本記事は 2025年3月12日 に更新された「Building a Secure RAG with Python, LangChain, and OpenFGA」を機械翻訳した記事です。
検索拡張生成 (RAG) は、より正確でコンテキストに応じた回答を提供する AI アプリケーションを作成するための優れた方法です。事前にトレーニングされた知識だけに頼るのではなく、RAG はドメイン固有のデータ (PDF、ナレッジベース、Markdown ファイルなど) を取得し、言語モデルに渡します。データが公開されているか、自由に共有できる場合に非常に効果的です。しかし、一部のデータが 制限付き または 機密 である場合はどうでしょうか。そこで、きめ細かな認可が重要になります。
本記事では、以下について説明します。:
- Why RAG において認可が重要である 理由。
- What OpenFGA とは 何か、きめ細かな認可の実装にどのように役立つか。
- How ユーザが権限を持たないドキュメントが言語モデルに到達する前にフィルタリングして、セキュアなパイプラインを構築する方法。
RAG における認可の課題
RAG は大規模なデータセットから関連情報を取得して、AI モデルの応答を改善します。この機能は強力ですが、重大な課題も引き起こします。それは、各ユーザーが閲覧を許可された情報にのみアクセスできるように保証することです。 認可は、以下を満たす必要があります。:
- 正確: 正しいデータのみが通過すること。
- 高性能: 大規模なデータセットでも迅速に動作すること。
- 適応性: 動的な組織変更、役割の更新、または情報とユーザー間の関係におけるあらゆる変更に対応して更新されること。
速度やスケーラビリティを犠牲にすることなく、RAG を安全にするにはきめ細かなアクセス制御の適用が効果的です。時間とともに、ロールは変更されたり、プロジェクトは再割り当てされたり、権限は変化したりする可能性があります。これらすべてを効率的に処理することが、真に安全で堅牢な RAG アプリケーションを構築するための鍵となります。
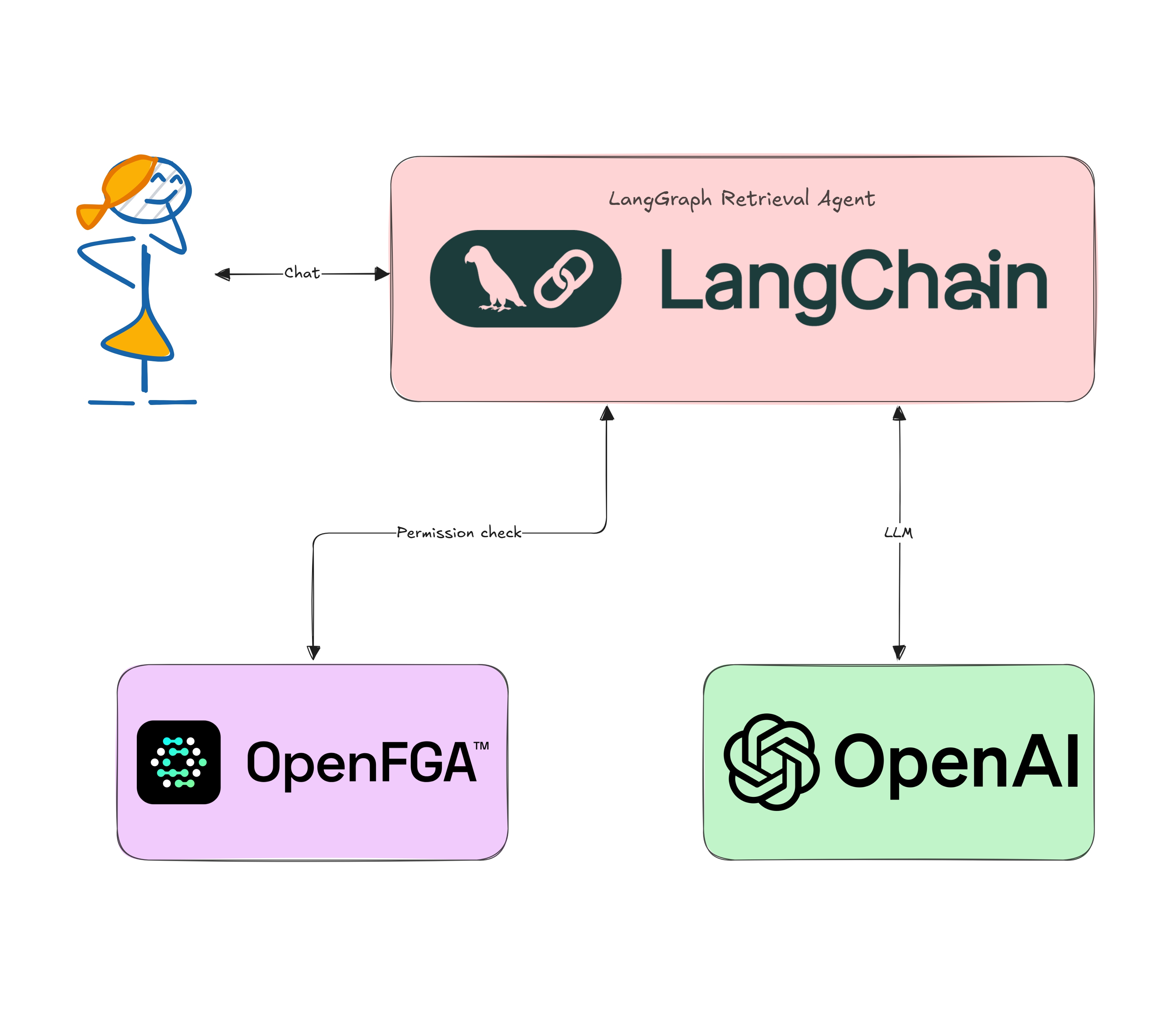
ソリューション提案: LangChain 、OpenAI 、OpenFGA によるセキュアな検索
このソリューションでは、ドキュメントを検索し、特定のユーザー権限に基づいてフィルターをかけ、大規模言語モデル (LLM) と組み合わせて応答を生成するワークフローを作成します。
以下を使用するパイプラインを構築します。:
- LangChain: パイプラインの各ステップ (データの読み込み、埋め込み (Embedding)、検索、プロンプト作成) を繋いで処理するための便利なツールキットです。
- LLM (OpenAI またはその他): 埋め込み (類似性検索のため) とテキスト生成の両方に使用します。
- OpenFGA: 各ドキュメントに対してユーザーが “can_view” の関係を持つかどうかを確認する、きめ細かな認可を行えるサービスです。
LangChain
LangChain は、ドキュメントの読み込み、ベクトルストア、プロンプトのテンプレートなどの様々なコンポーネントを組み立てることによって、LLM アプリケーション開発を効率化するライブラリーです。RAG パイプラインの把握、保守、変更が容易になります。
LLMs
本記事では OpenAI の埋め込み (Embedding) と Chat の API を使いますが、Anthropic、LLaMA、Azure OpenAI などの他のプロバイダーに簡単に置き換えることができます。主なタスクは次のとおりです。:
- 埋め込み: 類似したドキュメントを検索できるようにします。
- 生成: 検索して得られたドキュメントからユーザのクエリーに回答するためにテキストを生成します。
きめ細かな認可 と Okta FGA
きめ細かな認可 (FGA, Fine-Grained Authorization) とは、リソースの個々の単位まで、 どのリソース に対して 誰が何を実行できるか を制御することです。典型的なロールベースのシステムでは「管理者はすべてを閲覧でき、一般ユーザーは一部のデータを閲覧できる」といった設定が考えられます。しかし、実際のアプリケーション、特に多くのドキュメントを扱うアプリケーションでは、柔軟性が十分でない可能性があります。
OpenFGA (および Okta FGA) は、この問題に認可の 関係 を定義できるようにすることで対処します。認可モデルでは関係を直接でも間接でも定義できます。簡単に言うと、直接の関係はコンシューマーとリソース (ユーザーとオブジェクトと呼びます) の間で直接割り当てられ、データベースに格納されます。間接的な関係は、データと認可モデルに基づいて推測できる関係です。
RAG で FGA を使用する基本を学びたい場合は、ブログ記事 信頼できる AI アプリケーションの構築: FGA を用いた RAG システムのアクセス制御 を確認ください。

生成 AI はあらゆるところで利用され始めています。しかし、ユーザーごとにアクセスできるデータは異なります。検索拡張生成 (RAG) ときめ細かな認可 (FGA) を組み合わせることで、非公開情報を確実に保護する方法を紹介します。
実装: ステップバイステップ
以下は Python でのサンプルです。全体像を把握できるように、シンプルな内容としています。利用したい LLM やより堅牢なデータストアに合わせて自由に調整してください。
前提条件
このチュートリアルに従ってアプリケーションをセキュアにするには、以下が必要です。:
サンプルコードのダウンロードとインストール
開始するには、 GitHub から auth0-ai-samples リポジトリーをダウンロードします。:
git clone https://github.com/auth0-samples/auth0-ai-samples.git
cd auth0-ai-samples/authorization-for-rag/langchain-python
# Create a virtual env
python -m venv venv
# Activate the virtual env
source ./venv/bin/activate
# Install dependencies
pip install -r requirements.txt
アプリケーションは Python で記述されており、次のように構成されています。:
main.py: RAG パイプラインを定義するアプリケーションのメインエントリーポイントです。docs/*.md: LLM のコンテキストとして使用するサンプルの Markdown ファイルです。ドキュメントにはパブリックとプライベートの 2 種類があります。プライベートドキュメントには特定の個人のみがアクセスできます。helpers/memory_store.py: チェーンで情報元として機能するインメモリーのベクトルストアを作成します。helpers/read_documents.py:docsフォルダから Markdown ファイルを読み取るユーティリティです。scripts/fga_init.py: Okta FGA 認可モデルやサンプルデータを初期化するためのユーティリティです。
RAG パイプライン
main.py ファイルで、LangChain を使用して RAG パイプラインを定義します。このパイプラインでは、基盤となる LLM モデルと対話し、コンテキストからデータを取得します。プロジェクトによっては、異なるプラットフォームやシステムからデータを取得したい場合もあると思います。その際は、ドキュメント Langchain エコシステムのローダー を確認ください。:
以下の図は、ここで定義する RAG アーキテクチャを示しています。:
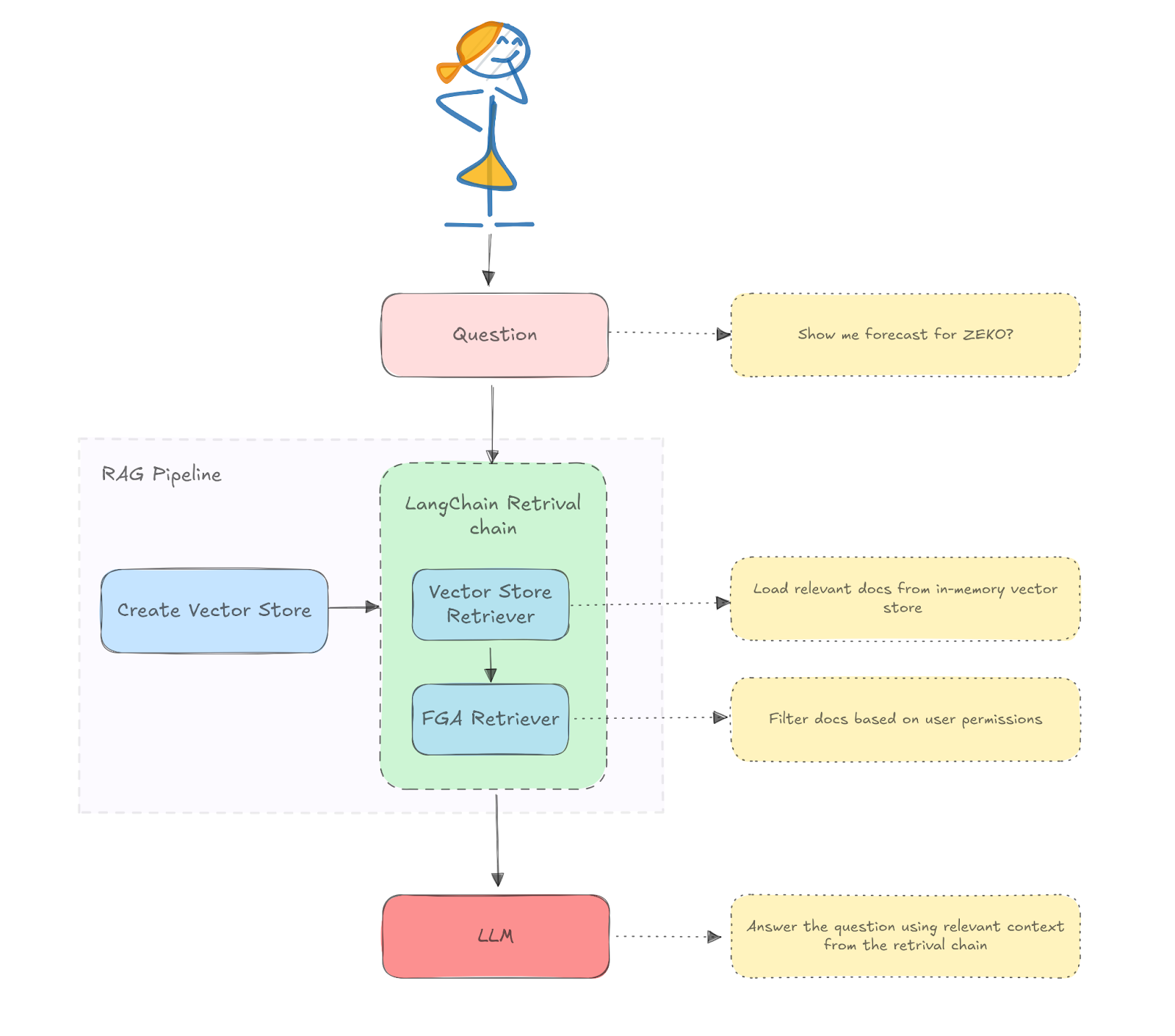
Python のコード:
class RAG: def __init__(self): documents = read_documents() self.vector_store = MemoryStore.from_documents(documents) self.prompt = ChatPromptTemplate.from_template( """You are an assistant for question-answering tasks. Use the following pieces of retrieved context to answer the question. If you don't know the answer, just say that you don't know. Use three sentences maximum and keep the answer concise.\nQuestion: {question}\nContext: {context}\nAnswer:""" ) self.llm = ChatOpenAI(model="gpt-4o-mini") def query(self, user_id: str, question: str): chain = ( { "context": FGARetriever( retriever=self.vector_store.as_retriever(), build_query=lambda doc: ClientBatchCheckItem( user=f"user:{user_id}", object=f"doc:{doc.metadata.get('id')}", relation="viewer", ), ), "question": RunnablePassthrough(), } | self.prompt | self.llm | StrOutputParser() ) return chain.invoke(question)
コードの内容を説明します。
RAG クラスは、まずベクトルストアを初期化し、ヘルパー関数を使用してドキュメントを読み取ります。また、本ユースケース用のシステムプロンプトと、使用する LLM モデル (この場合は gpt-40-mini) を定義します。
RAG クラスではquery 関数を定義しています。この関数では、FGARetriever インスタンスをプロンプトおよび LLM モデルと連携させてチェーンを構築します。FGARetriever は Auth0 AI SDK for Python が提供しています。
FGARetriever は、FGA にアクセスして認可を確認する処理を FGA へのクエリーと切り離して提供することを目的としています。build_query 引数で FGA へのクエリーを指定できます。この例では、ユーザーがドキュメントの viewer (閲覧者) であるかどうかを問い合わせます。:
build_query=lambda doc: ClientBatchCheckItem( user=f"user:{user_id}", object=f"doc:{doc.metadata.get('id')}", relation="viewer", ),
この設計により、Langchain で任意のリトリーバーのデータを FGA でクエリーして認可チェックするように組み合わせられます。
OktaFGA アカウントを作成
すでに Auth0 アカウント をお持ちの場合は、同じ認証情報を使用して https://dashboard.fga.dev の Okta FGA ダッシュボードにログインできます。Auth0 アカウントをお持ちでない場合は、https://dashboard.fga.dev にアクセスして、フリーアカウントを作成してください。
ログインすると、以下のようなダッシュボードが表示されます。:
初めて
Okta FGAダッシュボードにログインすると、新しいストアの作成を求められます。ストアは、認可モデルやエンジンが認可の決定を行うために必要とする全てのデータを格納する場所となります。名前を入力してストアを作成して、利用を開始できます。
OktaFGA クライアントを作成
ダッシュボードを開くと、OktaFGA に API 呼び出しを行うためにクライアントが必要になります。クライアントを作成するには、Settings に移動し、Authorized Clients セクションで Create Client をクリックします。クライアントに名前を付け、3つ全てのクライアントのパーミッションにチェックを入れ、Create をクリックします。
クライアントを作成すると、OktaFGA は Store ID、Client ID、Client Secret を表示します。これらの値は後で必要なため、この画面はそのままにしてください。
プロジェクトのルートに .env.example ファイルがあります。ファイルをコピーし、ペーストして .env というファイル名にしてください。次に、ファイルを開き、3 つの変数に OktaFGA が表示した値をセットします。変数をセットしたら、Okta FGA の画面で continue をクリックします。残りの変数 (FGA_API_URL と FGA_API_AUDIENCE) の値が表示されるため、これらも変数の値にセットしてファイルを保存してください。
この段階で、デモの実行に必要となる OpenAI API キー もセットすることもできます。
OktaFGA モデルを設定
アプリケーションのセットアップが完了したので、提供されているスクリプトを実行して、モデルとサンプルデータを初期化します。以下を実行します。:
python ./scripts/fga_init.py
OktaFGA のモデルエクスプローラーのページを開き、スクリプトが正常に動作したことを確認できます。以下のモデルが表示されるはずです。:
model
schema 1.1
type user
type doc
relations
define owner: [user]
define viewer: [user, user:*]
OktaFGA の認可モデルの設計と作成に関する詳細は、OktaFGA ドキュメント を参考にしてください。
スクリプトはモデルに加えて 2 つのタプルも作成しました。OktaFGA においてタプルは、タイプ間の関係を定義します。
まず、全てのユーザーにパブリック ドキュメントへのアクセス権を付与するタプルを定義しました。:
- User :
user:* - Object :
public-doc - Relation :
viewer
次に、管理ユーザーにプライベート ドキュメントへのアクセス権を付与する 2 つ目のタプルを作成しました。:
- User :
user:admin - Object :
private-doc - Relation :
viewer
タプルとその作成方法に関する詳細は、OktaFGA ドキュメントを参照してください。
チェーンにクエリーする
チェーンを呼び出してクエリーを処理し、レスポンスを生成します。
rag = RAG() question = "What is the forecast for ZEKO?" # Juan only has access to public docs response = rag.query("juan", question) print("Response to Juan:", response) # Admin has access to all docs response = rag.query("admin", question) print("Response to Admin:", response)
これで Python と LangChain を使用してセキュアな RAG を構築する方法を知って頂けたと思います。実際に動作をテストしてみましょう。
チェーンを実行するには、main.py ファイルを呼び出すだけです。:
python main.py
手順に従うと、以下のようなレスポンスが表示されます。:
Response to Juan: The retrieved context does not provide any specific forecast or predictions for ZEKO (Zeko Advanced Systems Inc.). It mainly outlines the company's mission, technologies, and products without detailing any financial or market forecasts. Therefore, I don't know the forecast for ZEKO.
Response to Admin: The forecast for Zeko Advanced Systems Inc. (ZEKO) for fiscal year 2025 is generally bearish. Projected revenue growth is expected to remain subdued at 2-3%, with net income growth projected at 1-2%, primarily due to margin pressures and competitive challenges. Investors should be cautious, given the potential headwinds the company faces.
上記の通り、Juan は質問に関連したデータを取得できませんでしたが、ユーザー admin は正確なレスポンスを取得できました。
まとめ
ここまで OpenFGA を使用してドキュメント単位 でのユーザー権限を扱える セキュア な RAG システムを構築する方法を紹介しました。この方法はデータ漏洩を防ぎ、セキュリティとコンプライアンスの要件を満たし、柔軟です。大規模な機密情報を扱う企業用途に最適です。
他のベクトル ストア、異なる LLM プロバイダー、あるいは独自の組織ルールに合わせて、フローを自由に変更してください。RAG の検索能力ときめ細かな認可を組み合わせることで、洞察力があり、かつセキュアな AI アプリケーションを構築できます。
最後にお知らせがあります。LlamaIndex、LangChain、CrewAI、Vercel AI などの優れた生成 AI フレームワークと協力して、より多くのコンテンツやサンプルアプリに取り組んでいます。
Auth0 for AI Agents は生成 AI アプリケーションでユーザーの情報を保護するのに役立つ、今後リリース予定の機能です。
詳細の確認や質問は、Auth0 Lab Discord サーバー に参加ください。
About the author

Juan Cruz Martinez
Staff Developer Advocate