
tl;dr: We created a node module to run two versions of a feature at once (original and new), compare the results, and always return the original results. It is useful in deploying new versions of features without breaking changes.
At Auth0, we move fast — I mean really fast. Last Friday alone (yes, Friday), we performed 14 deployments to production.
This is something I really like and a positive thing in general, as for example it allows us to do things like fixing production bugs in short timeframes. Shipping fast is great, but we can't do it recklessly, because stability and availability are core concerns for us. And I'm not just talking about our service, but also about the contracts we commit to in our APIs and SDKS. We never break compatibility, unless there's a security concern involved.
“Shipping fast is great, but we can't do it recklessly. Stability and availability are core concerns for us.”
Tweet This
To prevent issues, one option is to move slower. Another option is to start relying more on tools and automated tests to make sure that deployments do not introduce any breaking changes.
We settled on a hybrid approach. On the one hand, we host segregated production clusters with different release cadences. One of the clusters gets updated on every change we make, and the other one gets a batch update with a one day delay (approximately). On the other hand, we constantly improve the automated tests that run in our build server before each release, to include additional checks before new versions are deployed to production.
One tool we created is a node module named feature-change. We got the idea from a blog post by @holman explaining how GitHub moves fast & breaks nothing. I think it is best to tell you how it works using a real life example.
Example: Moving search from MongoDB to ElasticSearch
It all started with a new requirement from one of our customers:
Is there a way to search for users by field XYZ?
There wasn't, so we went ahead and implemented search against our small MongoDB instance. And all was good.
After that, we had a request from another customer:
Is there a way to search for users by field ABC?
Then, we had another request, so we decided to allow searching by any field, providing some sensible defaults for the common cases. For a while, this worked perfectly, but as our customer base (fortunately) grew, we realized MongoDB wasn't exactly built for this kind of thing.
For v2 of our API, we had learnt our lesson, so we did not allow searching against MongoDB. Instead, we relied on Elastic Search for this use case, which is working as expected so far.
However, some of our customers are still on v1 of our API. Some of their searches against MongoDB were really slow, affecting the database's stability. So, we decided to exactly replicate the v1 search functionality in ES to reduce the load on our database.
Introducing feature-change
We know a LOT of our customers rely on search, so we didn't want to introduce any issues with this change. For that purpose, we decided to take advantage of the idempotency property of a search operation to deploy a temporary version to production that did all of the following:
- Perform the search against MongoDB
- Perform the search against ES
- Compare the results and write them to our logs if there was a difference
- Always return the MongoDB result
Using feature-change, it looked like this:
var feature_change = require('feature-change'); var current_implementation = mongo_search; var new_implementation = es_search; feature_change(function(cb){ current_implementation(current_opts, cb); }, function(cb){ new_implementation(es_opts, cb); }, function(mongo_result, es_result){ // invoked when there is a difference in the results (useful for logging) }, function(err, result){ // this is the original callback we were using for mongo // err and result always come from mongo_search });
We ran this version in production for a couple of weeks and used our logging infrastructure (Kibana/ES) to log the differences. Kibana provides a very useful feature that allows you to create stack charts based on counts of a certain event. In the following chart, the blue part represents the relative percentage of differences compared to successful results. In other words, the blue bars show breaking changes, which we wanted to reduce.
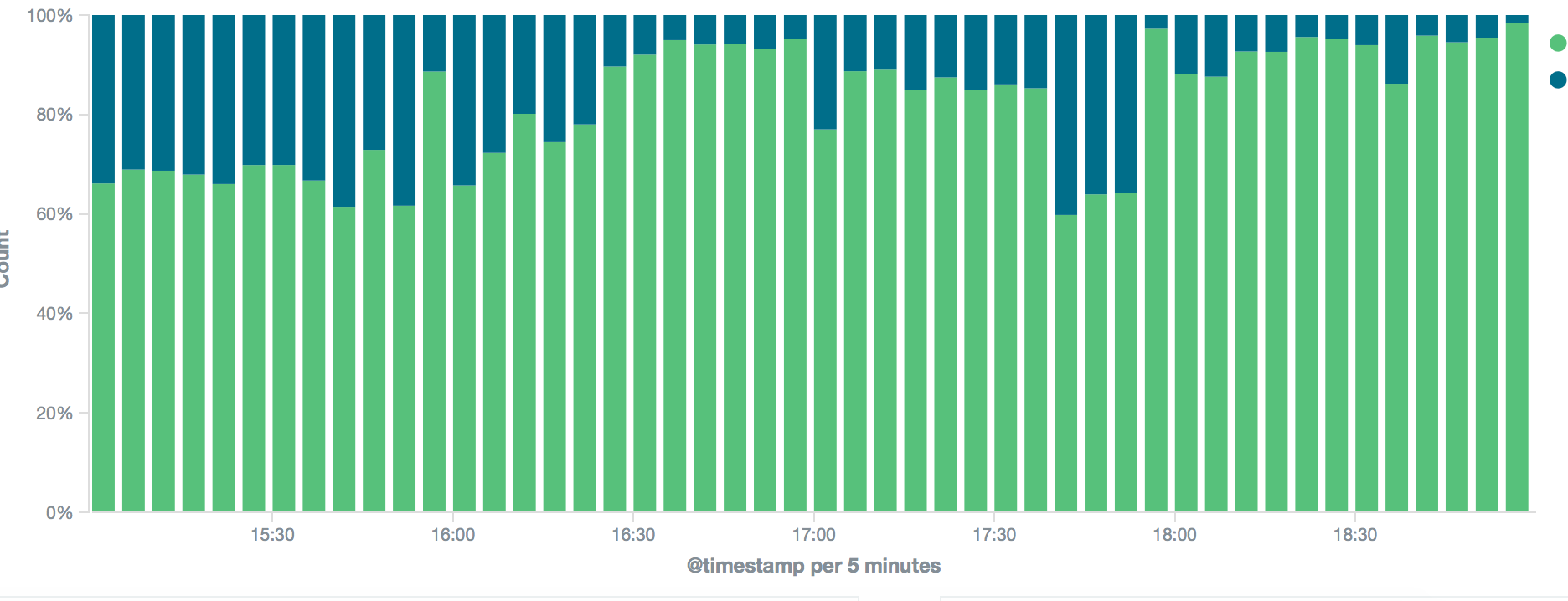
After fixing three different bugs we got rid of all the blue. We monitored the differences for a week to see if any new sources of errors appeared. When they didn't, we removed the code using feature-change and completely replaced MongoDB with ES in production.
feature-change is Open Source
We have open-sourced feature-change so you can use it in your own Node.js applications. Feel free to open issues, send PRs, etc.
About the author

Damian Schenkelman
VP R&D (Auth0Lab)
Damian was one of Auth0's earliest employees. He loves building products for developers and taking things from 0 to 1.
He played key roles in implementing product features and growing the engineering organization in the early stages, and later on defining Auth0's architecture for scale and creating new products. Today he helps shape Auth0's long term strategy and leads Auth0Lab, a small and amazing team doing research and development of forward-looking products.
He spends his spare time with family, and friends, exercising, and catching up on all things NBA.