
Not every user has access to all data, and you, as a developer of a GenAI-powered application, need to ensure that the information provided by the model complies with the access control policies in place. Fine-grained authorization (FGA) is the way to safeguard the data, and we are here to help you understand how to do it.
Understanding the Basics: AI, LLMs, and RAG Explained
It is impossible to deny that generative artificial intelligence (GenAI) is everywhere these days. Most of the time, when folks use the term AI nowadays, they mean GenAI, and folks even use AI to mean Large Language Models (LLMs), but they do not mean the same thing. Artificial Intelligence is an area of science that is focused on giving computers the ability to learn, reason, and act in a similar way to how humans would act.
Defining GenAI and LLMs
GenAI is a subset of AI focused on generating data, be it text, image, or other data formats. Meanwhile, Large Language Models are part of “AI” much like GenAI. An LLM is a machine learning model that is trained on gigantic amounts of data and is capable of understanding and responding with natural language. This means that these models take text as input and can reply in textual format, giving the impression many times that you are conversing with another thinking being.
What is RAG (Retrieval-Augmented Generation) and why use it?
Retrieving information is nothing new. We used to have a book that had the phone numbers of everyone in a given region indexed by name. You needed to know the name of the person you wanted to call in order to find the information in said book. Today, that type of information is only a query or search away.
Machine learning models are capable of a lot simply based on the data used to train them, but unless you have a way to add more information at the time of querying, that data could be outdated or incorrect or lack taking into account private or domain-specific data for example, and that’s where RAGs come into play.
RAG stands for retrieval-augmented generation. It is an architecture that improves the accuracy of LLMs by helping avoid hallucinations, which can be seen in LLMs. It can also provide more information for the LLM to formulate an answer by giving it some extra context that is either more updated than the training dataset or domain-specific.
RAGs expand the powers of a given machine learning model (usually LLMs) by adding more context than that given while the model was trained.
The Challenge of Securing Private Data in RAG and LLM Applications
Since many AI-powered applications are not only using LLMs but also RAG architecture, they have some access to resources other than the ones used while the model was trained. One concern when talking about private or sensitive data is how you can be sure that only the person who has access to a given resource will receive that information when interacting with an AI-powered application.
Think of it this way: You work as a developer for a fictional company Zeko. You have access to the company's RAG-based AI assistant, but only for domain-specific queries. That AI assistant can see everything within the cloud domain, including some private files only certain people have access to, such as the financial team that has access to the forecast for the fiscal year. You don’t, nor should have access to that data. If you ask the assistant, “Show me the forecast for ZEKO”, the assistant shouldn’t answer that query with that information, but if a colleague from the finance department asked this same question, they absolutely should be able to get that answer.
Not complying with authorization policies can lead to Sensitive Information Disclosure vulnerabilities, i.e. exposing data to users who shouldn't have access to it. So the question remains: How can we help apps leveraging RAG avoid sensitive information disclosure? One way to do this is by using Fine-Grained Authorization (FGA) and, more specifically, Okta FGA.
Introduction to FGA (Fine-Grained Authorization) with Okta FGA
Fine-Grained Authorization is more common than you think. You’ve probably used it before without realizing it. Think of the most famous use case for this: Google Drive. You can give users permission to perform certain actions on specific resources. For example, you can say that “Jess can view a document” or that “John can edit a document”, so you can have granular permissions for each user.
Following the same logic, Okta FGA is our product for developers to solve complex authorization decisions in your applications. Under the hood, it uses OpenFGA modeling language and its decision engine, which is inspired by Google Zanzibar, Google’s internal authorization system.
The great thing about Okta FGA is that it makes it easy for anyone to define the authorization model for their application, write data that is necessary to make authorization decisions, and easily query if a user can perform a certain action in relation to a specific resource.
How to Implement Okta FGA for Secure RAG Pipelines
We prepared a sample application for you to see Okta FGA in action in an RAG application. This sample app is available alongside other examples in this repository. For the purpose of this blog, you don’t have to run the code, but we recommend running it on your machine to see the concepts in action.
The Sample RAG App with Okta FGA
The sample application is written in TypeScript (there's also a Python version of this application available here). It has two types of documents: public and private. The public-doc.md contains institutional information about the fictional company Zeko Advanced Systems Inc. created for educational purposes. For example, this information could be found on the company's website. Meanwhile, the private-doc.md document contains information considered internal data, such as the 2025 forecast for Zeko, revenue, gross margin, and so on.
This application uses the OpenAI SDK, the OpenFGA SDK, and the faiss-node library:
- The OpenAI SDK will give us access to the
gpt-4o-minimodel so we can use it for the query. - The OpenFGA SDK will enforce the authorization model to avoid leaking sensitive data.
faiss-nodewill be the local vector store that we will use to index the embeddings generated from the documents.
The goal is to answer the question, “Show me forecast for ZEKO.” To do so, the client app has a user and the question in the file openai-fga/src/index.ts like so:
const user = "user1"; const query = "Show me forecast for ZEKO.";
Both the question and the user are hardcoded now, but keep in mind that when put in context of an AI-powered assistant the user would come from the authentication context and the question would come in through an interface that the authenticated user interacts with.
This client will follow the steps as outlined in the flowchart below once the FGA integration is in place:
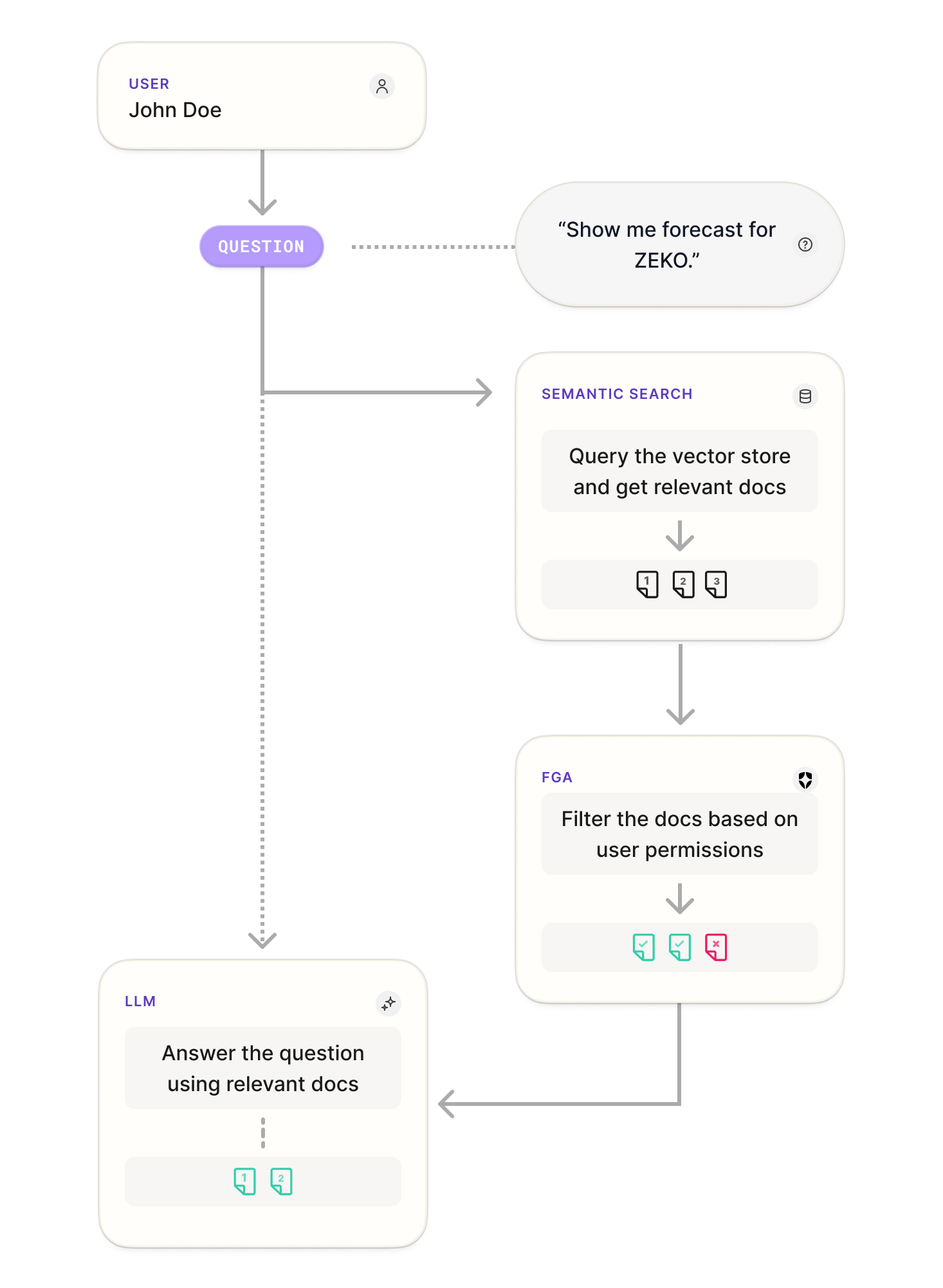
First, the user will pose the question, then the vector store is used to retrieve relevant documents based on the user query. FGA is then used to filter the documents based on user permissions, and finally, the LLM will formulate the answer taking into account the question posed and the extra document-based context based on the relevant documents. Now let’s see these steps in the code.
Setting Up OpenAI and Okta FGA Accounts
Before you can continue, you’ll need to set up Okta FGA and OpenAI API accounts. Keep in mind that you’ll only need these to run the code, but you can follow the steps to understand how Okta FGA and RAG work together.
For Okta FGA, you can go to this sign-up page directly and create your first store. A store, in this context, is an entity to organize all the authorization check data for your application. Okta FGA will use your Auth0 account, but if you are new to Auth0, you’ll be prompted to create an Auth0 account as well.
Since you’ll need to use an LLM model for this application, in this case you’ll use gpt-4o-mini model so you’ll need to create an OpenAI account and an API key to gain access to our model of choice. Use this page for instructions on how to find your OpenAI API key.
Setting Up the Sample RAG Application
In the next sections, you’ll run this application a few times, but now you can download the sample project by running the following command in a terminal window:
git clone https://github.com/oktadev/auth0-ai-samples.git
The sample app you’ll need lives in the auth0-ai-samples/authorization-for-rag/openai-fga-js folder. So navigate to it:
cd auth0-ai-samples/authorization-for-rag/openai-fga-js
Now, create the .env file and populate it as below. Remember to add your OpenAI key from the previous section.
# OpenAI
OPENAI_API_KEY=<your-open-ai-key-here>
# Okta FGA
FGA_STORE_ID=<your-fga-store-id-here>
FGA_CLIENT_ID=<your-fga-client-id-here>
FGA_CLIENT_SECRET=<your-fga-client-secret-here>
# Optional
FGA_API_URL=https://api.xxx.fga.dev
FGA_API_TOKEN_ISSUER=auth.fga.dev
FGA_API_AUDIENCE=https://api.xxx.fga.dev/
Finally, install your dependencies:
npm install
Now, let’s grab the Okta FGA-related values.
Configuring Your Okta FGA Store and Model
In the Okta FGA dashboard, navigate to Model Explorer. You’ll need to update the model information with this:
model
schema 1.1
type user
type doc
relations
define owner: [user]
define viewer: [user, user:*]
Remember to click Save, and you should see the updated preview like the image below.
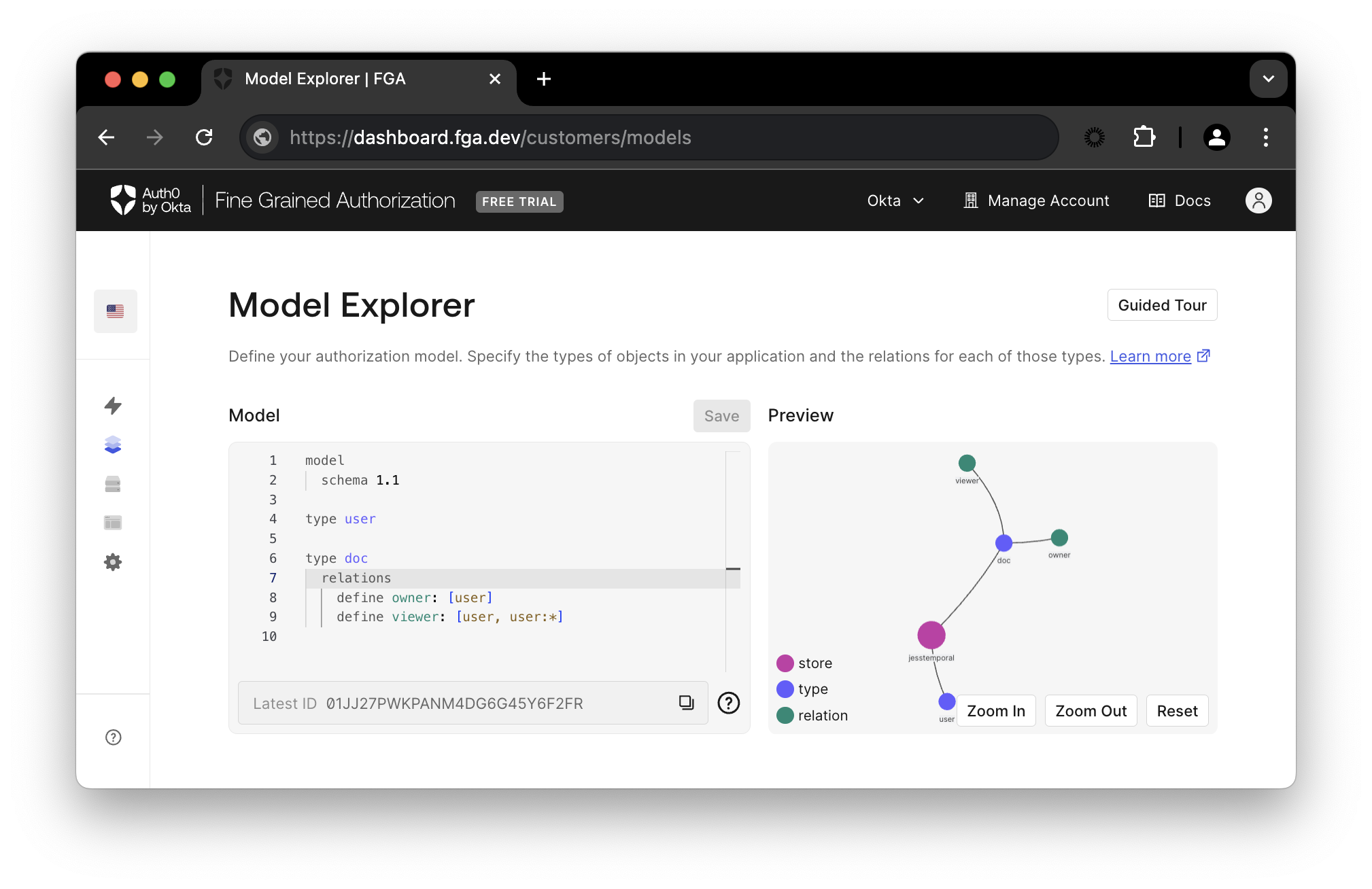
The model represents all parts involved in the application. It contains information about the relationship between users and objects (documents) as well as the type of relationship (viewer or owner).
Next, under Settings in the Authorized Clients section, click the + Create Client button. Give your client a name, mark all three client permissions, and then click Create.
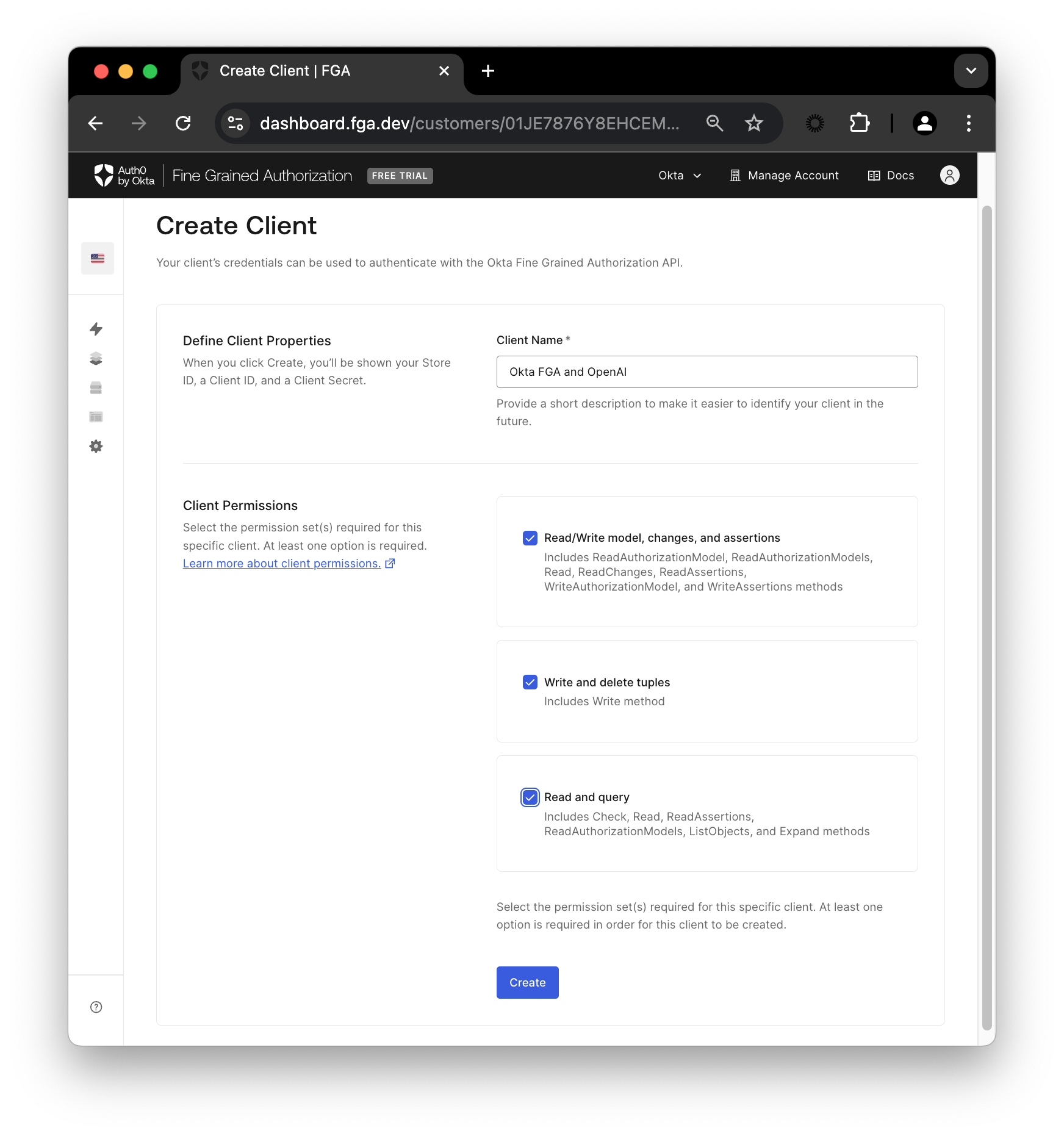
Let’s break down the permissions:
- Read/Write model, changes, and assertions: This refers to the creation and modification of the authorization model
- Write and delete tuples: Populate and manage the relations data for the authorization model
- Read and query: Finally, this one refers to querying the decision engine, i.e. checking authorization and listing objects
Once your client is created, you’ll see a modal containing all the information you’ll need in order to have your client connect to Okta FGA during the document filtering process.
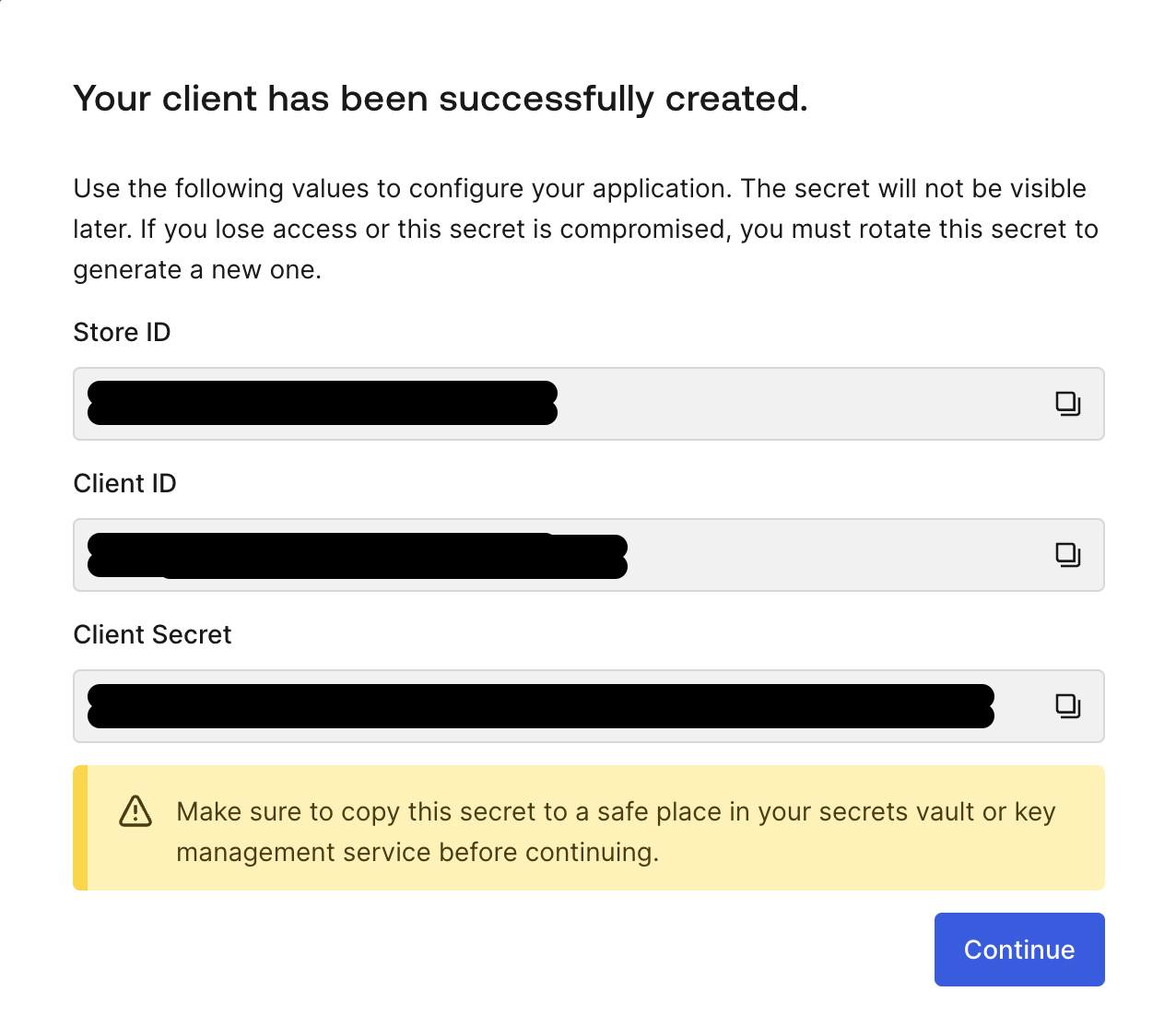
Please copy the information on the modal and update your .env file with the new values for FGA_STORE_ID, FGA_CLIENT_ID, and FGA_CLIENT_SECRET. Then click Continue.
Initializing the FGA Model and Relationship Tuples
Now, let’s initialize FGA and create first tuple by running the command below:
npm run fga:init
This will create your first tuple. In this context, a tuple signifies a user’s relation to a given object. Each relation tuple will then contain a user, a relation, and an object. For example, the tuple (user: "user:jess", relation: "viewer", object:"docs:public-doc") can be used to represent "jess is a viewer of public-doc".

After running the fga:init script, you can check your first relation tuple on your Okta FGA dashboard under Tuple Management, as seen in the image above. The tuple created gives all users access to the public documents available.
Testing your Secure RAG Application with FGA
Now that the code is set up, it’s time to run it.
Querying Without Permissions
Keep in mind that you have the question “Show me forecast for ZEKO.” defined in the client code like so:
const user = "user1"; const query = "Show me forecast for ZEKO.";
Another important note is that so far your user has no access to the private document because it does not have a tuple that defines that relationship yet. You’ll see how to create that soon.
Now run the command below.
npm start
This will print a response similar to this one:
The provided context does not include any forecasts or predictions for Zeko Advanced Systems Inc. If you are looking for specific forecasts related to financial performance, market trends, or product development, that information is not available in the documentation.
This makes sense since all the information this user has access to is in the public-doc.md, which does not contain any information about the forecasts for Zeko.
When you run the code, the RAG pipeline reads the documents that will be used for extra context, creates an FAISS index using the faiss-node library, and encodes them using the OpenAI embeddings API using the function LocalVectorStore.
const documents = readDocuments();
const vectorStore = await LocalVectorStore.fromDocuments(documents);
In order to filter out the documents based on user permissions, an instance of FGARetriever is created like so:
const retriever = FGARetriever.create({ documents: await vectorStore.search(query), buildQuery: (doc) => ({ user: `user:${user}`, object: `doc:${doc.id}`, relation: "viewer", }), });
FGARetriever wraps vectorStore.search(query) that lists documents relevant to the user query. Then, context is added by consulting both the vector database to obtain the documents that are relevant to the user query, and the FGA model to filter documents based on the permissions:
const context = await retriever.retrieve();
Finally, the query and the context are once again passed to OpenAI to generate the response using the GPT-4o mini model, and the answer is printed out in the terminal.
const answer = await generate(query, context); console.log(answer);
Querying With Granted Permissions
Now, in order to have access to the private information, you’ll need to update your tuple list. Go back to the Okta FGA dashboard in the Tuple Management section and click + Add Tuple fill in with the following information:
- User - add the value
user:user1 - Object - select
docand then add the ID in the corresponding fieldprivate-doc - Relation - select
viewer
Now click Add Tuple and then run the script again:
npm start
This time around, you should see the following result:
The forecast for Zeko Advanced Systems Inc. (ZEKO) for fiscal year 2025 is as follows:
- **Revenue Growth:** Projected increase of 2-3% year-over-year, reflecting anticipated competitive pressures and macroeconomic uncertainties.
- **Net Income Growth:** Expected modest increase of 1-2% year-over-year, impacted by increased operational costs and margin pressures.
- **Earnings Per Share (EPS):** Anticipated growth at a similar rate of 1-2%, potentially reaching $1.64 to $1.65 for fiscal year 2025.
- **Gross Margin:** Likely to remain under pressure, potentially declining further to 54-55%.
Overall, the outlook is bearish, with Zeko facing significant challenges that may impede its ability to outperform the market in fiscal year 2025.
This time, you get the response with the forecasts because you added a tuple that specifically outlines that user1 is a user with access to the private document private-doc.md.
Recap
Congratulations, you just ran a RAG pipeline with FGA! In this blog post, you learned about the challenges developers face when creating GenAI applications, especially when it comes to access control of information in RAG-based systems.
You’ve also had a chance to try out some code that implements a simple RAG application with Okta FGA to avoid sensitive information disclosure. Okta FGA is built on top of OpenFGA which is open source and we invite you to check out OpenFGA code on GitHub.
Before you go, we have some great news to share: we are working on more content and sample apps in collaboration with amazing GenAI frameworks like LlamaIndex, LangChain, CrewAI, Vercel AI SDK, and GenKit. Auth0 for AI Agents is our upcoming product to help you protect your user's information in GenAI-powered applications. Make sure to join the Auth0 Lab Discord server to hear more and ask questions.
About the author

Jessica Temporal
Sr. Developer Advocate