
In this post in the microservices series we will talk about API gateways and how they can help us solve some important concerns in a microservice-based architecture. We described these and other issues in our first post in the series.
What is an API gateway and why use it?
In all service-based architectures there are several concerns that are shared among all (or most) services. A microservice-based architecture is not an exception. As we said in the first post, microservices are developed almost in isolation. Cross-cutting concerns are dealt with by upper layers in the software stack. The API gateway is one of those layers. Here is a list of common concerns handled by API gateways:
- Authentication
- Transport security
- Load-balancing
- Request dispatching (including fault tolerance and service discovery)
- Dependency resolution
- Transport transformations
Authentication
Most gateways perform some sort of authentication for each request (or series of requests). According to rules that are specific to each service, the gateway either routes the request to the requested microservice(s) or returns an error code (or less information). Most gateways add authentication information to the request when passing it to the microservice behind them. This allows microservices to implement user specific logic whenever required.
Security
Many gateways function as a single entry point for a public API. In such cases, the gateways handle transport security and then dispatch the requests either by using a different secure channel or by removing security constraints that are not necessary inside the internal network. For instance, for a RESTful HTTP API, a gateway may perform "SSL termination": a secure SSL connection is established between the clients and the gateway, and proxied requests are then sent over non-SSL connections to internal services.
“Many gateways function as a single entry point for a public API.”
Tweet This
Load-balancing
Under high-load scenarios, gateways can distribute requests among microservice-instances according to custom logic. Each service may have specific scaling limitations. Gateways are designed to balance the load by taking these limitations into account. For instance, some services may scale by having multiple instances running under different internal endpoints. Gateways can dispatch requests to these endpoints (or even request the dynamic instantiation of more endpoints) to handle load.
Request-dispatching
Even under normal-load scenarios, gateways can provide custom logic for dispatching requests. In big architectures, internal endpoints are added and removed as teams work or new microservice instances are spawned (due to topology changes, for instance). Gateways may work in tandem with service registration/discovery processes or databases that describe how to dispatch each request. This provides exceptional flexibility to development teams. Additionally, faulty services can be routed to backup or generic services that allow the request to complete rather than fail completely.
Dependency resolution
As microservices deal with very specific concerns, some microservice-based architectures tend to become "chatty": to perform useful work, many requests need to be sent to many different services. For convenience and performance reasons, gateways may provide facades ("virtual" endpoints) that internally are routed to many different microservices.
Transport transformations
As we learnt in the first post of this series, microservices are usually developed in isolation and development teams have great flexibility in choosing the development platform. This may result in microservices that return data and use transports that are not convenient for clients on the other side of the gateway. The gateway must perform the necessary transformations so that clients can still communicate with the microservices behind it.
An API gateway example
Our example is a simple node.js gateway. It handles HTTP requests and forwards them to the appropriate internal endpoints (performing the necessary transformations in transit). It handles the following concerns:
Authentication
Authentication using JWT. A single endpoint handles initial authentication: /login. User details are stored in a Mongo database and access to endpoints is restricted by roles.
/* * Simple login: returns a JWT if login data is valid. */ function doLogin(req, res) { getData(req).then(function(data) { try { var loginData = JSON.parse(data); User.findOne({ username: loginData.username }, function(err, user) { if(err) { logger.error(err); send401(res); return; } if(user.password === loginData.password) { var token = jwt.sign({ jti: uuid.v4(), roles: user.roles }, secretKey, { subject: user.username, issuer: issuerStr }); res.writeHeader(200, { 'Content-Length': token.length, 'Content-Type': "text/plain" }); res.write(token); res.end(); } else { send401(res); } }, 'users'); } catch(err) { logger.error(err); send401(res); } }, function(err) { logger.error(err); send401(res); }); } /* * Authentication validation using JWT. Strategy: find existing user. */ function validateAuth(data, callback) { if(!data) { callback(null); return; } data = data.split(" "); if(data[0] !== "Bearer" || !data[1]) { callback(null); return; } var token = data[1]; try { var payload = jwt.verify(token, secretKey); //Your custom validation logic goes here. if(!payload.jti || revokedTokens[payload.jti]) { logger.debug('Revoked token, access denied: ' + payload.jti); callback(null); } else { callback({jwt: payload}); } } catch(err) { logger.error(err); callback(null); } }
Disclaimer: the code shown in this post is not production ready. It is used just to show concepts. Don't copy paste it blindly :)
Transport security
Transport security is handled through TLS: all public requests are received first by a reverse nginx proxy setup with sample certificates.
Load balancing
Load-balancing is handled by nginx. See the sample config.
Dynamic dispatching, data aggregation and failures
Requests are dynamically dispatched according to a configuration stored in a database. Two types of requests are supported: HTTP and AMQP.
Requests also support the aggregation strategy for splitting requests among several microservices: a single public endpoint may aggregate data from many different internal endpoints (microservices). All returned data is in JSON format. See this excellent post by Netflix on how this strategy helped them achieve better performance. Also check our post on Falcor which allows for easy data fetching from many sources.
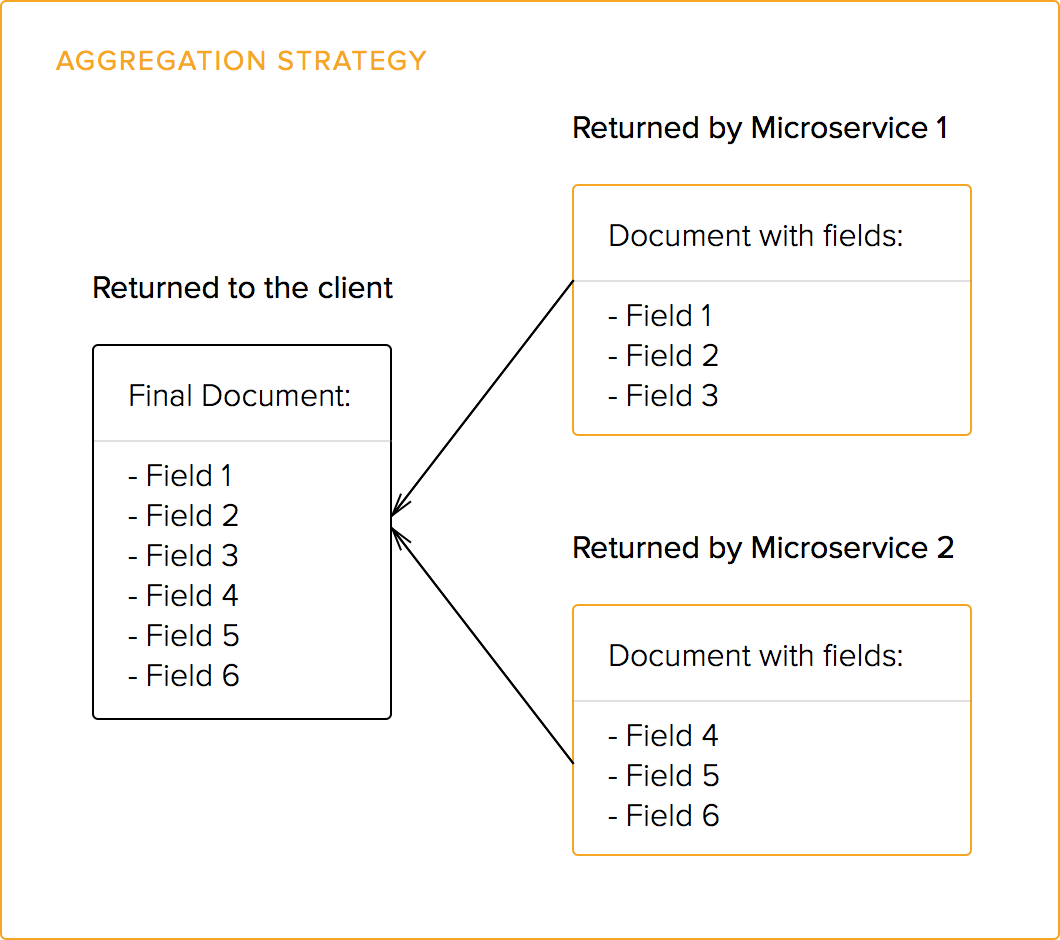
Failed internal requests are handled by logging the error and returning less information than requested.
/* * Parses the request and dispatches multiple concurrent requests to each * internal endpoint. Results are aggregated and returned. */ function serviceDispatch(req, res) { var parsedUrl = url.parse(req.url); Service.findOne({ url: parsedUrl.pathname }, function(err, service) { if(err) { logger.error(err); send500(res); return; } var authorized = roleCheck(req.context.authPayload.jwt, service); if(!authorized) { send401(res); return; } // Fanout all requests to all related endpoints. // Results are aggregated (more complex strategies are possible). var promises = []; service.endpoints.forEach(function(endpoint) { logger.debug(sprintf('Dispatching request from public endpoint ' + '%s to internal endpoint %s (%s)', req.url, endpoint.url, endpoint.type)); switch(endpoint.type) { case 'http-get': case 'http-post': promises.push(httpPromise(req, endpoint.url, endpoint.type === 'http-get')); break; case 'amqp': promises.push(amqpPromise(req, endpoint.url)); break; default: logger.error('Unknown endpoint type: ' + endpoint.type); } }); //Aggregation strategy for multiple endpoints. Q.allSettled(promises).then(function(results) { var responseData = {}; results.forEach(function(result) { if(result.state === 'fulfilled') { responseData = _.extend(responseData, result.value); } else { logger.error(result.reason.message); } }); res.setHeader('Content-Type', 'application/json'); res.end(JSON.stringify(responseData)); }); }, 'services'); }
Role checks
var User = userDb.model('User', new mongoose.Schema ({ username: String, password: String, roles: [ String ] })); var Service = servicesDb.model('Service', new mongoose.Schema ({ name: String, url: String, endpoints: [ new mongoose.Schema({ type: String, url: String }) ], authorizedRoles: [ String ] })); function roleCheck(jwt_, service) { var intersection = _.intersection(jwt_.roles, service.authorizedRoles); return intersection.length === service.authorizedRoles.length; }
Transport and data transformations
Transport transformations are performed to convert between HTTP and AMQP requests.
Logging
Logging is centralized: all logs are published to the console and to an internal message-bus. Other services listening on the message-bus can take action according to these logs.
Get the full code.
Aside: How webtask and Auth0 implement these patterns?
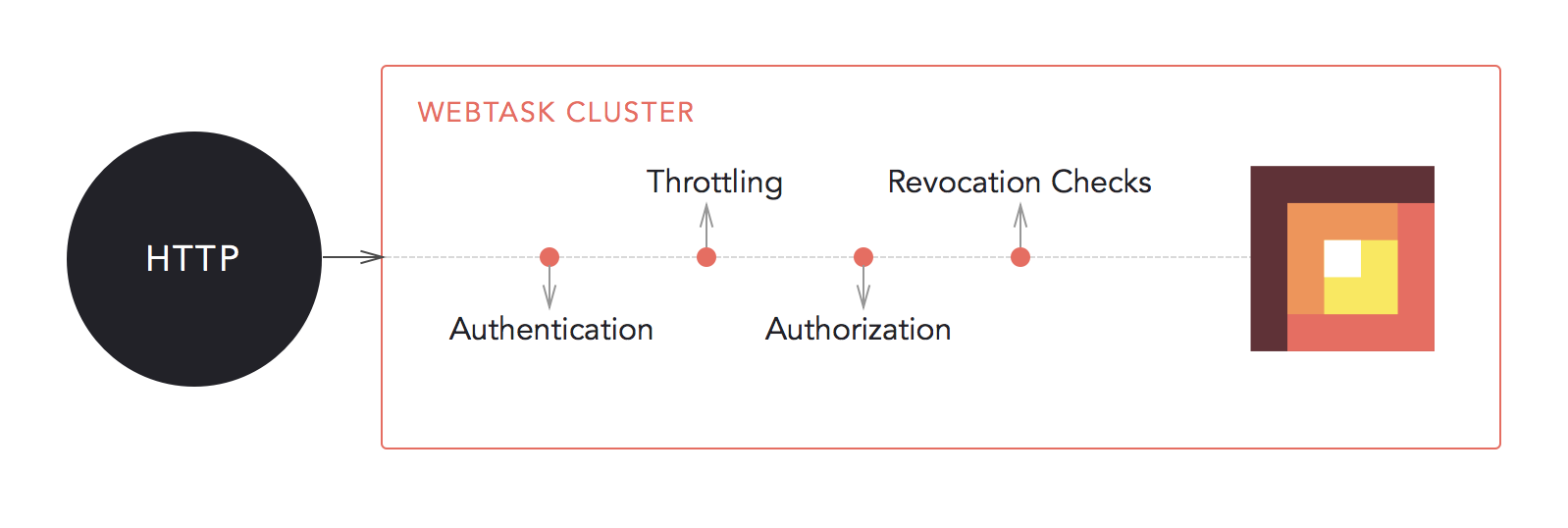
We told you about webtasks in our first post in the series. As webtasks are microservices they too run behind a gateway. The webtasks gateway handles authentication, dynamic-dispatching and centralized logging so that you don't have too.
- For authentication, Auth0 is the issuer of tokens and webtask will verify those tokens. There is a trust relationship between them so that tokens can be verified.
- For real time logging webtask implemented a stateless resilient ZeroMQ architecture which works across the cluster.
- For dynamic-dispatching, there is a custom-built Node.js proxy which uses CoreOS etcd as a pub-sub mechanism to route webtasks accordingly.
Conclusion
API gateways are an essential part of any microservice-based architecture. Cross-cutting concerns such as authentication, load balancing, dependency resolution, data transformations and dynamic request dispatching can be handled in a convenient and generic way. Microservices can then focus on their specific tasks without code-duplication. This results in easier and faster development of each microservice.
About the author

Sebastian Peyrott
Senior Engineer