 10 minutes and got 1.05M RPS. The images below are from our DataDog dashboard when we ran the tests with 0% cache ratio:
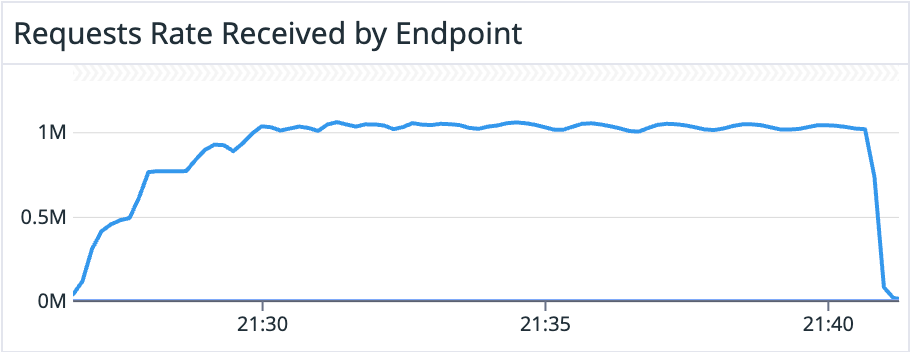
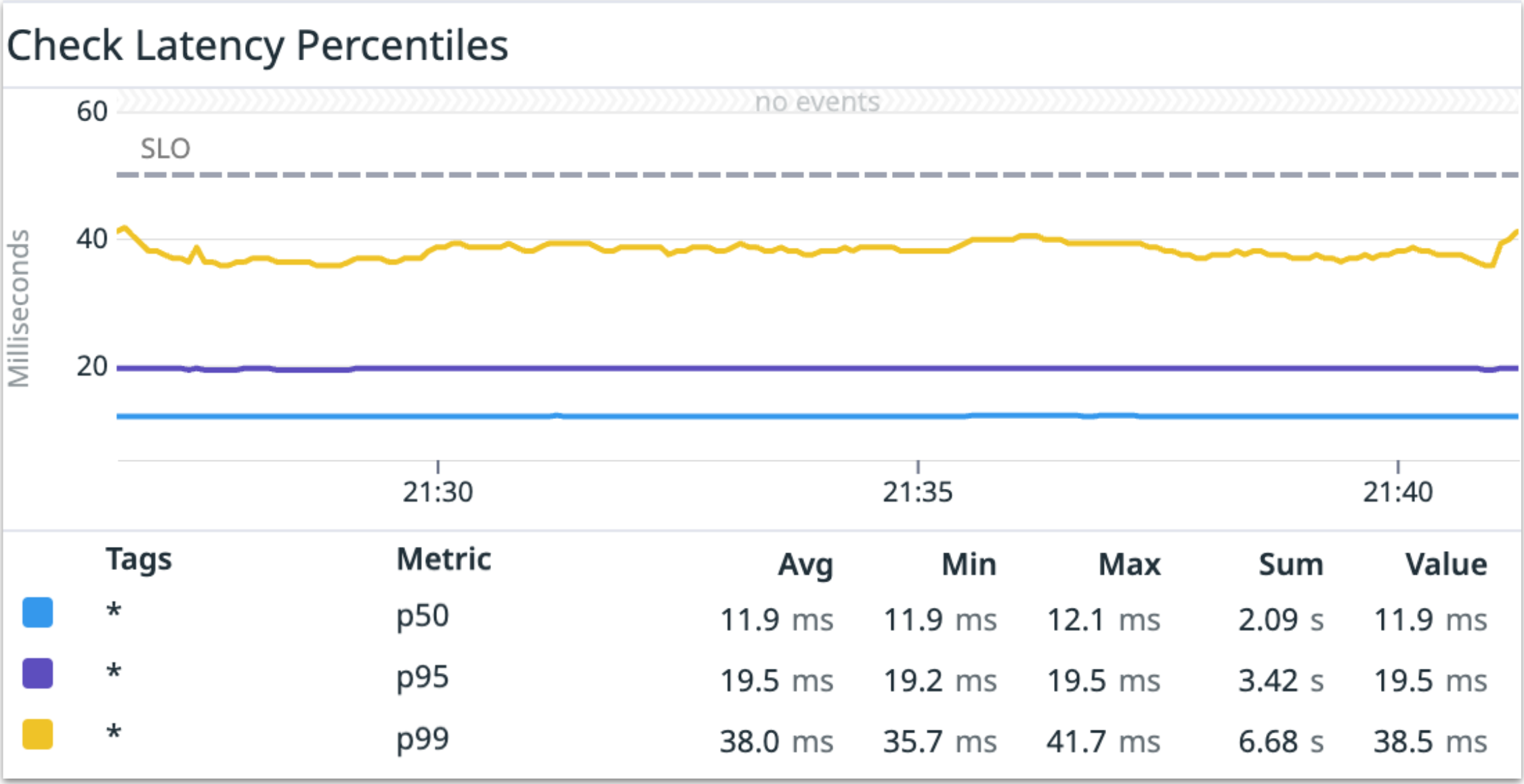
The metrics above show that 50% of the calls were completed in up to 11.9 ms, 95% were completed in less than 19.5 ms, and 99% of them were completed in less than 38.5 ms.
We incrementally increased the load while executing the test, and we saw the number of FGA instances increase linearly, maintaining the latency within the same range. We felt confident that we could go way beyond 1M RPS, but we had to stop somewhere 🙂.
When running the tests with caching, the latency decreased significantly, and the number of Auth0 FGA nodes running too:
| Cache Ratio | RPS per Auth0 FGA Instance (ECS Fargate 16 vCPU 32GB) | P95 Latency |
|---|---|---|
| 0% | 3,500 | 19.5 ms |
| 50% | 6,000 | 9.4 ms |
| 75% | 18,000 | 5 ms |
Auth0 FGA and You
We were thrilled to have tangible proof that FGA can support the global scale it was designed for. FGA provides a highly flexible, highly available, and scalable solution to implement authorization, supported by a company that is a trusted leader in the identity space.
You can try Auth0 FGA today by signing up for an evaluation account here. If you want to use it in production, you can apply to our Limited Early Access Program by reaching out to your technical account manager or account executive.
About the author

Andrés Aguiar
Director, Product Management
I’ve been at Auth0 since 2017. I’m currently working as a Director, Product Management for the Auth0 FGA and OpenFGA products. Previously, I worked in the teams that owned the Login and MFA flows.
I spent my entire 20+ year career building tools for developers, wearing different hats. When I'm not doing that, I enjoy spending time with my family, singing in a choir, cooking, or trying new kinds of local cheese.