
Everybody is talking about microservices. Industry veterans may remember monolithic or SOA-based solutions being the way of doing things. Times have changed. New tools have allowed developers to focus on specific problems without adding excessive complexity to deployment or other administrative tasks that are usually associated with isolated services. It has become increasingly easy to choose to work with the right tool for the right problem.
In this post series, we will explore the world of microservices, how it can help solve real world problems, and why the industry is increasingly picking it as the standard way of doing things. In this series, we will attempt to tackle common problems related to this approach, and provide convenient and simple examples. By the end of the series, we should have a skeleton implementation of a full microservice-based architecture. Today, we will focus on what microservices are and how they compare to the alternatives. We will also list the problems we plan to discuss in the following posts.
Update: in part 2 we talk about the API gateway.
What is a microservice?
A microservice is an isolated, loosely-coupled unit of development that works on a single concern. This is similar to the old "Unix" way of doing things: do one thing, and do it well. Matters such as how to "combine" whatever is provided by the service are left to higher layers or to policy. This usually means that microservices tend to avoid interdependencies: if one microservice has a hard requirement for other microservices, then you should ask yourself if it makes sense to make them all part of the same unit.
“A microservice is an isolated, loosely-coupled unit of development that works on a single concern.”
Tweet This
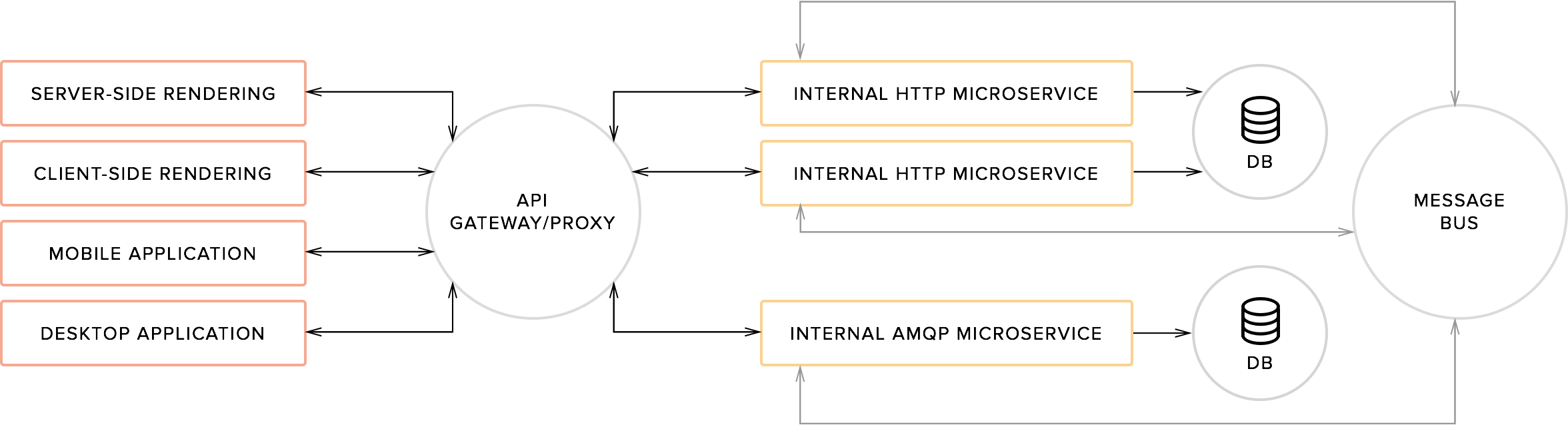
What makes microservices particularly attractive to development teams is their independence. Teams can work on a problem or group of problems on their own. This creates several attractive qualities favored by many developers:
- Freedom to pick the right tool: Is that new library or development platform something you always wanted to use? You can (if it's the right tool for the job).
- Quick iteration: Was the first version suboptimal? No problem, version 2 can be out the door in no time. Because microservices tend to be small, changes can be implemented relatively quickly.
- Rewrites are a possibility: In contrast with monolithic solutions, since microservices are small, rewrites are a possibility. Was the technology stack the wrong pick? No problem, switch to the right alternative.
- Code quality and readability: Isolated development units tend to be of higher quality and new developers can get up to speed with the existing code fairly easily.
Production-quality microservices
Now that we know what microservices are, here is a list of things we need to keep in mind when designing our microservice-based architecture. Don't worry if this seems too abstract; we will deal with all these concerns in a systematic way throughout this series of posts.
- Cross-cutting concerns must be implemented in a way such that microservices need not deal with details regarding problems outside their specific scope. For instance, authentication can be implemented as part of any API gateway or proxy.
- Data sharing is hard. Microservices tend to favor per-service or per-group databases that can be updated directly. When doing data modeling for your application, notice whether this way of doing things fits your application. For sharing data between databases, it may be necessary to implement an internal process that handles internal updates and transactions between databases. It is possible to share a single database between many microservices; just keep in mind that this may limit your options when and if you need to scale in the future.
- Availability: Microservices, by virtue of being isolated and independent, need to be monitored to detect failures as early as possible. In a big software stack, one service that goes down may go unnoticed for some time. Account for this when picking your software stack for managing services.
- Evolution: Microservices tend to evolve fast. When dedicated teams deal with specific concerns, new and better solutions are found quickly. Therefore, it is necessary to account for versioning of services. Old versions are usually available as long as there are clients who need to consume data from them. Newer versions are exposed in an application-specific way. For instance, with an HTTP/REST API, the version of the microservice may be part of a custom header, or be embedded in the returned data. Account for this.
- Automated deployment: The whole reason that microservices are so convenient nowadays is that it is so easy to deploy a new service from a completely clean environment. See Heroku, Amazon Web Services, Webtask.io or other PaaS providers. If you are going for your own in-house approach, keep in mind that the complexity of deploying new services or versions of preexisting services is critical to the success of your solution. If deployment is not handled in a convenient, automated way, you risk eventually reaching a level of complexity that outweighs the benefits originally brought about by the approach.
- Interdependencies: Keep them to a minimum. There are different ways of dealing with dependencies between services. We will explore them further later in this blog post series. For now, just keep in mind that dependencies are one of the biggest problems with this approach, so seek ways to keep them to a minimum.
- Transport and data format: Microservices are fit for any transport and data format; however, they are usually exposed publicly through a RESTful API over HTTP. Any data format fit for your information works. HTTP + JSON is very popular these days, but there is nothing stopping you from using protocol-buffers over AMQP, for instance.
Doing things right
All of these concerns can be dealt with in a systematic way. We will explore techniques and patterns in this post series to deal with them. Here is what we will be talking about in future posts:
- API proxying
- Logging
- Service discovery and registration
- Service dependencies
- Data sharing and synchronization
- Graceful failure
- Automated deployment and instantiation
Keeping it real: a sample microservice
Now, this should be easy. If microservices take so much baggage off the development team's mind, writing one should be a piece of cake, right? Yes, in a way. While we could write a simple RESTful HTTP service and call that a microservice, in this post we will do it by taking into account some of the things we have listed above (don't worry: in the following posts, we will expand this example to include solutions for ALL the concerns listed above).
For our example, we will pick the backend code from Sandrino Di Mattia's excellent post about using Flux for debugging. In Sandrino's post, a simple express.js app makes the backend for a React.js app. We will take that backend and adapt it. You can see the original backend code here.
The backend in Sandrino's example handles many different concerns: login, authentication, CORS, update operations over tickets, and queries. For our microservice we will focus on one task: querying tickets. Check it out:
var express = require('express'); var morgan = require('morgan'); var http = require('http'); var mongo = require('mongodb').MongoClient; var winston = require('winston'); // Logging winston.emitErrs = true; var logger = new winston.Logger({ transports: [ new winston.transports.Console({ timestamp: true, level: 'debug', handleExceptions: true, json: false, colorize: true }) ], exitOnError: false }); logger.stream = { write: function(message, encoding){ logger.debug(message.replace(/\n$/, '')); } }; // Express and middlewares var app = express(); app.use( //Log requests morgan(':method :url :status :response-time ms - :res[content-length]', { stream: logger.stream }) ); var db; if(process.env.MONGO_URL) { mongo.connect(process.env.MONGO_URL, null, function(err, db_) { if(err) { logger.error(err); } else { db = db_; } }); } app.use(function(req, res, next) { if(!db) { //Database not connected mongo.connect(process.env.MONGO_URL, null, function(err, db_) { if(err) { logger.error(err); res.sendStatus(500); } else { db = db_; next(); } }); } else { next(); } }); // Actual query app.get('/tickets', function(req, res, next) { var collection = db.collection('tickets'); collection.find().toArray(function(err, result) { if(err) { logger.error(err); res.sendStatus(500); return; } res.json(result); }); }); // Standalone server setup var port = process.env.PORT || 3001; http.createServer(app).listen(port, function (err) { if (err) { logger.error(err); } else { logger.info('Listening on http://localhost:' + port); } });
- One thing and one thing only: Our microservice's single concern is querying for the full list of tickets. Nothing more. Authentication, CORS and other concerns are to be handled by upper layers in our architecture.
- Logging: We have kept logging using the 'winston' library. For now we will just log to the console, but in later versions we will push logs in a predefined format to a centralized location for analysis.
- No dependencies: Our microservice has no dependencies on other microservices.
- Easily scaled: With no dependencies, a separate process, and operating on a single concern our microservice can easily be scaled.
- Small and readable: Our microservice is small and readable. New developers can modify or rewrite it in no time.
- Data sharing: For now our microservice reads data from its own database. We will explore in future posts what happens when other microservices need to update or create tickets.
- Registration and failure: Our microservice stands on its own. In future posts we will explore how to manage service discovery and what you can do in case microservices fail.
Get the code.
Conclusion
Microservices are the new way of doing distributed computing. Advances in deployment and monitoring tools have eased the pain involved in managing many independent services. The benefits are clear: using the right tool for the right problem, and letting teams use their specific know-how to tackle each problem. The hard part is dealing with shared data. Special considerations must be taken into account when dealing with shared data and inter-service dependencies. Data modeling is an essential step in any design, and is even more so in the case of a microservices-based architecture. We will explore other common patterns and practices in detail in the following articles.
About the author

Sebastian Peyrott
Senior Engineer