Whether you are working on a complex web application, managing a hosting infrastructure, or configuring your company's applications, at some point, you’ll want to restrict or grant access to specific people, groups, or applications, depending on some properties. These can be a role or permission, the time of day or location, or the relationship between two entities. Based on your scenario and the level of complexity, one or more access control approaches might work for you.
Coarse-Grained (CGA) Versus Fine-Grained Access Control (FGA)
We can distinguish two general strategies based on how granular you want to be when making access control decisions. You either choose a coarse or fine-grained approach. A coarse-grained approach assigns permissions to a large group of users and resources. A fine-grained approach looks at the bigger picture, taking into account a lot of different data points and scenarios or assigning permissions to a more limited group of users and resources, or even unique permission per user and resource.
Both strategies have their place, and choosing the level of detail you want to include in your access control decisions might influence the paradigms you can use. For example, a role-based access control usually implements coarse-grained access control, while the relationship-based access control approach is ready to make very fine-grained decisions.
Role-Based Access Control (RBAC)
The first access control paradigm we’ll discuss in this article is role-based access control. It is the most commonly used approach and the simplest to start with. Role-based access control, as the name implies, uses a system of roles and permissions to make a decision.
A role is a collection of permissions that can be assigned to a user, and a permission indicates a certain allowed action that can be performed by any user assigned a role containing this permission. For example, a guest role might have permission to view all posts on a website, while an admin role could have both a view and delete permission attached to it.
guest: [ view:post ] admin: [ view:post, delete:post ]
Your application can either check if the current user has delete permissions or has been assigned the admin role. Either scenario will let your app know the user should be able to delete posts. Checking for permissions over roles offers the benefit that your application doesn’t need changes when roles and their permissions change over time.
To get the roles or permissions, your application typically requests them from a user-info endpoint, or your authorization server adds them to the access and/or ID tokens issued when the user is authenticated.
Because we check for permission based on a resource type rather than a specific resource like post x or post y, RBAC is an example of a coarse-grained access control approach.
Attribute-Based Access Control (ABAC) or Policy-Based Access Control (PBAC)
ABAC or PBAC is an access control strategy in which a decision is made based on assessing attributes related to a request or situation. Policies define how these attributes are evaluated. The most common types of attributes are user (role, job title, security level), environment (time of day, location), resource (resource type, data sensitivity), and action (read, write, delete). Combining multiple attributes into one or more policies offers a highly customizable and fine-grained solution to grant or limit actions within your applications or systems. The more policies you create, the more control you have over your access decisions, but the harder it becomes to maintain these policies.
An attribute-based access control system often consists of at least a decision engine and a policy language you can use to describe scenarios and their outcome. The same is true for ReBAC, but more on that later.
The decision or policy engine will evaluate data presented in a request against one or more policies written in the policy language. The downside is that you first need to gather the relevant data before passing it to the decision engine for evaluation. This often requires some extra database lookups.
If, for example, you’d like to check if a user can view a document in a parent folder owned by the same user, you’d first need to read the document database table. You'd then search the parent folder for that document and check if a user has access to that folder. Once you’ve done the lookup, you can pass this information to the policy engine to make an informed decision.
Open Policy Agent (OPA)
Open Policy Agent (OPA) is a declarative policy engine that strongly focuses on access control for infrastructure like Docker or Kubernetes containers. Their homepage describes OPA as “Policy-based control for cloud-native environments, flexible, fine-grained control for administrators across the stack.”. This doesn’t mean you can’t use it for other use cases, but it is best suited for managing infrastructure access.
Open policy agents are usually deployed as a “sidecar” beside your applications or infrastructure. This sidecar contains all policies and some relevant data in JSON files. If you run multiple applications, containers, or clusters, it can become a difficult chore to keep all policies and data up-to-date across all OPA sidecars.
Let’s look at an example. If a request comes from an origin we have on a disallow list, the policy engine will return a negative decision. For this to work, we would have written a policy that specifies that the engine looks through a list of blocked origins and checks if the origin, which is part of the request to the decision engine, is part of that list.
OPA policies are written in REGO, a generic programming language that allows you to write detailed policies. Because it is a generic language, it has a steep learning curve and usually takes some time to get used to.
Some pseudocode for the example above written in the REGO language would look like the following.
deny[reason] { disallowedOrigins := ["blocked.com","malicious.com"] some input.request.origin in disallowedOrigins reason := sprintf("origin %s has been blocked", [input.request.origin]) }
Because Policy engines are usually built to make split-second decisions by evaluating a limited dataset against a mostly static set of policies, they are perfect for infrastructure scenarios without constant changes to the data or the policies. Therefore, there’s no need for a scalable, consistent way to add or remove decision data within these engines.
This might become an issue when dealing with application access control, especially if your application deals with many users who create or manage content. Each time a user performs an action, your application needs to gather all relevant data points before passing them on to the policy engine. Because of this, the latency of your request depends more on how much time it takes to gather this information than on how fast your decision engine can evaluate its policies. As your application scales, so does your data. These lookups can become a bottleneck for fast and reliable access control decisions.
Luckily, the next access control strategy I want to discuss, relationship-based access control, is built just for these use cases.
Relationship-Based Access Control (ReBAC)
Relationship-based access control is a strategy that offers a fine-grained control based on looking at relationships between users and resources, or between multiple (different) resources.
Most ReBAC implementations today are based on Google's Zanzibar paper. In this paper, they describe the system they’ve built internally to handle a variety of access control scenarios across the whole Google ecosystem. This system needs to be flexible enough to handle authorization scenarios for their varied range of products and fast enough not to impact the user’s experience with them.
To learn more about the Zanzibar paper, visit our informational website zanzibar.academy.
Just like attribute-based access control, ReBAC usually has a decision engine and a modeling language that lets you define relationships the engine will evaluate. New to this paradigm is a database that stores a large and ever-changing set of data related to all users and resources and their relationships. Whenever a user performs an action, this dataset can be impacted.
OpenFGA
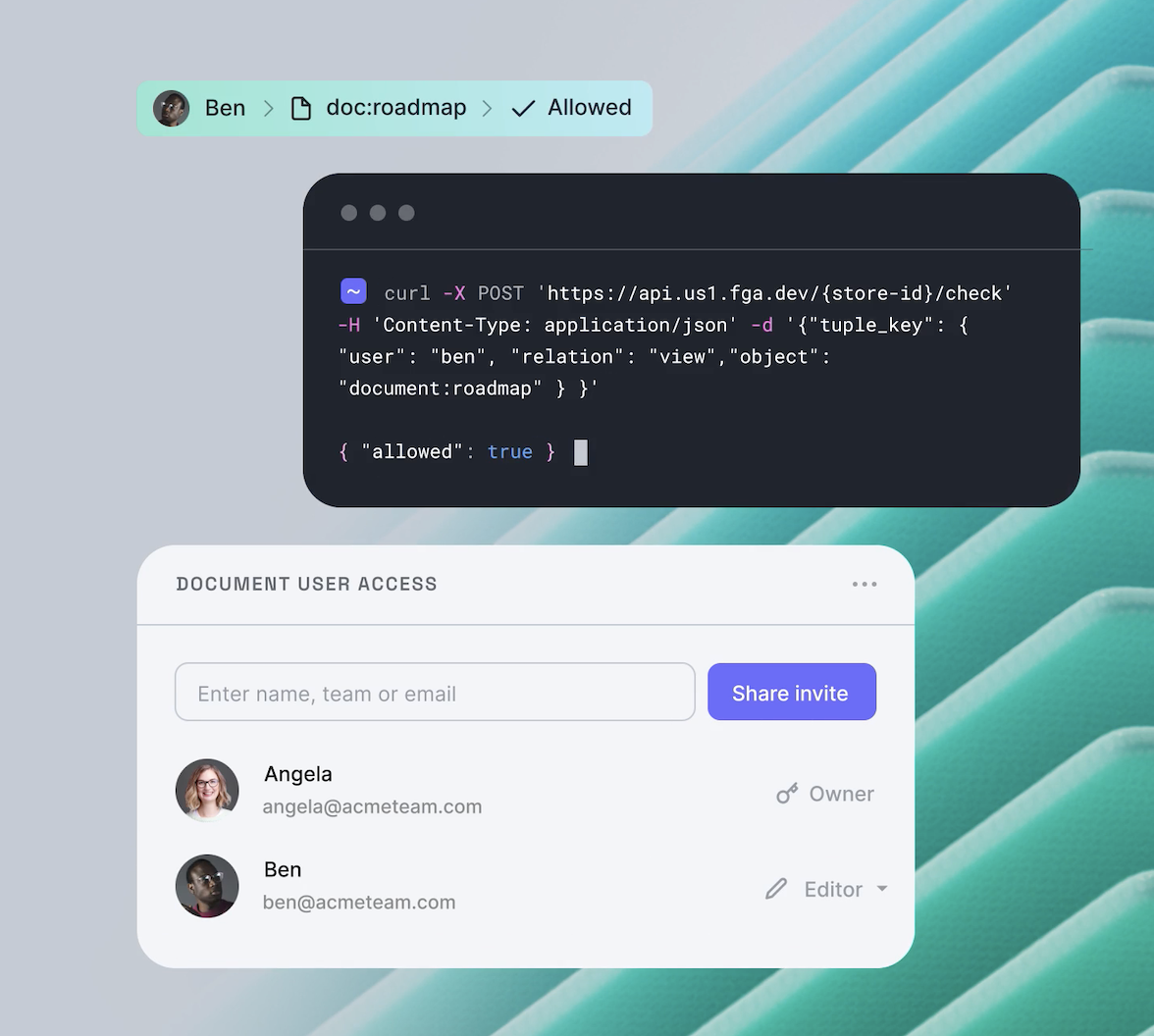
OpenFGA is an open-source solution for Zanzibar-style ReBAC access control. It’s been adopted by the Cloud Native Computing Foundation (CNCF) and actively worked on by members of Okta and the open-source community. OpenFGA uses an easy-to-read domain-specific language (DSL) to model the authorization model and exposes an API to add tuples to a database or query for access control decisions.
Okta FGA is built on top of OpenFGA and takes away the headaches of hosting, scaling, securing, and backing up your data. Find out more at fga.dev.
Direct versus indirect relationships
The relationships defined in the authorization model can be either direct or indirect. Simply put, direct relationships are directly assigned between a consumer and a resource (we call them user and object) and stored in the database. Indirect relationships are the relationships we can infer based on the data and the authorization model.
We can write our first simple authorization model using OpenFGA DSL to define a user and a repository type. A repository can have a user or multiple users as a relation. Knowing this, we can assign a user as the owner of a GitHub repository by saving the following tuple in the database:
type user type repository relations define owner: [user]
{ user: "user:sam", relation: "owner", object: "repository:fga-demo" }
When we ask the decision engine whether user Sam is the owner of the fga-demo repository, the engine looks in the database, finds the tuple, and gives us a positive response.
The true power of ReBAC lies in its ability to calculate indirect relationships—relationships that are not explicitly defined but can nonetheless be found between a user and an object. If we expand the GitHub example and add an organization, we can check whether members of that organization can commit to a repository owned by that organization, even if they are not directly assigned as a repo_writer.
type user type organization relations define member: [user] define repo_writer: [user] or member type repository relations define owner: [organization] define can_commit: repo_writer from owner
{ user: "user:sam", relation: "member", object: "organization:okta" },{ user: "organization:okta", relation: "owner", object: "repository:fga-demo" }
Given this new model and these two tuples, we can query for some direct and indirect relationships.
- Direct:
Samis amemberof theOktaorganization - Direct: The organization
Oktais theownerof thefga-demorepository - Indirect:
Samis arepo writerfor thefga-demorepository - Indirect:
Samcan commit to thefga-demorepository
By examining the relationships between users (consumers) and objects (resources) instead of a static list of roles and permissions, Rebac offers a highly flexible and powerful way to deal with fine-grained authorization decisions within applications.
Hybrid Access Control Solutions
While most access control products, services, or libraries started out with a specific approach in mind, many of them added (partial) support for other paradigms to be flexible, all-in-one solutions.
Using OpenFGA, Contextual Tuples allow authorization checks that depend on dynamic or contextual relationships not written to the OpenFGA store, enabling some attribute-based access control (ABAC) use cases. For example, allow or disallow an action based on the time of day. You can also use conditions to make your authorization models more flexible.
OPA was originally created to deal with ABAC for infrastructure. There are some initiatives, like TOPAZ, that are adding a database to the system, allowing it to make decisions on a larger, more dynamic dataset, just like ReBAC does, avoiding the need to gather all relevant data before asking your policy engine for a decision.
OPAL is another initiative that adds an administration layer to OPA. This layer helps you sync the policies and data in your OPA sidecars across your agents.
Conclusion
There is no magic bullet for dealing with authorization in all scenarios we, as application builders, have to face.
Considering which approach works well for your situation will help you scale your authorization decisions as your application or infrastructure grows more complex. So, ask yourself whether you’re looking for a simple role-based or finer-grained solution. An attribute or policy-based approach might work great if you're dealing with infrastructure. Still, a relationship-based approach might be the best solution for complex applications, saving you from doing some extra database lookups before making each access control decision.
About the author

Sam Bellen
Principal Developer Advocate