
You've probably stumbled onto websites that have password requirements: they might require a minimum number of characters, or perhaps a number and a symbol.
But does that really make a better password?
Despite their best intentions, policies lead people to choose horrible passwords. Evidence suggests that people are annoyed when such arbitrary measures are put in place and end up choosing weaker passwords.
This happens, in part, because most people don't know how their passwords are actually exploited. Even after many cries from the cybersecurity community, many people still believe swapping letters for a numerical equivalent ("l33t" speak) makes their password harder to crack (i.e., when the adversary has possession of a database of hashed passwords — an offline attack), when in fact it does nothing.
Users are then left with two problems: an insecure password and a false sense of security since the password looks complicated to them, but it's easy for a computer to crack.
By helping you understand how exactly passwords are cracked and the math behind it, you will be in a better position to create or instruct other people on how to create good passwords.
It's All in the Space
Let's say an attacker stole your credit card without you noticing and wants to withdraw money from your bank account. (Let's also assume the bank won't freeze your credit card after five or so failed attempts, as it's common practice today.)
And like most banks, let's assume your bank requires a 4-digit PIN to let you withdraw money from an ATM.
What are the chances that he guesses your password correctly, by pure chance?
Well, the first digit of your PIN can be any number between 0 and 9, so there are ten possibilities in total. Since there's no restriction in place for the second digit that would limit his choices (e.g., if you couldn't create a PIN with repeated numbers), there are also ten possibilities. And the same thing is valid for the third and fourth digits.
In total, there are 10 x 10 x 10 x 10 = 10,000 possible passwords, one of which is your password. The chance of an attacker correctly guessing your password by pure chance would be 1 out of a sample space of 10,000 passwords.
Now, this is not entirely true in practice because humans can't pull a number combination — or anything — out of their minds randomly. We are hostage to our brains' biases.
We tend to follow predictable patterns, even if it feels to us like we came up with random numbers: we tend to use sequential numbers, we are more likely to think in groups of two or four numbers because of our date system, etc.
What happens, in reality, is that a subset of those 10,000 possibilities happens much more frequently in the real world — 1234 or 1111 end up appearing way more than, say, 8065.
However, while it is pretty unlikely that the thief will have enough time to type in 10,000 combinations in an ATM, a regular computer today can make tens of billions of attempts per second. A 4-digit PIN would be cracked instantly.
To make it as hard as possible to crack your password, you have to increase its sample space as much as possible (it's harder to guess the correct password out of a trillion possibilities than a thousand possibilities).
How to Calculate the Sample Space of Your Password?
If you look back at our example, you'll see that we calculated the sample space by multiplying the number of allowed characters for each digit allowed. We had ten valid characters as input for each digit, so 10 x 10 x 10 x 10 or 10^4.
To calculate the sample space of a password, we can use the following formula: S = C ^ N.
Where S is the total number of possible passwords, the sample space, C is the number of characters in the pool of characters available to us, and N is the number of characters our password has.
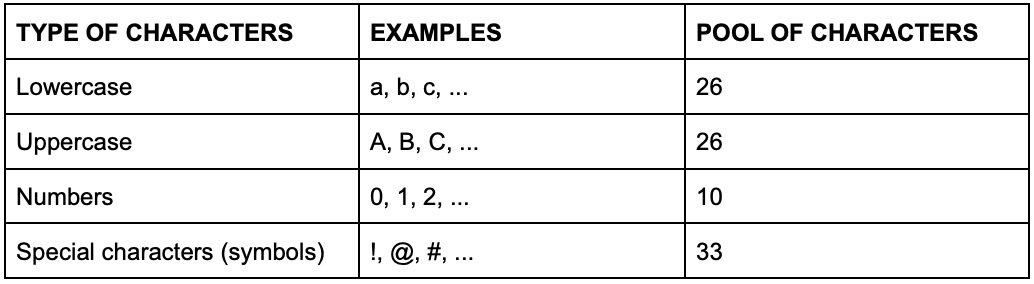
If you choose a password that only has lowercase letters, then C = 26; if it has lowercase and at least one uppercase, then C= 52, and so forth.
Let's compare different passwords and see how their sample space compare with each other:
Example: czvpgp
C = 26 (lowercase only)
N=6
S = 308,915,776 or about 309 million passwords combinations
Let's see what happens if we introduce all other characters type and leave the length at 6 characters:
Example: -@}"Bt=:6
C = 95
N=6
S = 735,091,890,625 or about 735 billion password combinations
Now let's see what happens if we use only lowercase letters but increase the length to 15 characters:
Example: tuubbxvhyexmgow
C = 26
N = 15
S = 1,677,259,342,285,725,925,376 or about 1.7 million million billion passwords,
approximately 2.28 billion times greater than -@}"Bt=:6, our last example.
We can see here that what makes a password hard to crack is not whether it has symbols or not, or numbers or not, but its sample space. You can make the sample space bigger with length or with more characters. The bigger the sample space is, the harder it is to crack the password.
We'll have a look at which option is preferred when we talk about crafting a great password in the next part of this article.
Measuring Password Strength: Entropy
It's very hard to quantify exactly how difficult a password is to crack without knowing how it was generated (e.g., randomly or by a human) due to the biases we talked about earlier.
But it's very useful having a number that tells us at a glance whether password A is harder to crack than B, and that number is expressed in bits of entropy.
Think of entropy as a measure of how big is the sample space that a particular password was taken from. High entropy is harder to crack; low entropy is easier to crack.
Note: when you think of a decimal digit, there are ten possibilities (0 through 9). In a binary digit, a bit, there are only 2 (0 and 1), so a bit represents a space of 2 possibilities.
A bit represents a sample space of 2 possibilities, so an entropy of 50 bits represents a space of 2 x 2 x 2 x 2... = 2^50 possibilities (similar to how our 4-digit PIN represented a space of 10^4 possibilities).
A password with 50 bits of entropy is said to be drawn uniformly from 2^50 possible distinct passwords. A password of 51 bits is drawn from a sample space of 2^51, which means it's twice as hard to crack as a 50-bit password.
To calculate the entropy of a password, you have to calculate the size of the sample space of a password using the formula we saw above and then convert it to "power of two notation" (which is how bits are represented) using the following formula:
S=2n ⇔log2S=n
So, if the password was generated uniformly and randomly, the entropy can show you at a glance how many tries it would take to brute force your password.
It's worth noting that while it would take 2^50 attempts to go through all possibilities of a password with 50 bits of entropy, a brute force attack probably wouldn't need to go through all combinations to eventually land on the right one.
So when assessing the strength of a password, we consider the "expected number of guesses" instead: how many guesses it takes to have a 50% chance of guessing the password. In the case of a 50-bit password, that means 2^49 guesses.
High Entropy Is Not Enough
The problem with using entropy as a measure of password strength is that it works for as long as all the possibilities have the same chance of being the correct one.
If a human is tasked with creating an 8-character, lowercase-only password, then a password like a password would be way more likely to come up than vcwcyqyu – but we don't know how much more likely. This heavily skews the probabilities and makes it very difficult to estimate the password's real entropy.
That's why we can't just consider the size of the sample space to calculate the entropy.
There are solutions at the disposal of developers to warn users of such risks; two well-known being Have I Been Pwned (HIBP) and zxcvbn.
HIBP aggregates known password breaches into a database that services can check against. That way, developers can notify the users that their password has been compromised as soon as a new breach is added to the database or even when the user is first signing up for the service.
Naturally, a shortcoming of HIBP is that it's a "hard" penalty: you can only flag bad passwords if they appeared in a breach at some point. But it doesn't take into consideration the biases we talked about before. Zxcvbn tries to address by weighing and penalizing different patterns: common names, dates, keyboard patterns, etc.
What's a Password Hashing Algorithm?
If webmasters stored the passwords in plain text on their server and an attacker managed to get access to it, they would have the passwords straight away, no matter how strong they are.
That is why it's highly recommended that passwords are salted and hashed before being stored. Instead of the password itself being stored, we compute a "fingerprint" of the passwords, generated by a hashing function, and store that hash.
Hashing functions are pseudo-random, one-way functions that make it computationally infeasible to "reverse engineer" the password from the hash (i.e., the "fingerprint), and there are many algorithms we can choose from to compute these hashes.
For example, here's the SHA-1 hash for czvpgp, our first password from the previous section: b5162e4e38acb4a04120aa6efdd4b4ae9c699935.
And here's the SHA-1 hash for 8065: 1797dff2748ea5c11e32e3de845673b96c1b89fa.
Now, SHA-1 is not a good enough algorithm for today's standards, and you should never use it to store passwords – you have better options at your disposal, like bcrypt.
However, from a defensive standpoint, you can't assume that your passwords are always going to be hashed with bcrypt, and SHA-1 is still common-enough that you will have to "defend" against it. For that reason, we're going to assume a worst-case scenario and proceed using SHA-1 as an example.
So, going back to the scenario we laid out above: the attacker would have a list of hashes instead of passwords. But if hashes can't be reversed, how are passwords cracked?
How Passwords Are Cracked
We know that it's impossible to solve the hash back to it's plain text form. But what you can do, however, is to hash every single possible password of that sample space and see if their hashes match up with your target. If they do, then you cracked their password.
Now, it takes some computational power to hash these passwords, and some hashing functions are more computationally intensive (harder to compute) than others, making them more time-consuming (sometimes, infinitely more) to crack.
That is why SHA-1 is a poor choice: computers today can calculate SHA-1 hashes too quickly. An attacker can go through a list of SHA-1 hashes much faster than they would if it were a dump of bcrypt hashes, for example.
Like I explained earlier, the bigger the sample space of your password, the more possibilities your attacker has to try hashing before he finds the correct one — in some cases making the attack infeasible (e.g., so big it would take hundreds of thousands of years to crack).
This is called a brute force attack. The attacker is trying to guess the correct password at random out of the possible passwords on the sample space.
However, this method is not very common because it's incredibly inefficient. It's only really useful if your password is very short — say, shorter than eight characters, or if the attacker knows you used a limited set of characters (e.g., only numbers, etc.).
For longer passwords, attackers have to make some assumptions about the way people make passwords. Like I mentioned, in the vast majority of cases, our choices are weighted towards certain tendencies of human behavior.
They create a dictionary of commonly used words, patterns, and passwords, like password, and then try those and see if the hashes match up. And then they manipulate it slightly, like passw0rd, and then try those. And then we append words and try once again. This process makes guessing the correct combination insurmountably easier.
It's for this reason that Password1, from a brute force standpoint, would be a slightly above average password; it has nine characters and 62 characters possibilities and a theoretical entropy of around 53 bits.
But in reality, it's a horrible password because it's a variant of one of the most common passwords out there. If you were using a password strength estimation tool that accounted for common passwords, a password like that would receive a nasty penalty; probably down to 0 bits of entropy.
These attacks are called dictionary attacks. Instead of brute force blindly, we use computational power to create variations on top of words people are most likely to use: words they know or passwords used before by other people.
That's why data breaches are so valuable: they not only provide private information that criminals can use for malicious purposes — extortion or social engineering — they also provide the best dictionary possible: actual passwords people are using!
Time to Crack
As we've learned by now, the whole point of choosing a hard password to crack is to create a password that would take so much time to crack it wouldn't be worth it — something like 900 million years.
And how do we know much time it would take to crack your password? Well, it depends on a few variables: the hash rate of your attacker's computer (how many hashes it can calculate per second), the attack mode used, the hashing algorithm used, etcetera.
A motivated individual with consumer-grade gear could put together a cluster capable of 170 billion unsalted SHA-1 (the same used by LinkedIn at the time of their infamous leak) hashes per second.
To estimate how much time it would take to crack your password, use the following formula:
T = S/(A*6.308*10^7) (in years)
Where S is the sample space and A is the number of attempts per second. This number will change with your hardware.
A great place to estimate hash rates for different hashing functions is Hashcat's forum. Hashcat is a software dedicated to cracking passwords, and users frequently post benchmarks along with their computer's specs.
Naturally, this is assuming the attacker doesn't have access to enterprise-level or state-sponsored clusters; those have a much higher hash rate. (In 2013, Snowden suggested the NSA could make 1 trillion attempts per second.)
To give you an idea, assuming you generated a password completely randomly, here's how much time it takes to crack passwords of different entropies with 170 billion attempts per second:
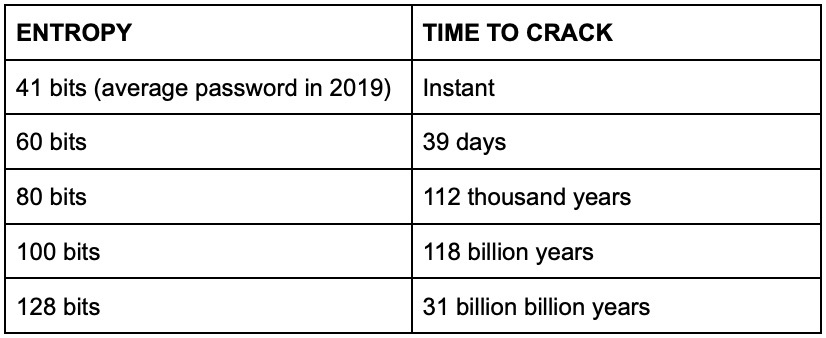
As you can see, things get out of hand for the attacker pretty quickly. But one of the caveats when it comes to estimating time to crack is that we make calculations with components available today.
What if technologies advance so rapidly that in 5 years' time, it would be trivial to crack an 80 or 100-bit password?
In 1975, Gordon Moore, co-founder of Intel, stated that the number of transistors in chips would double every two years.
Even though transistors in a chip don't equate to raw processing power, they are strongly correlated. Later dubbed Moore's Law, it was able to predict with great accuracy what ended up happening in the following years up until today. However, experts, including Moore himself, believe that we are reaching a fundamental limit and predict Moore's Law will end by 2025.
With all that said, how much entropy is enough entropy to make you secure for years to come? Is more entropy always better? Can you avoid the pitfalls of excessively complicated passwords and still be safe? What if you don't like or can't remember the long and complicated strings password managers generate?
All those questions are answered in the second part of this series, How to Create Great Passwords: Entropy, Diceware, and More.
About the author

Arthur Bellore
Cybersec Writer