
Cloud adoption is occurring at a rapid pace and so are the risks and challenges in maintaining those secured environments. Doing it at scale requires the extensive use of automation and tooling. DevSecOps methodologies can also be applied to the detection and response of threats, decreasing the time to respond and preventing potential breaches. Logging pipelines, Slack bots, orchestration tools, and serverless technologies empower operation teams in a way that traditional security operations centers (SOC) can’t. Services such as AWS GuardDuty provide indispensable threat detection to continuously monitor for malicious activity and unauthorized access on cloud resources.
At Auth0, we have embraced the cloud since our inception, and with cloud resources in numerous AWS accounts in our organization, strong defenses and timely response to security events in the cloud are an absolute priority for us. That is why our Detection and Response team has embraced technologies to automate the response to security events in the cloud to scale for our future organizational growth.
In this blog, we will provide an overview of the implemented architecture for the alert analysis, triage, user notification, and automated response of the AWS GuardDuty security findings on all of our AWS accounts.
AWS GuardDuty Service
Amazon GuardDuty is a threat detection paid service that continuously monitors for malicious activity and unauthorized behavior on AWS accounts and workloads. The service consumes CloudTrail, VPC Flow, and DNS logs and then enriches them with threat intel from AWS and other third-party services (such as CrowdStrike). GuardDuty also uses machine learning techniques to detect malicious activity on an AWS account. The service is regional (needs to be enabled on a per-region basis) and has a 30-day free trial. GuardDuty findings, if any, will start populating just a few minutes after the service is enabled.
At Auth0, we enable the GuardDuty service at account creation in all regions. Configuration follows a master/member setup where every new AWS account becomes a new member of the master GuardDuty account. From there, a combination of regional CloudWatch event rules and AWS Lambda functions ships all GuardDuty events into our security information and event management (SIEM) system.
We also monitor the health of this ecosystem closely as any failure would mean a critical gap in our alerting systems. As an example, we monitor specific GuardDuty API calls (such as Disassociate, StopMonitoring, DeleteDetector, and many more) that could tamper with our infrastructure resulting in a page notification to our team.
Also, we have subscribed to the GuardDuty Announcements SNS Topic and integrated the alerts with our bot, so we get Slack notifications when there are new GuardDuty findings or updates to the existing ones that require our attention.
SecurityBot
At Auth0, we rely heavily on Slack as our main communication channel. On top of it, we have created Slack Bots that can automate our common tasks and help us scale and better respond to security events.
One of those bots is the SecurityBot, developed by the Detection and Response team on top of our Security Orchestration, Automation, and Response (SOAR) system. Auth0’s SecurityBot was inspired by the awesome work of the security teams at both Slack and Dropbox. The SecurityBot helps us in two main tasks:
As a ChatOps function, we can ask the bot to create an incident response channel, add all necessary members to it, initiate the documentation for an incident, or perform an investigation on specific IPs and Domains.
As our main channel to communicate with employees. The bot can send notifications or inquiry messages (that require a confirmation) to our employees, ask for MFA confirmation, or even page our team if an employee responds negatively to a specific event.
AWS Incident Response Tool (aws-ir)
Especially important when dealing with an incident is to have a timely response. For that reason, our team has developed an internal tool to make investigation and response on AWS a much easier and repeatable task.
AWS IR is an API built on a serverless infrastructure that allows our team to take necessary forensic artifacts and response options on a specific machine in any of our AWS accounts. Those actions are mainly:
Take a snapshot of the instance volume.
Run a set of osquery commands.
Take a memory dump.
Take a
tcpdumpof the network traffic.Isolate an instance.
We have integrated this tool with the response to GuardDuty events so we can collect artifacts and perform response actions depending on the severity of the alerts.
The Hive Project
Keeping records for the actions taken and the artifacts collected is sometimes a “boring” but necessary task to do while performing a response to an incident. The Hive Project is our main ticketing and artifacts collection platform that we use to perform our investigations.
We rely on its APIs to create alerts, promote them to cases, and to upload the artifacts that we automatically collect.
Automating the Response Like a Pro
Now that we have explained all the different elements that compose our architecture let’s see how we glue them together.
We partner with the security automation company Tines in this regard. Every alert from our detection stack, whether it’s from SIEM, GuardDuty, Phishing, or custom tooling we’ve built, first goes through Tines where it is enriched, prioritized, and ticketed. We also use Tines to automate the response to the GuardDuty alerts.
One of the most common observations after enabling GuardDuty is that it can be daunting at the beginning and that it requires a significant amount of time to tune it to make it serviceable for your environment. Let’s take a look at a few examples of what this tuning looks like and some associated caveats:
Network Load Balancer: Port Probe Alert False Positives
Receiving a GuardDuty event of an instance which have a random port that is being probed by a malicious IP from the internet can be concerning. But the story changes if the instance has no public IP, and is behind a load balancer which has port 443 open to the internet. The reason for this is that the Network Load Balancer, by default, offers "Source IP Preservation" and the source IP addresses of the clients are preserved and provided to your backend applications. This is documented in the following public article as well. Later we will discuss how we have overcome this limitation when making changes on the load balancer is not an option.
Alerting on harmless customer provided domains
If your service takes or ingests domains supplied by your customers and queries them (as is the case for us), GuardDuty can flag some of this legit activity as malicious. We encountered false positive "Backdoor and Trojan" alerts that happened due to customers providing flagged domains into our service.
Detecting anomalies while employees are on the move
Machine learning is great, and we definitely believe in this technology for detection purposes (we want to further expand on this technology for our own sake). Still, it doesn’t cope well on a remote-friendly company where employees are on the move, continuously changing their locations and source IPs.
GuardDuty events for already terminated EC2 Instances
We have received GuardDuty events where the instance state is “terminated” (this information is contained on the GuardDuty event). On an ephemeral infrastructure where instances are spun up and torn down on demand, and there are no long-running services, this can limit our capabilities to respond to incidents or to perform live investigations.
Visibility gaps in cloud environments
There is a lack of visibility for Digital Forensics and Incident Response (DFIR) with GuardDuty for containers/microservices, especially if they are running on the same EC2 instance. Alerts will come from the same EC2, and additional logging/tooling will be needed to respond to those alerts.
“Learn how to tune GuardDuty to make it serviceable for your environment and the associated caveats.”
Tweet This
So let’s dig deeper into how we have automated the response for those GuardDuty findings and overcome some of those challenges. We have grouped the different GuardDuty events and their responses mostly into four different categories:
EC2 PortProbe alerts
IAM User non-critical alerts
IAM User critical alerts
EC2 Other alerts
Let's go over the response for each of them.
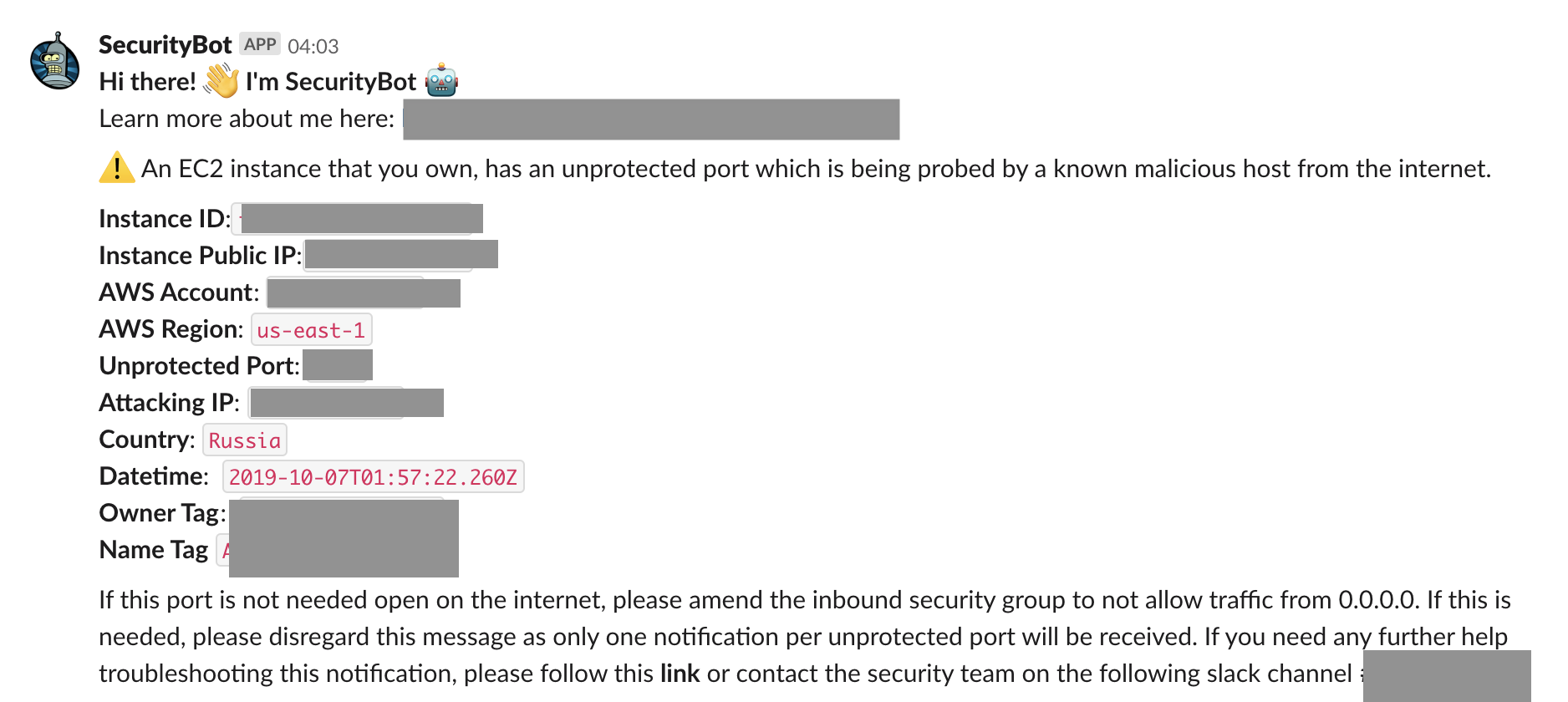
PortProbe Alerts
The first group of alerts involves inbound port probing, which means potentially malicious IPs probing ports that are open on the internet. We do have PortProbe type of events (Recon:EC2/PortProbeUnprotectedPort) and also SSH and RDP brute force events included in this group.
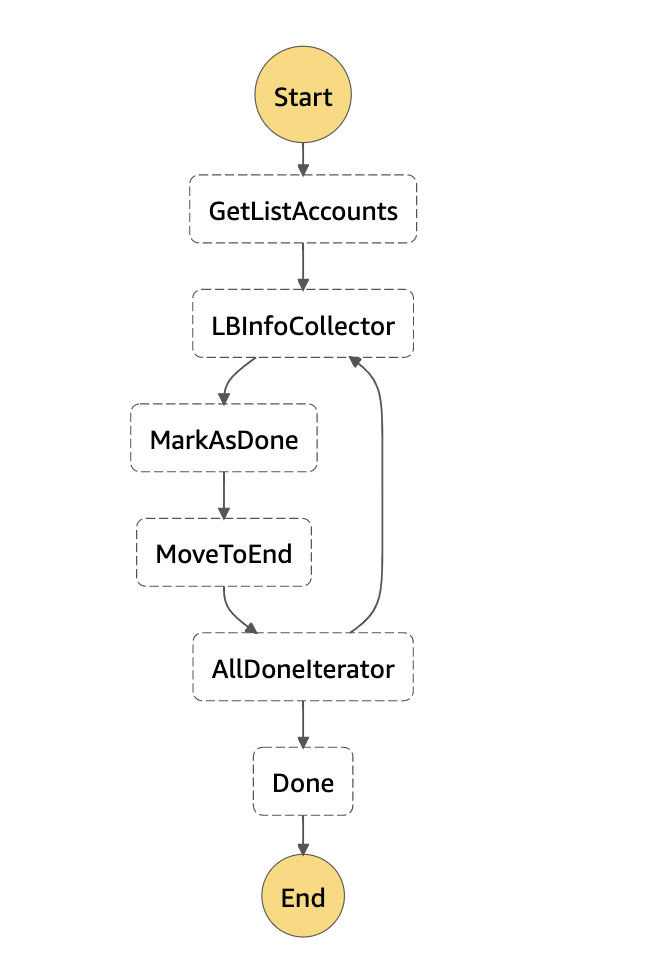
Initially, we filter out common ports that we know are open and are commonly attacked (for example, port 443). Also, as mentioned before, we do not want instances that are behind a network load balancer to trigger events if the load balancer is opening common ports such as 443. For that reason, we have built an AWS Step function that maps network load balancer ports against instance ports and dumps this information on a DynamoDB database. From Tines, we query the database to filter out alerts on instances behind a network load balancer from which the listening port is 80 or 443.
Finally, if the event is not filtered and has not been notified before, we send a notification via SecurityBot to the resource owner (based on Instance tags).
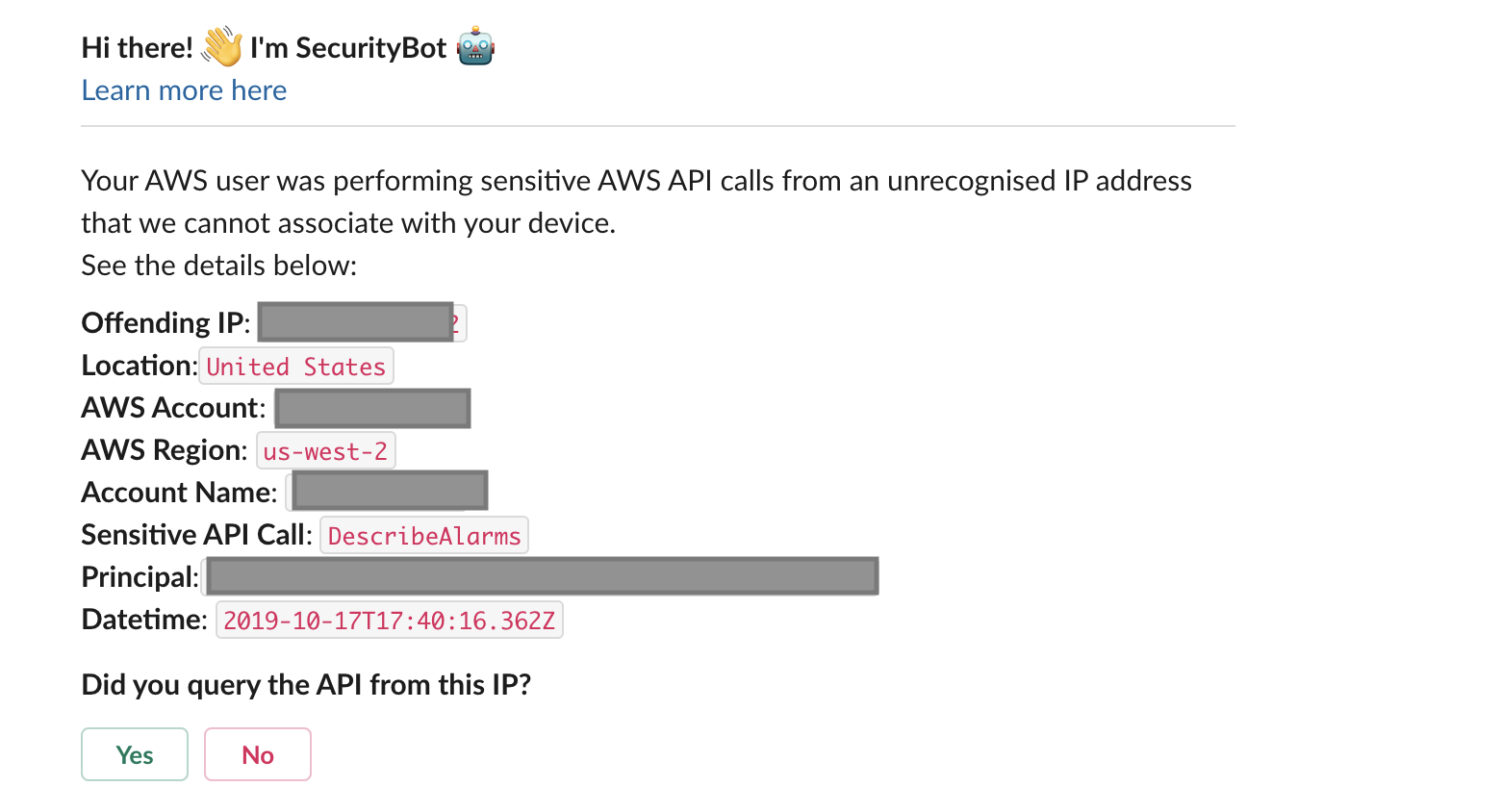
IAM User Non-Critical Alerts
In this group, we cover GuardDuty IAMUser events that we have deemed non-critical. These events typically suggest suspicious API calls made by AWS principals. Our main action with those alerts is to first automatically determine the mapping of the Principal to an employee and their endpoint machine. From there, we check their device IP and compare it to the IP in the alert. If there is any mismatch, we trigger a SecurityBot Inquiry message to ask the employee for confirmation that they made the AWS API call.
IAM User Critical Alerts
In this group, we cover the GuardDuty IAMUser events that we have deemed critical, and as such, they trigger a PagerDuty alert to our team. These events include modification to CloudTrail, password policy changes, credential exfiltration, or the latest S3 specific alerts among others.
We also enrich the alerts with the following information:
List of employees seen under the same offending IP over the last 24 hours
CloudTrail API calls made by the offending IP
EC2 Alerts
Within this group, we have the following event types:
EC2 Outbound network connection
EC2 DNS request
EC2 PortScanning
There is an important filtering layer that we needed to implement for our network scanner, and also for services that query customer provided domains which caused false positives to trigger. We initiate the AWS Incident Response tool to collect specific artifacts on the instance so we can better perform timely forensics investigation on the machines.
“Dig deep into how Auth0 has automated the response to GuardDuty events and the associated challenges.”
Tweet This
Conclusions
We have no doubt as to the incredible value and visibility the AWS GuardDuty service provides to our team. Enabling it is incredibly simple, and we have decided to include it on each of our AWS accounts.
Automating our response to the GuardDuty alerts has helped us focus on what is important to us, filtering out some of the noise it generates and customizing it to our environments. We have evolved from processing hundreds of GuardDuty events per week (that would completely consume our team’s time to review and respond to these alerts) into just a few events per week needing our manual review. To add to this, with SecurityBot, we empower our employees to provide valuable real-time data relating to potential security incidents, making them aware of the alerts and also adding them to the front line of our security team.
For future work, we will continue to improve the automation for our incident response process. We also want to include other sources of information into our alerts, such as the events provided by agents like osquery or information specific to containers and Kubernetes infrastructures. On top of that, we will expand our threat model to include attacks vectors such as compromised employee machines, malicious insiders, etc.
About Auth0
Auth0 by Okta takes a modern approach to customer identity and enables organizations to provide secure access to any application, for any user. Auth0 is a highly customizable platform that is as simple as development teams want, and as flexible as they need. Safeguarding billions of login transactions each month, Auth0 delivers convenience, privacy, and security so customers can focus on innovation. For more information, visit https://auth0.com.
About the author

Alejandro Ortuno
Security Engineer (Auth0 Alumni)