本記事は 2025年3月12日 に更新された「Build a Secure RAG Agent Using LlamaIndex and Auth0 FGA on Node.js」を機械翻訳した記事です。
生成 AI (GenAI) はソフトウェア開発の状況を大きく変え、現在 AI エージェントが注目を集めています。AIエージェントは、データベースや検索エンジンから最新の情報や特定分野のデータを取得し、大規模言語モデル(LLM)に追加のコンテキストを与える検索拡張生成 (RAG) と組み合わせることができます。この手法は LLM のハルシネーションを減らし、精度を向上させます。また、 AI エージェントは複雑なワークフローを実行するツールとして RAG を利用することもできます。
機密情報の漏洩 は、 RAG ベースのシステムで一般的な課題となっています。 LLM がデータベースの機密データに誤ってアクセスしたり、漏洩したりすることを防ぐ必要があります。従来のロールベースアクセス制御 (RBAC) では、 RAG アプリケーションやエージェントのセキュリティを実現するには不十分です。このような状況では きめ細かな認可 (FGA) が有効なソリューションとなります。
RAG で FGA を使用する基本を学ぶには、こちらのブログ記事 信頼できる AI アプリケーションの構築: FGA を用いた RAG システムのアクセス制御 を確認ください。

Learn how to get started with Auth0 FGA for a RAG application.
本チュートリアルでは、人気の LlamaIndex フレームワーク の JavaScript バージョンである LlamaIndex.TS を使用してシンプルな RAG エージェントを構築し、 Auth0 FGA を使用してセキュリティを実現します。
前提条件
本チュートリアルでは、以下のツールとサービスが必要になります。:
- NodeJS v20
- Auth0 FGA アカウント こちらで作成
- OpenAI アカウントと API キー こちらで作成
LlamaIndex の役割は?
LlamaIndex は、 AI エージェントや RAG アプリケーションを構築するための柔軟なフレームワークです。さまざまな LLM やデータベースと連携するための Python や JavaScript の SDK を提供します。 LlamaIndex を使うと、ユーザーとの対話、データベースからのデータ取得、 LLM による応答生成を行う AI エージェントやワークフローを構築できます。さらに、非構造化データを LLM に最適化された形式へ変換する LlamaParse のようなツールや、 LLM ですぐに利用できるデータをクラウド上で保存・取得するための LlamaCloud も提供しています。
LlamaIndex RAG アプリケーションのセットアップ
まず、 GitHub から auth0-ai-samples リポジトリをダウンロードします。:
git clone https://github.com/auth0-samples/auth0-ai-samples.git cd auth0-ai-samples/authorization-for-rag/llamaindex-agentic-js # install dependencies npm install
アプリケーションは Node.js プラットフォーム向けに TypeScript で記述されており、以下のように構成されています。:
index.ts: RAG パイプラインを定義するアプリケーションのメインエントリーポイントです。assets/docs/*.md: LLM のコンテキストとして使用するサンプル Markdown ドキュメントです。デモンストレーション用に、パブリックドキュメントとプライベートドキュメントを用意しています。scripts/fga-init.ts: Auth0 FGA 認可モデルを初期化するためのユーティリティです。
アプリケーションを実行する前に、重要な部分を確認しましょう。
RAG パイプライン
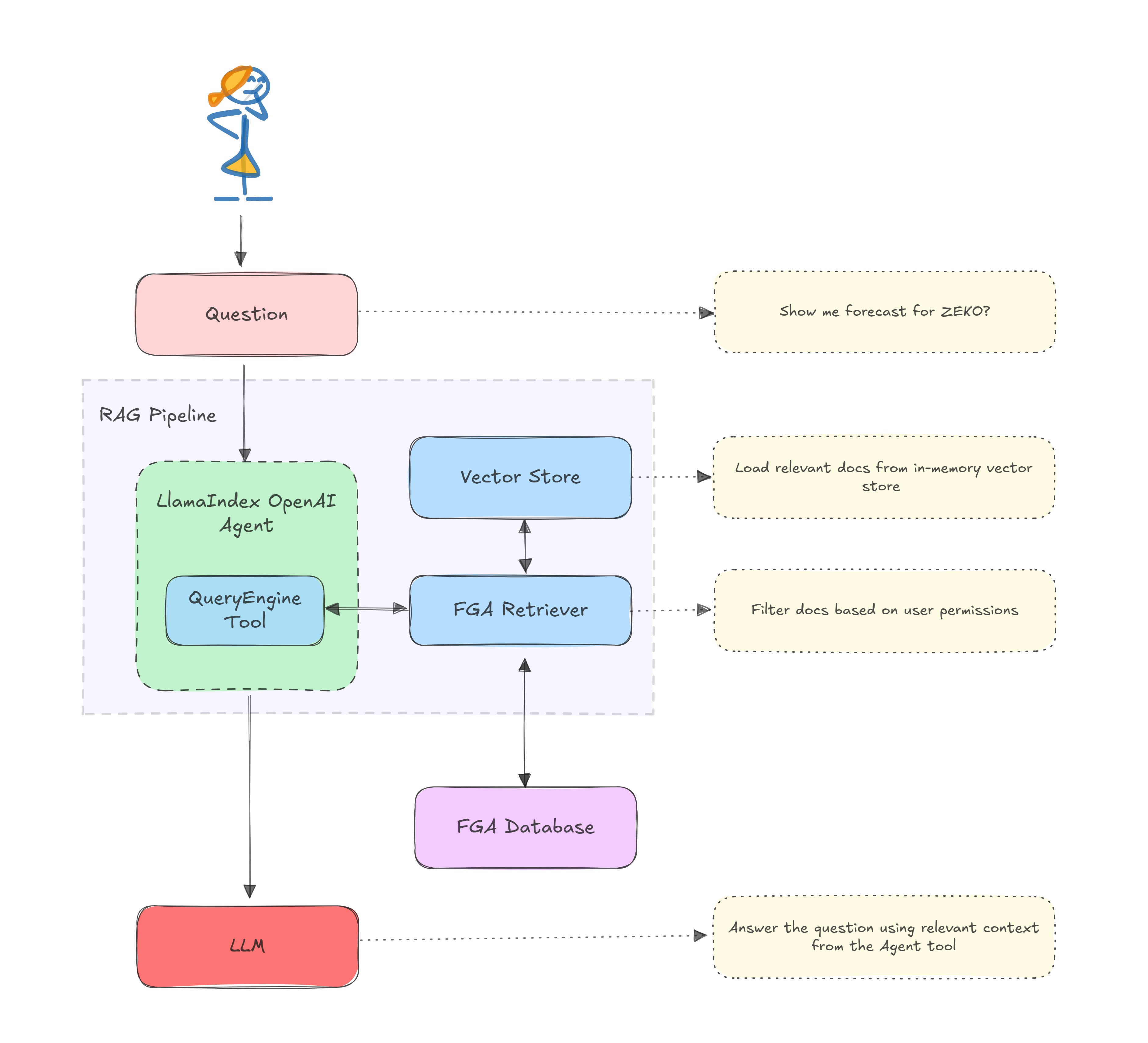
RAG パイプラインは index.ts で定義します。このパイプラインは LlamaIndex Agents を使用して LLM と連携し、データベースからデータを取得します。パイプラインは、以下のように定義します。:
/** index.ts **/ const user = 'user1'; // 1. Read and load documents from the assets folder const documents = await new SimpleDirectoryReader().loadData('./assets/docs'); // 2. Create an in-memory vector store from the documents using the default OpenAI embeddings const vectorStoreIndex = await VectorStoreIndex.fromDocuments(documents); // 3. Create a retriever that uses FGA to gate fetching documents on permissions. const retriever = FGARetriever.create({ // Set the similarityTopK to retrieve more documents as SimpleDirectoryReader creates chunks retriever: vectorStoreIndex.asRetriever({ similarityTopK: 30 }), // FGA tuple to query for the user's permissions buildQuery: (document) => ({ user: `user:${user}`, object: `doc:${document.metadata.file_name.split('.')[0]}`, relation: 'viewer', }), }); // 4. Create a query engine and convert it into a tool const queryEngine = vectorStoreIndex.asQueryEngine({ retriever }); const tools = [ new QueryEngineTool({ queryEngine, metadata: { name: 'zeko-internal-tool', description: `This tool can answer detailed questions about ZEKO.`, }, }), ]; // 5. Create an agent using the tools array and OpenAI GPT-4 LLM const agent = new OpenAIAgent({ tools }); // 6. Query the agent let response = await agent.chat({ message: 'Show me forecast for ZEKO?' });
以下に RAG アーキテクチャを図で示します。:
FGA retriever
FGARetriever クラスは auth0-ai-js SDK の一部として提供され、Auth0 FGA で定義された認可モデルに基づいてドキュメントをフィルターします。このクラスは、既にベクターストアにドキュメントがあり、ユーザーのパーミッションに基づいてベクターストアの結果をフィルターするシナリオに最適です。ベクターストアが既にドキュメントを少数に絞り込んでいる場合に、ユーザーがアクセスできるドキュメントのみにさらに絞り込みます。
アルファ版は、以下のコマンドを使用してインストールできます。(訳注:より新しいバージョンがリリースされていますが本記事はアルファ版に基づいています):
npm install "https://github.com/auth0-lab/auth0-ai-js.git#alpha-2" --save
buildQuery 関数は、FGA ストアへのクエリーを作成します。クエリーは、ユーザー、オブジェクト、リレーションで構成されます。ユーザーはユーザー ID、オブジェクトはドキュメント ID、リレーションはユーザーがドキュメントに対して持つパーミッションです。
buildQuery: (document) => ({ user: `user:${user}`, object: `doc:${document.metadata.file_name.split(".")[0]}`, relation: "viewer", }),
Retrieval Agent
queryEngineをvectorStoreIndexから作成し、カスタムの FGA retriever を使用するように設定します。queryEngineは、ユーザーのクエリーに基づいてドキュメントを検索し、関連情報を取得する処理を扱います。tools配列には、queryEngineをラップするQueryEngineToolを含めます。ツールは、エージェントがクエリーエンジンの機能にアクセスするための構造化されたインターフェースを提供します。- OpenAI の GPT-4 モデルと
tools配列を使用してagentを作成します。agentは、ユーザーとツールの間のインテリジェントなインターフェースとして機能し、自然言語のクエリーを理解し、いつクエリーエンジンツールを使用するかを決定し、取得した情報に基づいて応答を作成します。
/** index.ts **/ const queryEngine = vectorStoreIndex.asQueryEngine({ retriever }); const tools = [ new QueryEngineTool({ queryEngine, metadata: { name: 'zeko-internal-tool', description: `This tool can answer detailed questions about ZEKO.`, }, }), ]; // 5. Create an agent using the tools array and OpenAI GPT-4 LLM const agent = new OpenAIAgent({ tools });
FGA ストアをセットアップする
Auth0 FGA ダッシュボードで Settings に移動し、Authorized Clients セクションで + Create Client をクリックします。クライアントに名前を付け、3 つすべてのクライアントパーミッションにチェックを付け、Create をクリックします。
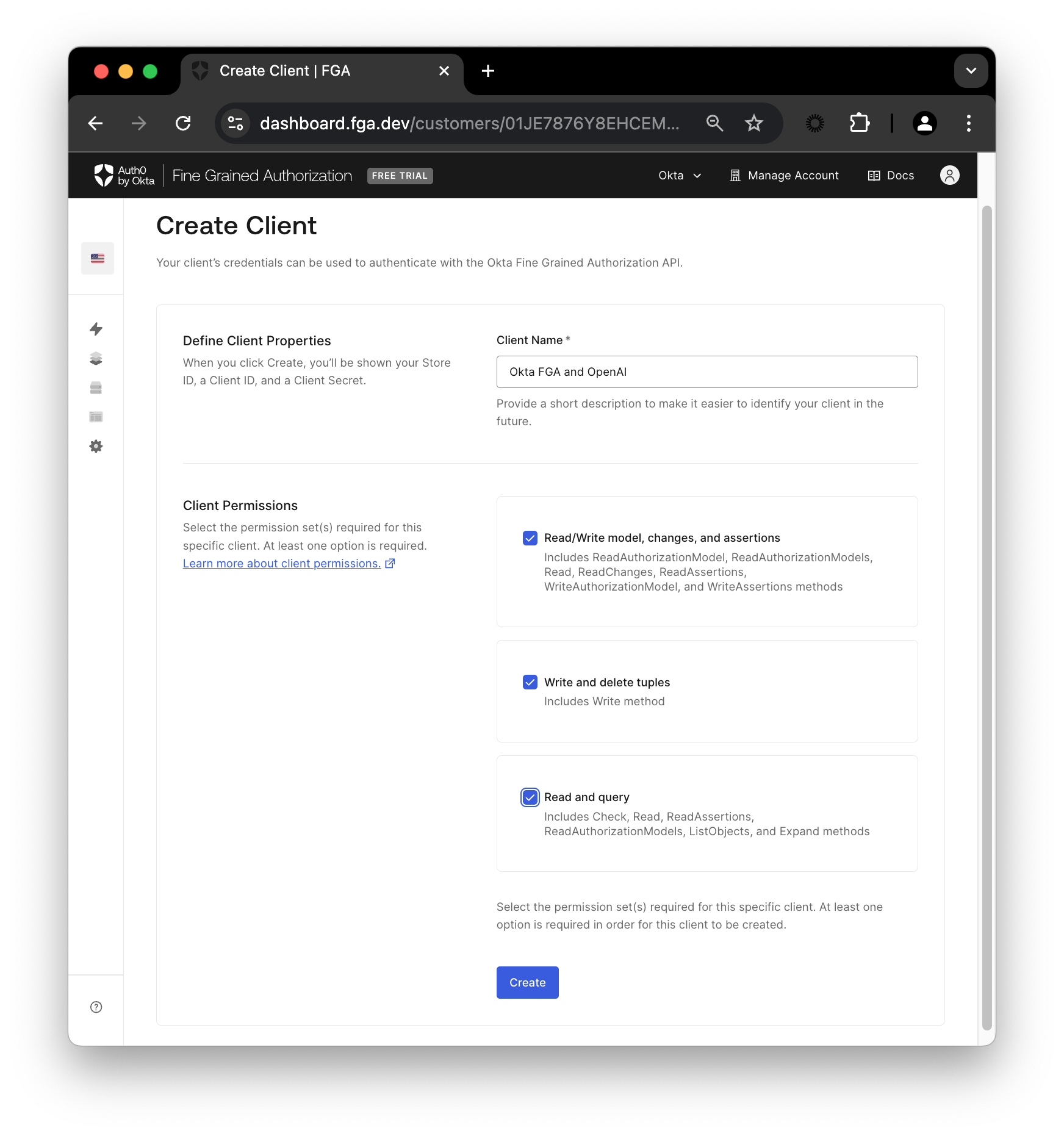
クライアントが作成されると、Store ID、Client ID、Client Secret が記載された画面が表示されます。
プロジェクトのルートに、以下の内容の .env ファイルを作成します。Continue をクリックして FGA_API_URL と FGA_API_AUDIENCE を確認します。
# OpenAI
OPENAI_API_KEY=<your-openai-api-key>
# Auth0 FGA
FGA_STORE_ID=<your-fga-store-id>
FGA_CLIENT_ID=<your-fga-store-client-id>
FGA_CLIENT_SECRET=<your-fga-store-client-secret>
# Required only for non-US regions
FGA_API_URL=https://api.xxx.fga.dev
FGA_API_AUDIENCE=https://api.xxx.fga.dev/
OpenAI の API キーは こちら を確認ください。
次に、Model Explorer に移動します。モデル情報を以下の内容に更新する必要があります。:
model
schema 1.1
type user
type doc
relations
define owner: [user]
define viewer: [user, user:*]
Save をクリックします。
FGA で認可モデルを作成する方法の詳細は、こちらのドキュメント を確認ください。
公開情報にアクセスするには、FGA にタプルを追加する必要があります。Tuple Management セクションに移動し、+ Add Tuple をクリックして、以下の情報を入力します。:
- User:
user:*を入力 - Object: doc を選択し、ID に
public-docを入力 - Relation:
viewerを入力
タプルは、特定のオブジェクトに対するユーザーの関係を示します。たとえば、上記のタプルは、すべてのユーザーが public-doc オブジェクトを閲覧できることを意味します。
または、
scripts/fga-init.tsスクリプトを使用して、FGA ストアのモデルとタプルを初期化することもできます。.envファイルを設定した後、npm run fga:initコマンドを実行します。
アプリケーションをテストする
アプリケーションと FGA ストアのセットアップが完了したので、以下のコマンドを使用してアプリケーションを実行できます。:
npm start
アプリケーションは Show me forecast for ZEKO? というクエリーで開始します。この情報はプライベート ドキュメント内にあり、このドキュメントへのアクセス権を持つタプルを定義していないため、アプリケーションはドキュメントを取得できません。FGA retriever はベクターストアの結果からプライベートドキュメントをフィルターで除外し、その結果、以下のような応答を出力します。
The provided context does not include specific forecasts or projections for Zeko Advanced Systems Inc. ...
クエリーを公開ドキュメントで利用可能な情報に関するものに変更すると、アプリケーションはその情報を取得できます。
プライベート情報にアクセスするには、タプル リストを更新する必要があります。Auth0 FGA ダッシュボードの Tuple Management セクションに戻り、+ Add Tuple をクリックして、以下の情報を入力します。:
- User:
user:user1を入力 - Object: doc を選択し、ID に
private-docを入力 - Relation:
viewerを入力
Add Tuple をクリックし、再度スクリプトを実行します。:
npm start
今回は user1 の private-doc オブジェクトに対する viewer リレーションを定義するタプルを追加したため、予測情報を含む応答が表示されます。
これで、LlamaIndex を使用し、Auth0 FGA を使用して保護するシンプルな RAG アプリケーションを実行できました。
Auth0 for AI Agents、Auth0 FGA、生成 AI についてさらに学ぶ
本記事では、Auth0 の Auth0 for AI Agents と Auth0 FGA を使用して、LlamaIndex ベースの RAG アプリケーションを保護する方法を紹介しました。Auth0 FGA は、オープンソースである OpenFGA に基づいて構築されています。GitHub 上の OpenFGA コードも確認ください。
さらに、LlamaIndex、LangChain、CrewAI、Vercel AI SDK、GenKit のような優れた生成 AI フレームワークと協力し、より多くのコンテンツやサンプル アプリを開発中です。Auth0 for AI Agents は、生成 AI アプリケーションでユーザーの情報を保護するための Auth0 の製品です。詳細の確認や質問は、Auth0 Lab Discord サーバーに参加ください。
About the author

Deepu K Sasidharan
Principal Developer Advocate