
TL;DR: Auth0’s private and public cloud offerings are converging on a single platform to deliver an increase in business agility, developer productivity, scalability, reliability, and security for our customers and Auth0 by using industry-leading tools and fully automated operations.
Initially, Auth0 evolved our public and private cloud offerings as separate platforms because we could go fast and innovate on the public cloud and then work through the greater performance, compliance, and control expected by our private cloud customers. But over time, this led to feature discrepancies and, frankly, just wasn’t that efficient to maintain, scale, or innovate.
So we began an ambitious replatforming project. How could we re-architect all of Auth0 into a single platform? Could we support deployments on both Amazon Web Services (AWS) and Microsoft Azure? What about increasing geo-failover options? And we needed to continue our 99.99% SLA across both public and private clouds.
Let’s not forget that private cloud customers may also require extra add-ons like data residency, private links, and dedicated performance. This post will walk you through our approach to rearchitecting Auth0 to address those challenges.
The Convergence Starting Point
While both platforms worked exclusively on AWS cloud, the private cloud was not using cloud-native solutions. It had three tiers — Basic, Perf, and Perf+ — available as environment sizes. These were selected based on the number of users and requests per second, versus an elastic scalable public cloud environment shared by multiple customers. The main difference is that private deployment usefully isolated and dedicated resources in any region. In comparison, public deployment uses shared resources for multiple customers in specific regions (United States, Europe, Japan, and Australia).
Our public cloud saw new features delivered on a weekly basis, but due to limited automation, our private cloud required high-touch operations for upgrading to new releases that rolled out on a bi-weekly cadence.
Requirements for private cloud deployments set it up as a superset of the public cloud offering that already guarantees a 99.99% SLA, with a track record of 99.99+% over the last three years. This was across three availability zones and a geo-failover for regional redundancy and availability.
But we knew we also wanted to include extra add-ons like private links, PCI compliance, and meet the customer requests for Azure Cloud support.
New Cloud-Native Architecture
On a high level, the new cloud-native architecture delivers an increase in business agility, developer productivity, scalability, reliability, and security for our customers and Auth0 by using industry-leading tools and fully automated operations.
It closes the gap between Auth0 public and private deployments by packaging all the product features in a single software version and making them available depending on the customer subscription and add-ons.
The ideation for the new platform is based on the following premises:
- Multi-cloud: AWS and Azure cloud support through a common interface
- Container orchestrated: use of container images instead of installing packages
- Stateless: scalable and replaceable by design
- Immutable: run only trusted code and configuration
- Fully automated: provisioning, upgrades, and decommissioning are done by machines
- GitOps: enhanced DevOps, push code and safely reproduce it thousands of times
This removes the worry about the underlying infrastructure, allowing Auth0 developers to place their focus on our customers. This can be represented by the layers in the box below:
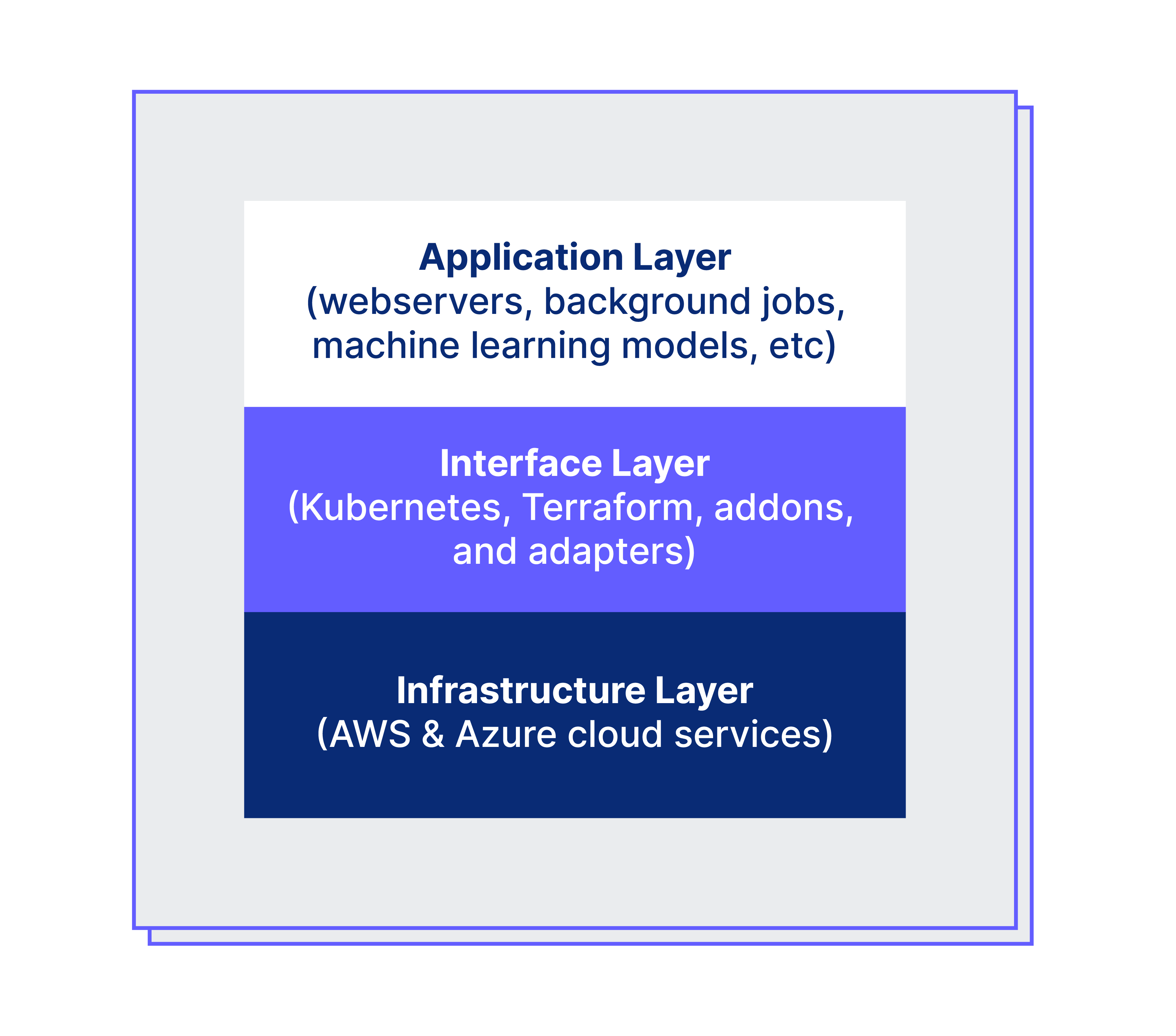
- Infrastructure layer: It builds the infrastructure using AWS and Azure cloud services such as networking, virtual machines, key management, load balancers, container repositories, Kubernetes, and managed datastores (Mongo, PostgreSQL, Redis, Kafka).
- Interface layer: Terraform is used for bootstrapping the infrastructure using code on different clouds. Vault is used for platform secrets management and Kubernetes as de-facto technology for application runtime along with custom plugins to describe services manifest, configuration, and secrets using the platform control plane component. Argo CD is a GitOps continuous delivery tool used for applying for new software releases while Argo Workflows is used for orchestrating the provisioning, upgrades, and decommissioning steps. This layer also contains integrations and agents for managing service discovery/DNS, logs, metrics, security audit, and datastores.
- Application layer: It is where the containers run. The Auth0 Identity Platform is built to allow multiple stacks with different sets of containers deployed accordingly to their usage. Auth0 products, PoP, Control Plane, and Central Services use a promotion pipeline for validating new releases and configurable release schedules. Everything is managed by control plane API and developers interact with the new platform CLI or Hub (web interface). One might wonder how identity is managed to access Kubernetes resources, it uses Pomerium with Auth0 Identity Provider, dogfooding our own product.
Before we go deep into the technical details, the blog A Primer on the New Private Cloud Platform provides more details about the Space, PoP, Control Plane and Central components of the new platform.
The Components—A Ten Thousand Foot View
The diagram below demonstrates the main components of the platform and its links, including data flows and cloud regions. Internal services and network details are omitted.
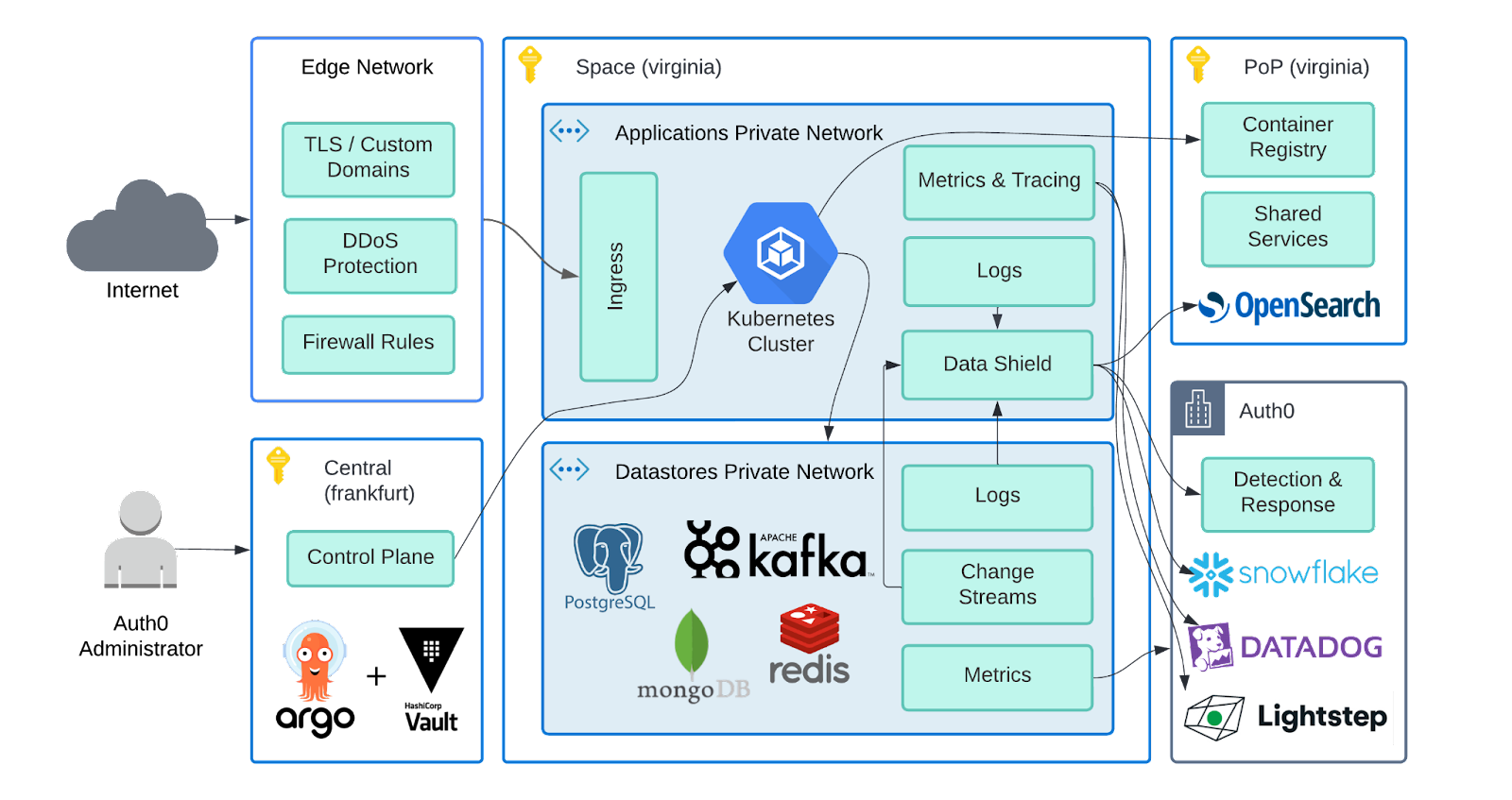
Edge Network: The global network provider, used by Auth0 for DNS, edge computing, CDN, DDoS protection, web application firewall, custom domain certificates, and speed-up end-user experience.
Space: Customer environment containing the dedicated application and datastores resources, deployed in any cloud region, maintaining security and data residency through tight access control for operators. Datastores use dedicated private networks isolated from the applications. New application deployments spin a whole new application cluster containing the new version and then slowly switch the traffic using a 'canary deployment' strategy. In addition to that, 'Data Shield' component is responsible for receiving a variety of data such as application logs and then scrubbing it, removing any PII or sensitive information. Only the clean logs are ingested and clean data is forwarded to Auth0 data analytics and detection & response teams for monitoring the system. The customer data never leaves the cloud region (e.g. Azure EastUS).
PoP: Point of presence of the platform in a given cloud region (same as the Space), required to host the container registry of software stacks used by the Kubernetes cluster. This component runs a set of shared services to support the platform, including the OpenSearch stack used by operation engineers to troubleshoot issues. It also runs regional services, shared between Spaces to support platform operations, such as forwarding data analytics, and internal Auth0 system supporting services requiring low network latency for fulfilling requests. It is important to note though that PoP doesn't have access to the Spaces network, it acts as a regional endpoint.
Central & Control Plane: A region in the European Union (EU) where the control plane services are deployed. They are internal to Auth0 operators and are used to interact with the customer Spaces and PoPs. It is secured by Zero Trust model and manages platform secrets and metadata using Terraform, Vault, and Argo. In addition to the control plane services, the central component is also designed to run other completely isolated application stacks to host global services accessible by customers and support engineers.
Auth0: The analytics aggregated data is sent to Auth0 headquarters and other global systems such as DataDog and Snowflake to be consumed by internal teams in many different departments, such as business analytics, customer support, and engineering teams. The data is categorized into different levels of access and doesn't identify any customer-sensitive information such as personally identifiable information (PII). The Detection & Response team is an exception and runs security software to analyze production traffic and usage patterns to actively detect & mitigate attacks.
High Availability and Geo-failover
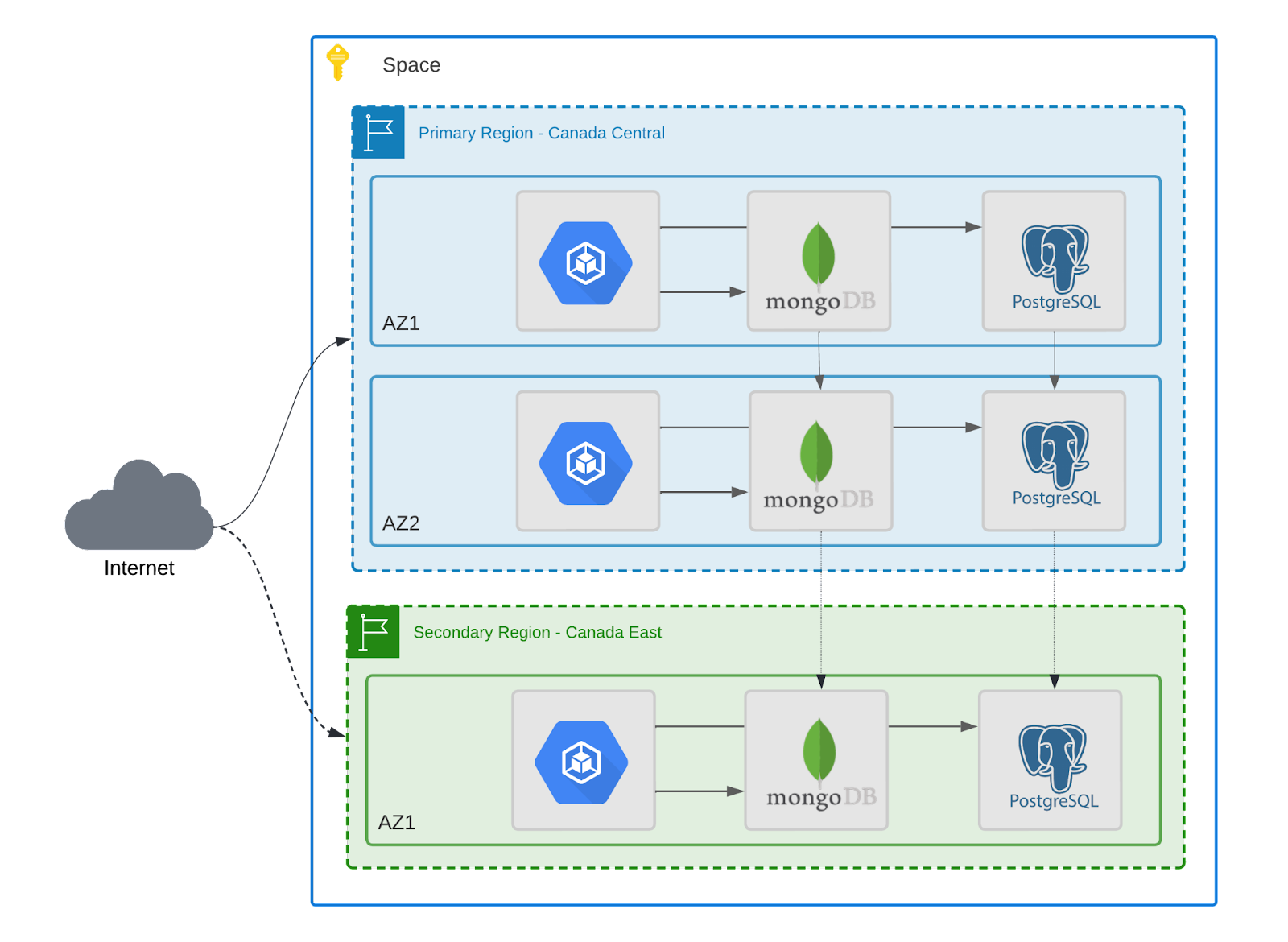
Auth0 guarantees a 99.99% SLA for production deployments. On a high level, the infrastructure is fully redundant, and all components are deployed into multiple availability zones, using at least 3 availability zones (AZ) combined primary and secondary regions, either in clustered mode or standby replicas.
For web applications, the traffic is distributed across multiple Kubernetes nodes using load balancing. For datastores, Mongo and PostgreSQL are considered the system of record, i.e. the authoritative source of data, deployed in the primary region with a writer and at least a reader node for splitting write/read traffic and replicating the data to a secondary (failover) region in real-time. The caching (Redis) and stream (Kafka) components are deployed using sharding and failover capabilities, always providing high availability for runtime and data.
As for central services, control plane, and PoPs, they also run on high availability infrastructure and have the ability to failover, while this process is executing or in case of temporary or permanent network connectivity issues, the Spaces continue functioning as expected without any disruption. Spaces are isolated from each other and are fault-tolerant to other tiers' failures.
The geo-failover is a fully automated process and is manually triggered by an operator during incident response for disaster recovery in case a cloud region is fully or partially unavailable. The process redirects all the traffic to the secondary region (determined by the customer) which switches the DNS of the cluster ingress and promotes the secondary region replicas to become the primary writer; there's no dependency on the primary region for the disaster recovery to successfully execute.
The target RPO (Recovery Point Objective) is less than a minute, the time period in which data and events can be lost due to the disaster recovery procedure. At the same time, the RTO (Recovery Time Objective) is less than 15 minutes for the amount of downtime tolerated during the disaster recovery process.
The process of failback (revert the failover) from the secondary to the primary region is the same and can be triggered once the situation resolves.
The diagram below shows the Auth0 deployment containing a primary and a secondary warm standby region with high available datastores, and for simplifying purposes other AZs running only applications are omitted:
We are publishing a series of technical posts on how and why we replatformed. They’ll be linked at the bottom of this post as they publish and are also findable on our blog. If you have technical questions or ideas for future posts, please reach out to us via the Auth0 Community. (Our marketing team also tells us we would be remiss if we didn’t include a link to talk to Sales so that is here, too.)
About the author

Leonardo Zanivan
Senior Software Architect