Retrieval-Augmented Generation (RAG) is a great way to create AI-driven applications that deliver more accurate, context-rich answers. Instead of relying purely on pre-trained knowledge, a RAG system retrieves domain-specific data (like PDFs, knowledge bases, or markdown files) and passes it into a language model. This is awesome when your data is public or freely shareable. But what happens if some of that data is restricted or confidential? That’s where fine-grained authorization comes in!
In this post, we’ll walk through:
- Why authorization is crucial in RAG
- What OpenFGA is, and how it helps you enforce fine-grained permissions
- How to build a secure pipeline that filters out unauthorized documents before they reach your language model
The Challenge of Authorization in RAG Systems
RAG systems retrieve relevant information from large datasets and use that information to enhance the AI model responses. While this functionality is powerful, it raises a significant challenge: ensuring that each user only accesses the information they are authorized to see. Authorization must be:
- Accurate: Only correct data gets through.
- Performant: Works quickly, even with large datasets.
- Adaptive: Updates with dynamic organizational changes, role updates, or any changes in the relationship between the information and the users.
A secure RAG system needs to enforce fine-grained access control without sacrificing speed or scalability. Roles might change, projects can be reassigned, and permissions could evolve over time. Handling all this efficiently is key to building a truly secure and robust RAG application.
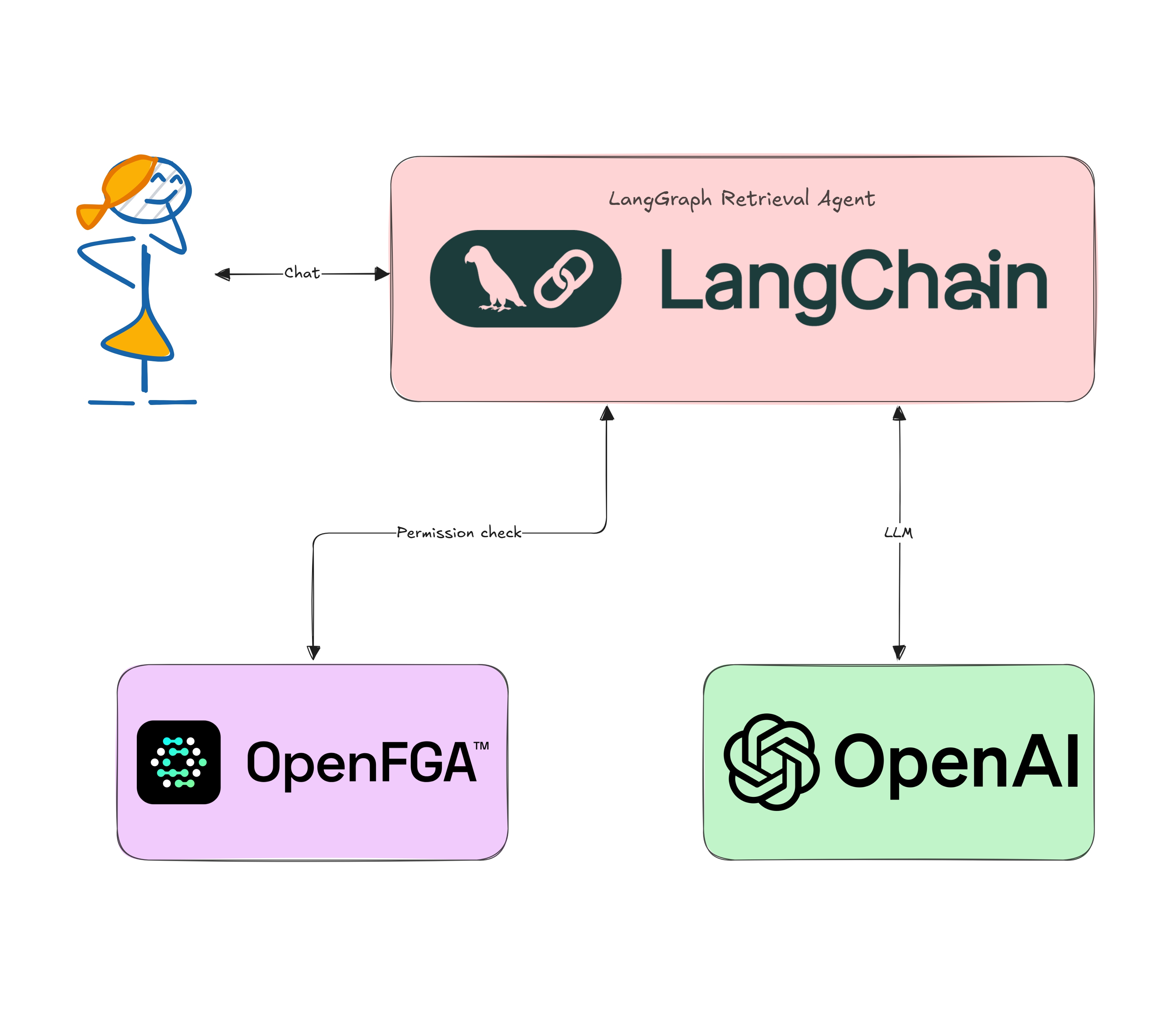
Proposed Solution: Secure Retrieval with LangChain, OpenAI, and OpenFGA
The solution employs a workflow that integrates document retrieval, user-specific authorization filtering, and Large Language Model (LLM) response generation.
We’ll build a pipeline that uses:
- LangChain: A helpful toolkit for chaining the steps of a RAG pipeline (loading data, embeddings, retrieval, prompting).
- LLMs (OpenAI or any other): For both embeddings (similarity search) and text generation.
- OpenFGA: A fine-grained authorization service that checks, for each document, if a user has the “can_view” relationship.
LangChain
LangChain is a library that streamlines building LLM applications by assembling different components—like loading documents, vector stores, and prompt templates. This structure makes it easier to read, maintain, and modify your RAG pipeline.
LLMs
Although we’ll demonstrate OpenAI’s embeddings and Chat APIs, you can easily replace them with other providers (e.g., Anthropic, LLaMA, or Azure OpenAI). The main tasks here are:
- Embedding documents so you can do similarity searches.
- Generating text from the retrieved documents to answer the user’s query.
FGA and Okta FGA
FGA (Fine-Grained Authorization) is about controlling who can do what with which resources, down to an individual level. In a typical role-based system, you might say, “Admins can see everything, and Regular Users can see some subset.” But in a real-world app—especially one that deals with many documents—this might not be flexible enough.
OpenFGA (and Okta FGA) addresses this by letting you define authorization relationships. The relationships defined in the authorization model can be either direct or indirect. Simply put, direct relationships are directly assigned between a consumer and a resource (we call them user and object) and stored in the database. Indirect relationships are the relationships we can infer based on the data and the authorization model.
If you would like to learn the basics of using FGA for RAG, check out this blog post on RAG and Access Control: Where Do You Start?.

Learn how to get started with Okta FGA for a RAG application.
Implementation: Step-by-Step
Below is a sample setup in Python. We’ll keep it simple so you can see the big picture. Feel free to adapt for your chosen LLM or a more robust data store.
Set Up Prerequisites
To follow this tutorial and secure your application, you’ll need the following:
- Python 3.8.1 or newer.
- An Okta FGA account. If you don’t have one, you can create one for free.
- An OpenAI account and API key.
Download and install the sample code
To get started, clone the auth0-ai-samples repository from GitHub:
git clone https://github.com/auth0-samples/auth0-ai-samples.git
cd auth0-ai-samples/authorization-for-rag/langchain-python
# Create a virtual env
python -m venv venv
# Activate the virtual env
source ./venv/bin/activate
# Install dependencies
pip install -r requirements.txt
The application is written in Python and is structured as follows:
main.py— The main entry point of the application, and it is where we define the RAG pipelinedocs/*.md— Sample markdown files to be used as context for the LLM. There are two types of docs, public and private. Private documents are only accessible to certain individuals.helpers/memory_store.py— Creates an in-memory vector store that acts as the base retriever in the chain.helpers/read_documents.py— Utility to read the markdown files from thedocsfolder.scripts/fga_init.py— Utility to initialize the OktaFGA authorization model and sample data.
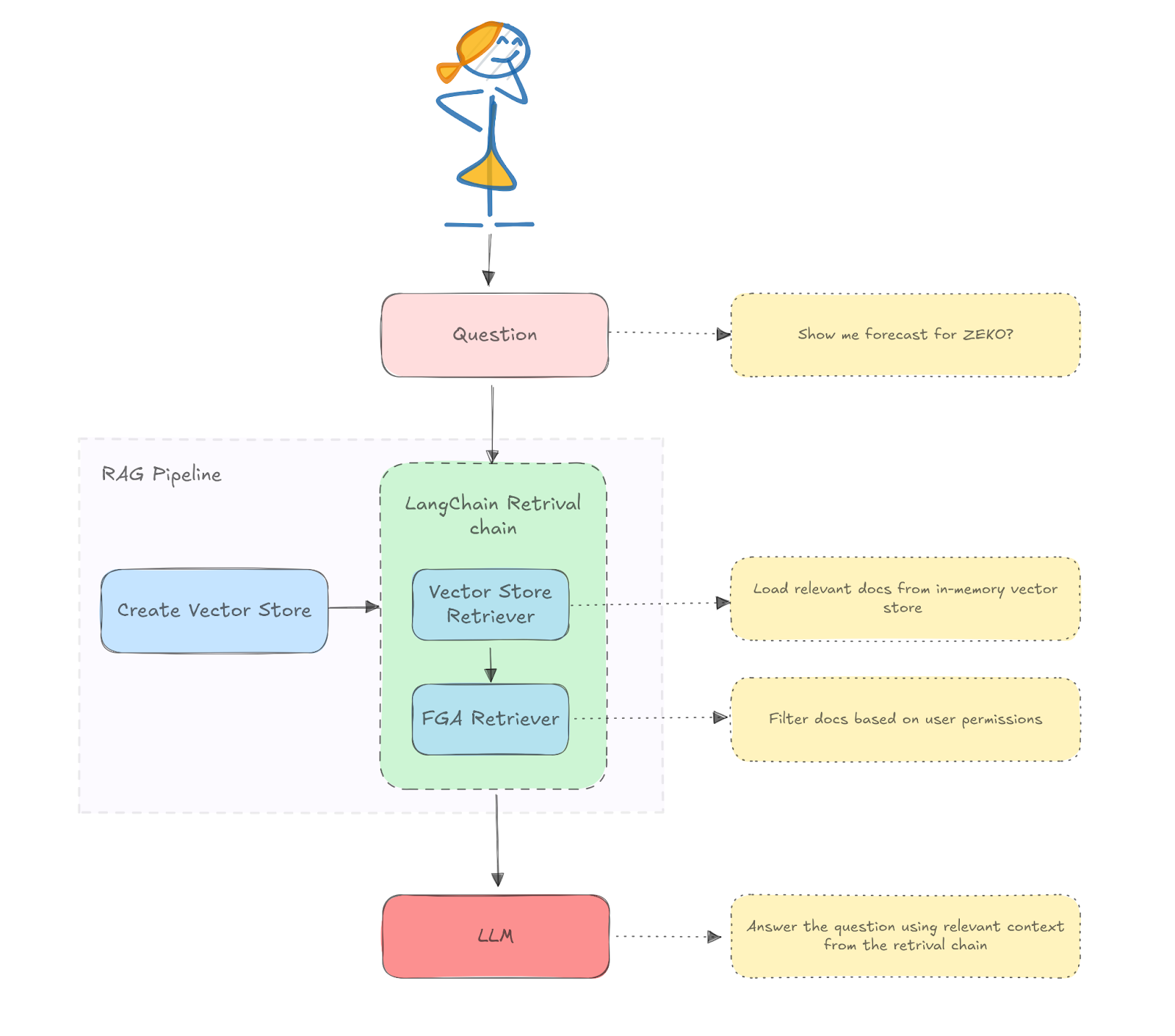
RAG Pipeline
The main.py file defines the RAG pipeline using Langchain to interact with the underlying LLM model and retrieve data from our context. In your project, your data may be sourced from different platforms and systems, make sure you check the proper documentation about loaders in the Langchain ecosystem.
The following diagram represents the RAG architecture we are defining:
Now let’s talk Python:
class RAG: def __init__(self): documents = read_documents() self.vector_store = MemoryStore.from_documents(documents) self.prompt = ChatPromptTemplate.from_template( """You are an assistant for question-answering tasks. Use the following pieces of retrieved context to answer the question. If you don't know the answer, just say that you don't know. Use three sentences maximum and keep the answer concise.\nQuestion: {question}\nContext: {context}\nAnswer:""" ) self.llm = ChatOpenAI(model="gpt-4o-mini") def query(self, user_id: str, question: str): chain = ( { "context": FGARetriever( retriever=self.vector_store.as_retriever(), build_query=lambda doc: ClientBatchCheckItem( user=f"user:{user_id}", object=f"doc:{doc.metadata.get('id')}", relation="viewer", ), ), "question": RunnablePassthrough(), } | self.prompt | self.llm | StrOutputParser() ) return chain.invoke(question)
Let’s break that down.
The RAG class first initializes a vector store and reads the documents using the helper functions. It also defines a system prompt for our use case and the LLM model in use, in our case, gpt-40-mini.
The class also defines a method query that builds the chain by piping the FGARetriever instance with the prompt and the LLM model. FGARetriever is provided by the Auth0 AI SDK for Python.
The FGARetriever is designed to abstract the base retriever from the FGA query logic. The build_query argument lets us specify how to query our FGA model, in this case, by asking if the user is a viewer of the document.
build_query=lambda doc: ClientBatchCheckItem( user=f"user:{user_id}", object=f"doc:{doc.metadata.get('id')}", relation="viewer", ),
With this design, you can plug any Langchain retriever, combined with checks for any FGA model query.
Create an OktaFGA Account
If you already have an Auth0 account, you can use the same credentials to log in to the Okta FGA dashboard at https://dashboard.fga.dev. If you don't have an Auth0 account, hop over to https://dashboard.fga.dev and create a free account.
Once you are logged in, you should see a dashboard similar to the one below.
When you log into the Okta FGA dashboard for the first time, you may be asked to create a new store. This store will serve as the home for your authorization model and all the data the engine requires to make authorization decisions. Simply pick a name and create your store to get started.
Create an OktaFGA Client
Once you are in the dashboard, you’ll need a client to make API calls to OktaFGA. To create a client, navigate to Settings, and in the Authorized Clients section, click Create Client. Give your client a name, mark all three client permissions, and then click Create.
When you create the client, OktaFGA will provide you with some data like a Store ID, a Client ID and a Client Secret. Don’t close that yet, you’ll need those values next.
At the root of the project, there’s a .env.example file. Copy the file and paste it as .env. Then, open the file and edit the three FGA-related variables with the values provided by OktaFGA. When you are ready, click continue, and the modal will display the values for the missing variables (FGA_API_URL and FGA_API_AUDIENCE).
At this step, you can also add your OpenAI API Key, which you’ll need to run the demo.
Configure the OktaFGA model
Now that the application is set up, you can run the provided script to initialize the model and some sample data. To set things up, run:
python ./scripts/fga_init.py
You can verify that the script worked by navigating to the model explorer page in OktaFGA. The following model should now have been created:
model
schema 1.1
type user
type doc
relations
define owner: [user]
define viewer: [user, user:*]
You can visit the OktaFGA documentation to learn more about modeling OktaFGA and creating an authorization model.
On top of the model, the script also created two tuples. Tuples in OktaFGA define the relationships between the types.
First, it defined a tuple to give all users access to the public doc:
- User :
user:* - Object :
public-doc - Relation :
viewer
Then, it created a second tuple to give the admin user access to the private doc:
- User :
user:admin - Object :
private-doc - Relation :
viewer
You can visit the OktaFGA documentation to learn more about tuples and how to create them.
Query the Chain
Invoke the chain to process a query and generate a response.
rag = RAG() question = "What is the forecast for ZEKO?" # Juan only has access to public docs response = rag.query("juan", question) print("Response to Juan:", response) # Admin has access to all docs response = rag.query("admin", question) print("Response to Admin:", response)
Fantastic! You now know how to build and scale a secure RAG with Python and LangChain. It’s time to test things out.
To run the chain, simply call the main.py file:
python main.py
If you follow the steps, you’ll see a response like the following:
Response to Juan: The retrieved context does not provide any specific forecast or predictions for ZEKO (Zeko Advanced Systems Inc.). It mainly outlines the company's mission, technologies, and products without detailing any financial or market forecasts. Therefore, I don't know the forecast for ZEKO.
Response to Admin: The forecast for Zeko Advanced Systems Inc. (ZEKO) for fiscal year 2025 is generally bearish. Projected revenue growth is expected to remain subdued at 2-3%, with net income growth projected at 1-2%, primarily due to margin pressures and competitive challenges. Investors should be cautious, given the potential headwinds the company faces.
As you can see, Juan couldn’t retrieve any “protected” data, while the user admin got an accurate response to the prompt.
Conclusion
You’ve seen how to build a secure RAG system that respects user permissions at the document level using OpenFGA. This approach prevents data leaks, meets security and compliance requirements, and stays flexible—perfect for businesses dealing with a large pool of sensitive information.
Feel free to adapt this flow for other vector stores, different LLM providers, or your own organizational rules. By coupling RAG’s retrieval power with fine-grained authorization, you’ll build AI-driven apps that are both insightful and safe.
Before you go, we have some great news to share: we are working on more content and sample apps in collaboration with amazing GenAI frameworks like LlamaIndex, LangChain, CrewAI, Vercel AI, and others.
Auth0 for AI Agents is our upcoming product to help you protect your user's information in GenAI-powered applications.
Make sure to join the Auth0 Lab Discord server to hear more and ask questions.
Happy coding!
About the author

Juan Cruz Martinez
Staff Developer Advocate