
本記事は 2025年4月14日 に更新された「Build Trustworthy AI Implementing Access Control for RAG Systems Using FGA」を機械翻訳した記事です。
すべてのユーザーがすべてのデータにアクセスできるわけではありません。生成 AI アプリケーションの開発者は、モデルが提供する情報が、設定されているアクセス制御ポリシーに従っていることを保証する必要があります。本記事では、きめ細かい認可 (FGA) でデータを保護する方法を紹介します。
基本: AI、LLM、RAG の解説
生成 AI (GenAI) が最近どこにおいても使われ始めています。最近、AI という言葉はほとんどの場合に生成 AI や大規模言語モデル (LLM) の意味で使用されますが、同じものではありません。人工知能 (AI) は、人間が行動するのと同じような方法で、コンピュータに学習、推論、行動する能力を与えることに焦点を当てた科学の分野です。
生成 AI と LLM の定義
生成 AI (GenAI) は、テキスト、画像、その他のデータ形式などのデータを生成することに焦点を当てた AI の分類の 1 つです。一方、大規模言語モデル (LLM) も生成 AI と同様に AI の分類の 1 つです。LLM は、膨大な量のデータでトレーニングされた機械学習モデルであり、自然言語を理解し、応答することができます。LLM のモデルはテキストを入力として受け取り、テキスト形式で応答できることを意味し、まるで思考を持つ存在と会話しているような印象を多くの場合に与えます。
RAG (Retrieval-Augmented Generation) と使われる理由
情報の検索は新しいことではありません。以前は、地域のすべての人の電話番号が名前で索引付けされた電話帳がありました。電話帳で情報を探すには、電話をかけたい人の名前を知っている必要がありました。今日では、このような情報は検索ですぐに見つけられます。
機械学習モデルはトレーニングに使用されたデータに基づいて多くのことが可能ですが、検索時にさらに多くの情報を追加する方法がない限り、結果は古くなっていたり、不正確であったり、たとえばプライベートデータやドメイン固有のデータを考慮していなかったりする可能性があります。そこで RAG が役立ちます。
RAG は Retrieval-Augmented Generation の略で、LLM に見られる ハルシネーション を回避し、精度を向上させるアーキテクチャ です。また、トレーニングデータセットよりも新しいデータやドメイン固有のデータの追加コンテキストを提供することで、LLM が回答を作成するためにより多くの情報を提供できます。
RAG は、モデルのトレーニング中に与えられたものよりも多くのコンテキストを追加することで、機械学習モデル (通常は LLM) の能力を拡張します。
RAG および LLM アプリケーションにおけるプライベートデータ保護の課題
多くの 生成 AI アプリケーションは、 LLM だけでなく RAG (Retrieval-Augmented Generation) アーキテクチャも利用しているため、モデルのトレーニング時に使用されたリソース以外のリソースにもアクセスできます。プライベートデータや機密データに関して懸念されることの 1 つは、AI アプリケーションと対話する際に、特定のリソースへのアクセス権を持つ人のみがその情報を受け取れるように、どのように保証できるかということです。
架空の企業 Zeko の開発者として働いている状況を想像してみてください。あなたは会社の RAG ベースの AI アシスタントにアクセスできますが、それは特定のドメインに関するクエリのみに限定されています。その AI アシスタントは、クラウド環境内のすべての情報を見ることができ、中には財務チームなど特定の担当者のみがアクセスできるプライベートファイル (会計年度の予測など) も含まれています。あなたはこれらのデータへのアクセス権を持っておらず、持つべきでもありません。もしあなたがアシスタントに「ZEKO の予測を見せて」と尋ねた場合、アシスタントはその情報でクエリに答えるべきではありません。しかし、もし経理部の同僚が同じ質問をした場合は、答えを確実に得られるべきです。
認可ポリシーに準拠しないと機密情報の漏洩の脆弱性につながる、つまりアクセス権のないユーザーにデータを公開してしまう可能性があります。「RAG を活用するアプリが機密情報の漏洩を回避するのをどのように支援できるのか?」という疑問が残ると思います。方法の 1 つは Fine-Grained Authorization (FGA)、より具体的には Okta FGA を使用することです。
Okta FGA を使った FGA (Fine-Grained Authorization) の紹介
きめ細かい認可 (Fine-Grained Authorization) は、想像以上に多くの場面で使われています。意識しないまま使っていることも少なくありません。有名な例として、Google Drive があります。ユーザーごとに 特定のリソース に対して特定の操作だけを許可できます。例えば、「Jess はドキュメントを閲覧できる」や「John はドキュメントを編集できる」といったように、ユーザーごとに細かく権限を設定できます。
同じ考え方に基づいて設計された Okta FGA は、アプリケーションなどの開発において複雑な認可の判断を実装するための製品です。内部では OpenFGA のモデリング言語と判断エンジンを使用しており、これは Google Zanzibar(Google 社内の認可システム)から着想を得たものです。
Okta FGA の素晴らしい点は、アプリケーションの認可モデルを簡単に定義できる点にあります。また、認可判断に必要なデータの登録や、特定のユーザーが特定のリソースに対して特定の操作を実行できるかどうかの確認も簡単に行えます。
安全な RAG パイプラインに Okta FGA を導入する方法
Okta FGA を使った RAG アプリケーションの動作を確認できるサンプルアプリケーションを用意しました。このサンプルは、他の例とともに こちらのリポジトリ にあります。本記事ではコードを実行する必要はありませんが、実際に動かしてみることで各概念をより深く理解できるため、ローカル環境での実行をおすすめします。
Okta FGA を使った RAG サンプルアプリケーション
サンプルアプリケーション は TypeScript で実装されています(Python 版のサンプル も用意しています)。このアプリケーションでは、ドキュメントの種類として「public」と「private」の 2 種類を扱います。
public-doc.md には、架空企業 Zeko Advanced Systems Inc. の基本的な企業情報が記載されています。実際の企業サイトなどで公開されてそうな内容となっています。一方で、private-doc.md には、Zeko の 2025 年度の業績予測や売上高、粗利益率などの内部情報が含まれています。
このアプリケーションでは、以下のライブラリを使用しています:
- OpenAI SDK:
gpt-4o-miniモデル を使ってクエリの処理を行います。 - OpenFGA SDK: 認可モデルに基づいて、機密データの漏洩を防止します。
- faiss-node ライブラリ: ドキュメントから生成された埋め込みベクトルをインデックス化するためのローカルな ベクトルデータベース (DB) として使います。
このアプリケーションの目的は、「Show me forecast for ZEKO.」という質問に回答することです。そのために、クライアントアプリケーションの openai-fga/src/index.ts ファイルに、ユーザーと質問が定義されています。:
const user = "user1"; const query = "Show me forecast for ZEKO.";
現在は質問とユーザーが固定値として埋め込まれていますが、AI アシスタントとして使う場合は、ユーザーは認証コンテキストから取得され、質問はユーザーインターフェースから入力される想定です。
このクライアントは、FGA インテグレーションが導入されれば、以下のフローチャートで示される手順を実行します:
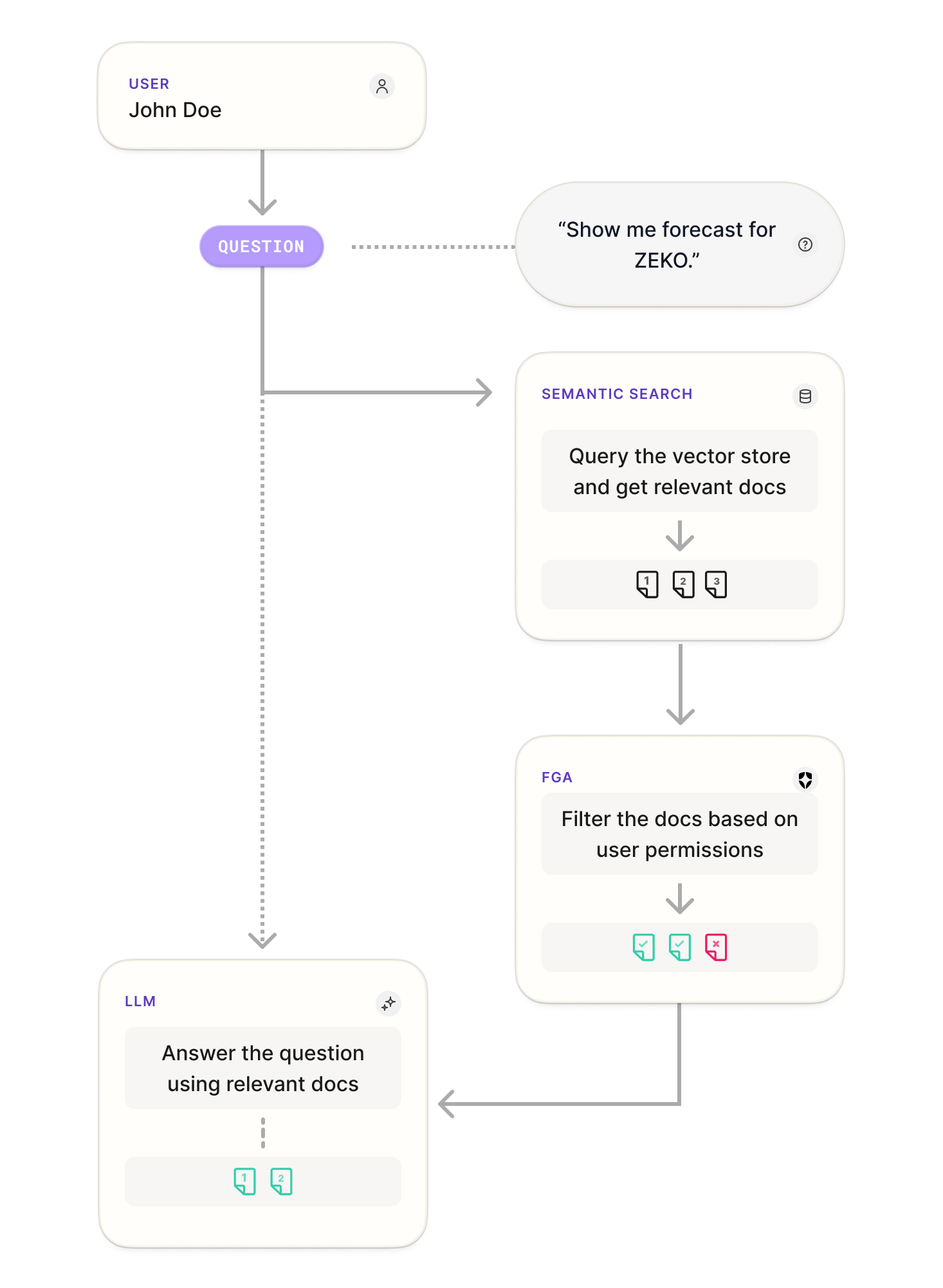
まず、ユーザーが質問を入力します。その際、ベクトル DB でクエリに関連するドキュメントを取得し、FGA でユーザーの権限に基づいてドキュメントがフィルタリングされます。最後に、LLM が質問と、取得されたドキュメントによる追加コンテキストをもとに回答を生成します。では、これらのステップをコードで確認していきます。
OpenAI と Okta FGA のアカウントをセットアップする
コードを実行するには、Okta FGA と OpenAI の API アカウントをセットアップする必要があります。ただし、アカウントはコードを実行する場合にのみ必要で、Okta FGA と RAG の連携方法を理解するために手順を確認するということも可能です。
Okta FGA のセットアップには、こちらのサインアップページから開始し、最初のストアを作成します。ストア とは、アプリケーションの認可判定に必要なデータをまとめて管理する単位です。Okta FGA は Auth0 アカウントを利用します。もし Auth0 を初めて利用する場合はアカウントの作成も求められます。
このアプリケーションでは LLM モデルを使用するため、gpt-4o-mini モデル を使えるように OpenAI アカウントを作成し、API キーを取得する必要があります。Open AI の API キーの取得手順は こちらのページ を確認ください。
サンプル RAG アプリケーションのセットアップ
これ以降のセクションでは、サンプルアプリケーションを何度か実行します。まずは以下のコマンドをターミナルで実行し、サンプルプロジェクトをダウンロードします。
git clone https://github.com/oktadev/auth0-ai-samples.git
サンプルアプリは auth0-ai-samples/authorization-for-rag/openai-fga-js フォルダにあります。そのため、移動します。:
cd auth0-ai-samples/authorization-for-rag/openai-fga-js
次に、.env ファイルを作成し、以下のように入力します。前のセクションで取得した OpenAI キーを忘れずに追加してください。
# OpenAI
OPENAI_API_KEY=<your-open-ai-key-here>
# Okta FGA
FGA_STORE_ID=<your-fga-store-id-here>
FGA_CLIENT_ID=<your-fga-client-id-here>
FGA_CLIENT_SECRET=<your-fga-client-secret-here>
# Optional
FGA_API_URL=https://api.xxx.fga.dev
FGA_API_TOKEN_ISSUER=auth.fga.dev
FGA_API_AUDIENCE=https://api.xxx.fga.dev/
最後に、依存関係をインストールします。:
npm install
次に、Okta FGA 関連の値を取得します。:
Okta FGA ストアとモデルの設定
Okta FGA ダッシュボード で、 Model Explorer に移動します。モデル情報を以下の内容で更新します。:
model
schema 1.1
type user
type doc
relations
define owner: [user]
define viewer: [user, user:*]
Save をクリックすると、下の画像のように更新されたプレビューが表示されます。
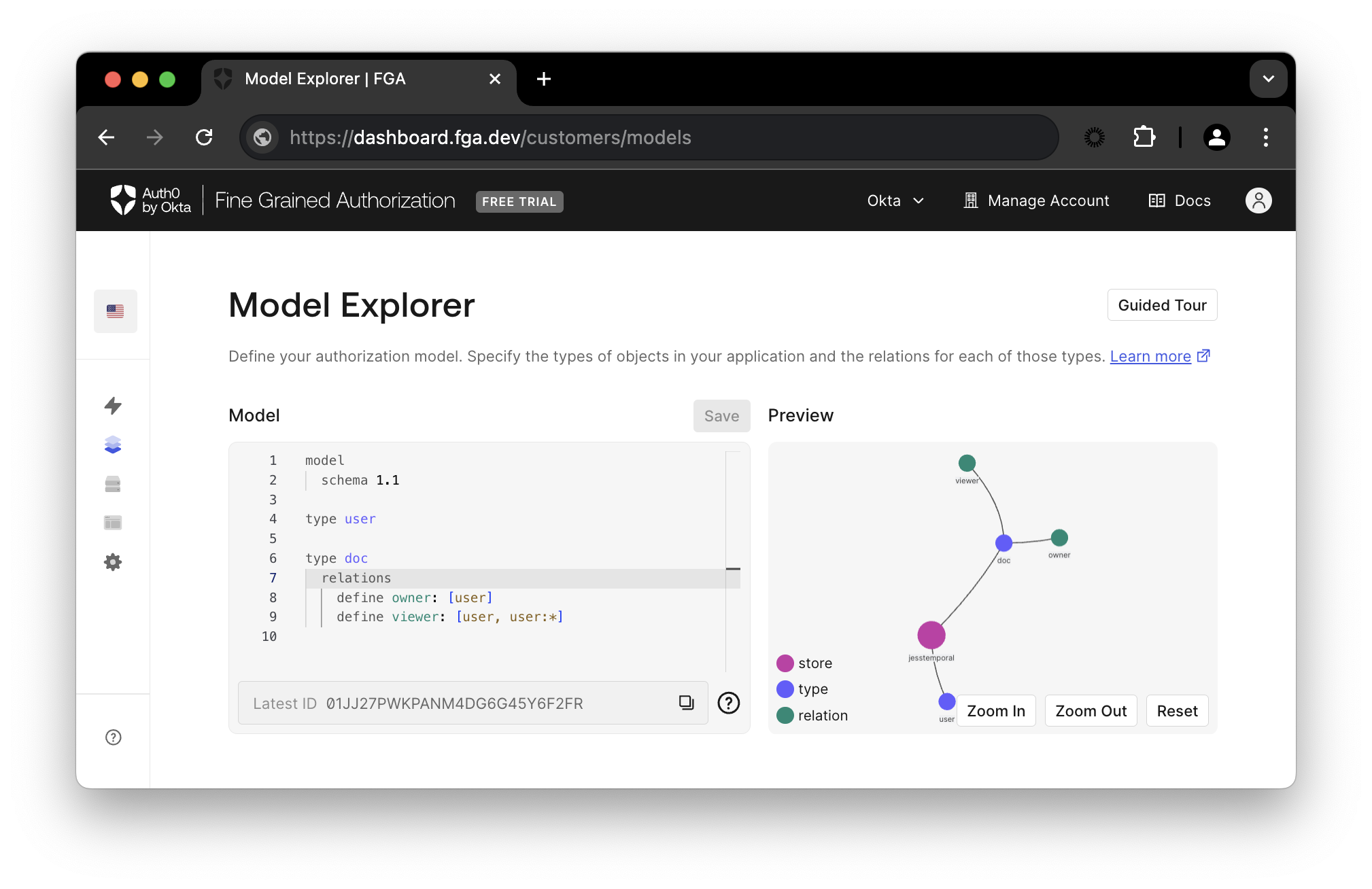
モデルはアプリケーションに関わる全ての要素を表します。モデルには、ユーザーとオブジェクト(ドキュメント)の関係、および関係のタイプ( viewer または owner )に関する情報が含まれます。
次に、 Settings の Authorized Clients セクションで、 + Create Client ボタンをクリックします。クライアントに名前を付け、3つ全てのクライアント権限にチェックを入れ、 Create をクリックします。
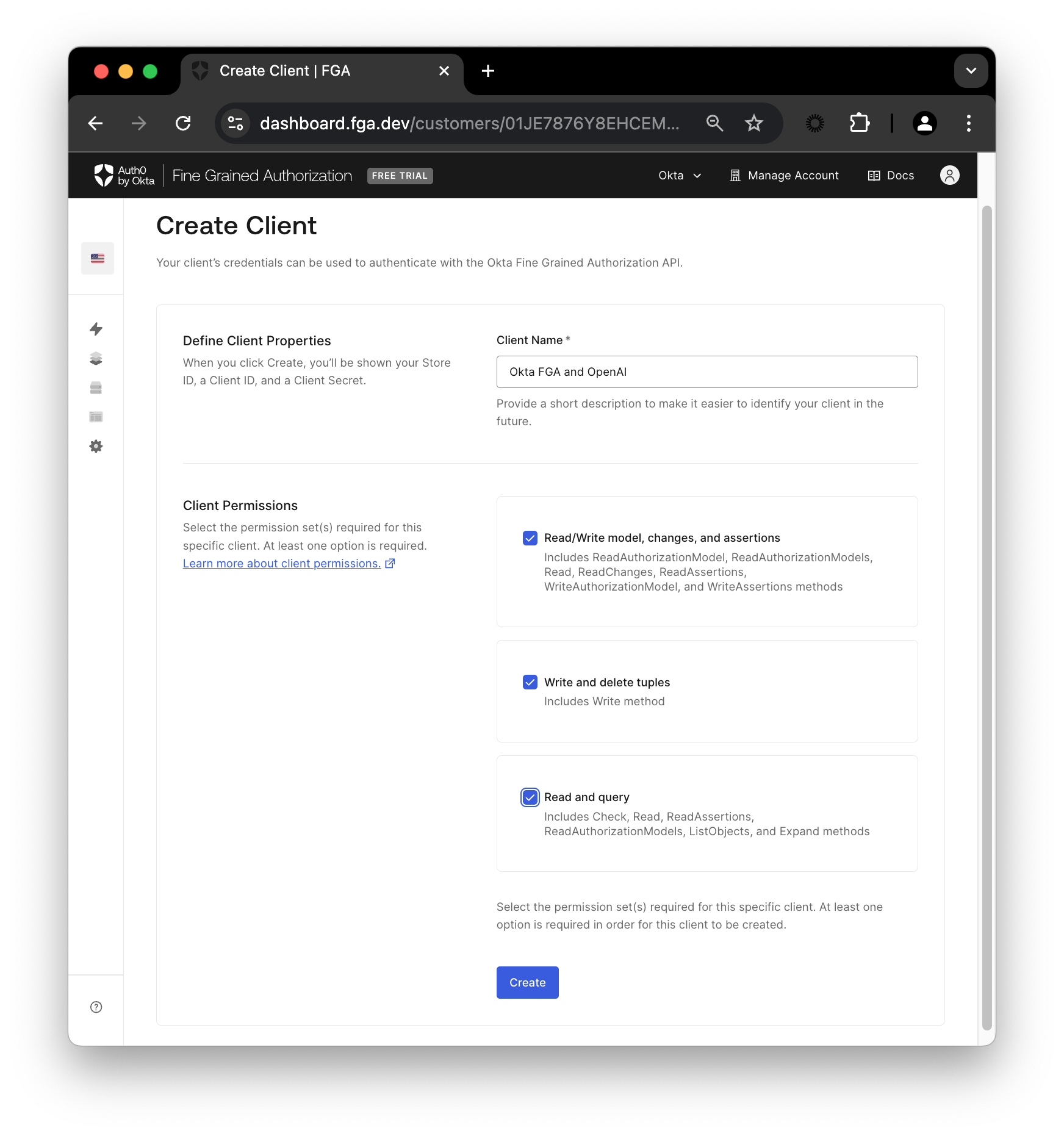
以下の権限があります。:
- Read/Write model, changes, and assertions: 認可モデルの作成と変更
- Write and delete tuples: 認可モデルの関係データ (タプル, tuples) の登録と管理
- Read and query: 判定エンジンへのクエリ実行、つまり認可チェックとオブジェクトのリスト表示
クライアントが作成されると、ドキュメントをフィルタリングするために Okta FGA へ接続するのに必要な全ての情報が画面に表示されます。
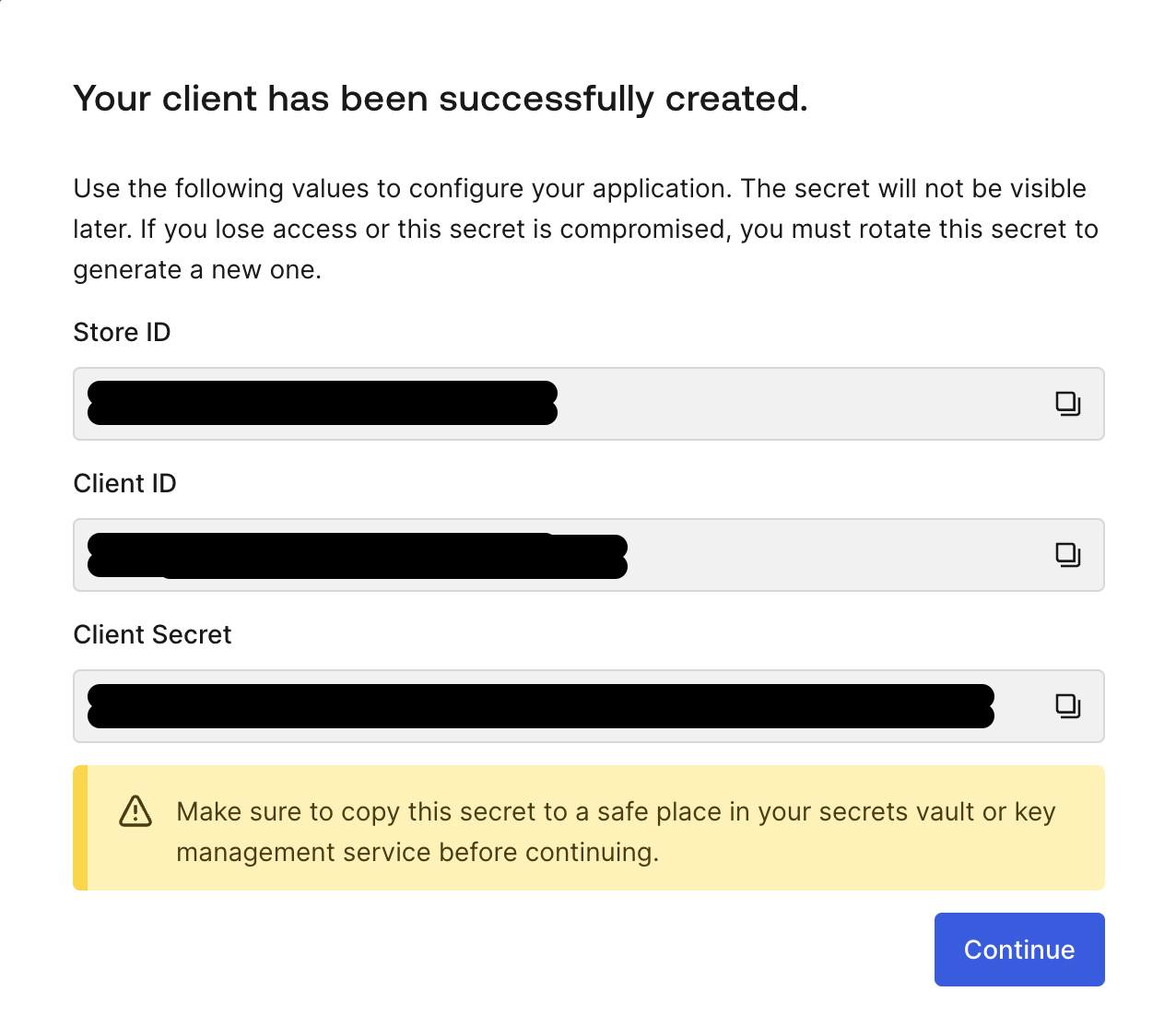
画面上の情報をコピーし、 .env ファイル内の FGA_STORE_ID 、 FGA_CLIENT_ID 、 FGA_CLIENT_SECRET を新しい値で更新してください。その後、 Continue をクリックします。
FGA のモデルと関係データのタプルを初期設定
次に、以下のコマンドを実行して FGA を初期化し、最初のタプルを作成します:
npm run fga:init
最初のタプルを作成します。タプルはユーザーの特定オブジェクトに対する関係性を示します。それぞれの関係タプルは、ユーザー、関係、オブジェクトを含みます。例えば、タプル (user: "user:jess", relation: "viewer", object:"docs:public-doc") は、「jess は public-doc の閲覧者である」と表現できます。

fga:init スクリプトを実行後、上記の画像にあるように、Okta FGA ダッシュボードの「Tuple Management」で最初の関係タプルを確認できます。作成されたタプルは、利用可能な公開ドキュメントへのアクセスをすべてのユーザーに許可します。
FGA を使用したセキュアな RAG アプリケーションのテスト
コードのセットアップが完了したので、実行してみましょう。
権限がない状態でのクエリ
クライアントコードには、「Show me forecast for ZEKO.」という質問が次のように定義されていることに注意してください。
const user = "user1"; const query = "Show me forecast for ZEKO.";
もう1つの重要な注意点として、現時点ではユーザーはプライベートドキュメントへのアクセス権を持っていません。その関係を定義するタプルがまだ存在しないためです。作成方法はこれから説明します。
以下のコマンドを実行してください。
npm start
次のような応答が出力されます。
The provided context does not include any forecasts or predictions for Zeko Advanced Systems Inc. If you are looking for specific forecasts related to financial performance, market trends, or product development, that information is not available in the documentation.
(提供されたコンテキストには、Zeko Advanced Systems Inc. のいかなる予測や予測も含まれていません。財務実績、市場動向、製品開発に関する特定の予測をお探しの場合は、その情報はドキュメントにありません。)
この応答は理にかなっています。このユーザーがアクセスできるすべての情報は public-doc.md にあり、そこには Zeko の予測に関する情報は含まれていないためです。
コードを実行すると、RAG パイプラインは追加のコンテキストに使用されるドキュメントを読み取り、faiss-node ライブラリを使用して FAISS インデックスを作成し、関数 LocalVectorStore を使用して OpenAI embeddings API でエンコードします。
const documents = readDocuments();
const vectorStore = await LocalVectorStore.fromDocuments(documents);
ユーザー権限に基づいてドキュメントをフィルタリングするために、FGARetriever のインスタンスが次のように作成します。:
const retriever = FGARetriever.create({ documents: await vectorStore.search(query), buildQuery: (doc) => ({ user: `user:${user}`, object: `doc:${doc.id}`, relation: "viewer", }), });
FGARetriever は、ユーザーのクエリに関連するドキュメントをリストアップする vectorStore.search(query) をラップしています。ベクターデータベースを参照してユーザーのクエリに関連するドキュメントを取得し、FGA モデルを参照して権限に基づいてドキュメントをフィルタリングすることで、コンテキストを追加します。
const context = await retriever.retrieve();
最後に、query と context を再度 OpenAI に渡して GPT-4o mini モデルで応答を生成し、ターミナルに応答を出力します。
const answer = await generate(query, context); console.log(answer);
権限がある状態でのクエリ
次に、プライベートな情報にアクセスできるようにするには、タプルのリストを更新する必要があります。Okta FGA ダッシュボードの Tuple Management セクションに戻り、+ Add Tuple をクリックして、以下の情報を入力します。:
- User - 値に
user:user1を入力 - Object -
docを選択し、ID にprivate-docを入力 - Relation -
viewerを選択
Add Tuple をクリックし、再度スクリプトを実行します。:
npm start
今回は、以下の結果が表示されます。:
The forecast for Zeko Advanced Systems Inc. (ZEKO) for fiscal year 2025 is as follows:
- **Revenue Growth:** Projected increase of 2-3% year-over-year, reflecting anticipated competitive pressures and macroeconomic uncertainties.
- **Net Income Growth:** Expected modest increase of 1-2% year-over-year, impacted by increased operational costs and margin pressures.
- **Earnings Per Share (EPS):** Anticipated growth at a similar rate of 1-2%, potentially reaching $1.64 to $1.65 for fiscal year 2025.
- **Gross Margin:** Likely to remain under pressure, potentially declining further to 54-55%.
Overall, the outlook is bearish, with Zeko facing significant challenges that may impede its ability to outperform the market in fiscal year 2025.
今回は user1 がプライベートドキュメント private-doc.md へのアクセス権を持つユーザーであることが記載されたタプルを追加したため、予測情報を含む応答を取得できました。
まとめ
これで、FGA を使用した RAG パイプラインを実行できました。本記事では、開発者が生成 AI アプリケーションを作成する際に直面する課題、特に RAG ベースのシステムにおける情報アクセス制御に関する課題について紹介しました。
また、機密情報の漏洩を防ぐために Okta FGA を使用したシンプルな RAG アプリケーションを実装するコードを試しました。Okta FGA はオープンソースの OpenFGA 上に構築されており、GitHub 上の OpenFGA も確認ください。
最後に、いくつか良い知らせがあります。現在、LlamaIndex、LangChain、CrewAI、Vercel AI SDK、GenKit といった優れた 生成 AI フレームワークと協力して、より多くのコンテンツやサンプルアプリを準備しています。Auth0 for AI Agents は、生成 AI アプリケーションにおけるユーザー情報を保護するためのリリース予定の製品です。詳細や質問については、Auth0 Lab Discord サーバー に参加してください。
About the author

Jessica Temporal
Sr. Developer Advocate