
TL;DR: Auth0 has replatformed our private cloud offering onto Kubernetes. As part of this new architecture, we’ve had the opportunity to apply modern practices to the data infrastructure that powers near real-time features and provides the necessary knobs for data governance.
Hello friends! Before we get started, I recommend that you check out “A Technical Primer of Auth0’s New Private Cloud Platform”, “Architecture of the New Platform”, and “Security of the New Platform”. These wonderful posts cover foundational aspects of the platform that I will build upon here.
Introduction
“Data is the new oil,” quipped Clive Humby in 2006, and the industry has been chanting “Drill, baby, drill” ever since. Just like oil, data needs to be refined/processed/transformed to unlock its full value. As the saying goes, “Necessity is the mother of invention,” so the industry has birthed an entire specialization around Data (Science, Engineering, Platform, Warehouse) to extract that value. The analogy remains apt because, just like oil, data is now being respected as a potentially hazardous material. With GDPR, CCPA, and their future brethren, we’ve come to understand the importance of proper packaging and safe keeping of our data assets. No more ziplock bags of data goop in the trunk of my Dodge Neon. Neatly stacked steel crates with big padlocks under 24/7 surveillance that can be crypto shredded at a moment's notice is the future of data management. With this New Platform initiative at Auth0, we’ve had the opportunity to apply some modern practices to our data infrastructure and take another step towards that dystopian data future.
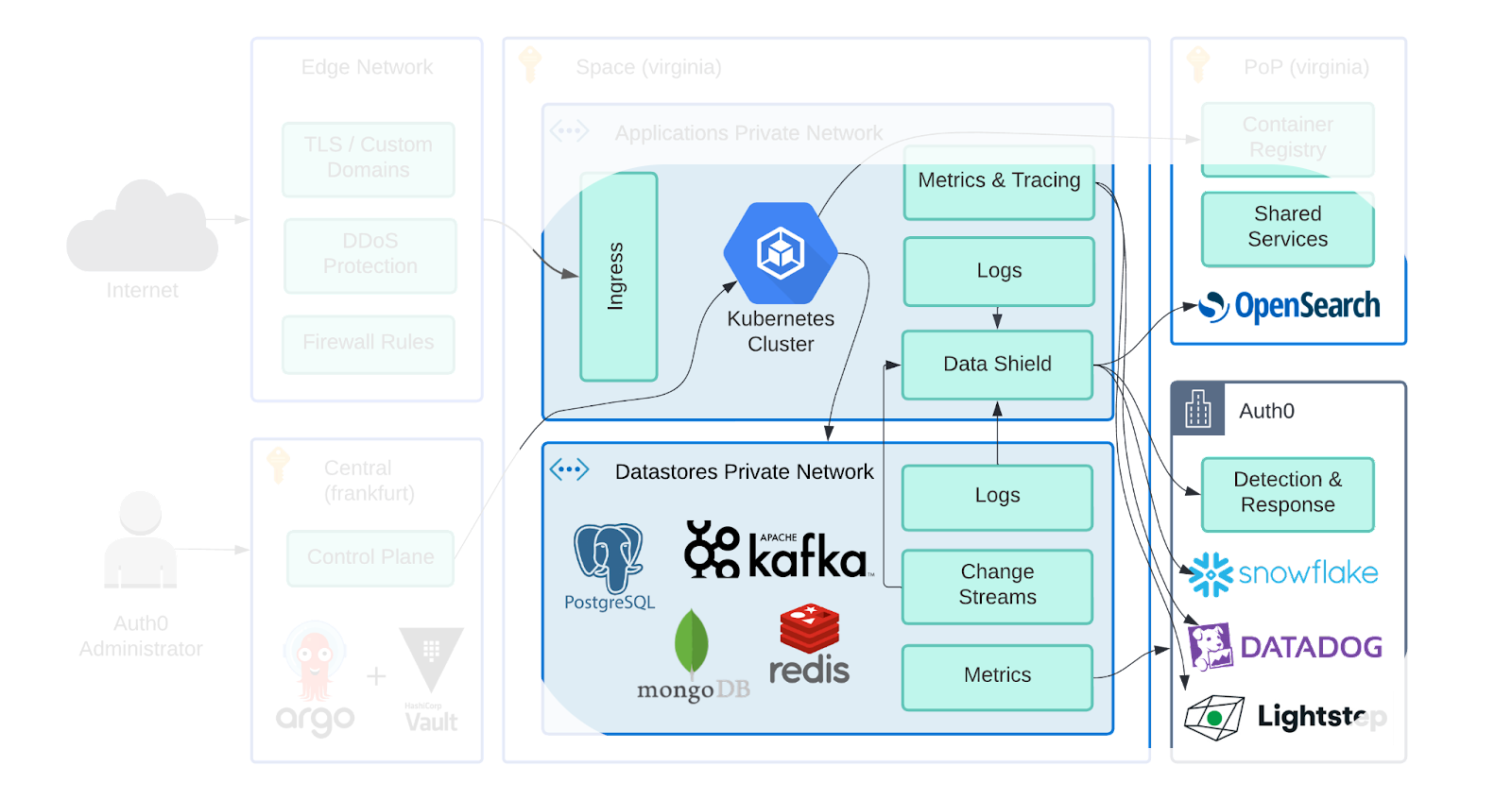
Taking a page from Leo’s 10k foot view in “Architecture of the New Platform”, we’ll be touching on the highlighted sections of the platform in this post. We’ll start with some introductory context, discuss our guiding principles, dive into the tools we chose, and then exercise them with a few sample scenarios commonly seen at Auth0.
Put down that bag of data goop, and let’s get started!
What is a Data Pipeline?
“In a world where SaaS and microservices have taken over...” — Movie Voiceover Guy
Looks around
“Hey, he’s talking about us!”
Software is on a hockey stick growth curve of complexity. We’ve got an ever-increasing number of disparate systems hoarding data and even higher demand on us to unlock value from it.
- “Show me the region where credential stuffing attacks are originating from” — A customer dashboard
- “Let me run custom code in an Auth0 Action immediately after a user is deleted” — A feature request
- “Show me failed login counts from the past 60 days for all tenants on the Performance tier that have been a paying customer for more than one year” — An upsell opportunity
Before we can begin to actually answer any of those questions, we need the connective tissue to ship data from Point A to Point B enriched with E and transformed by T. That’s the role of the Data Pipeline.
That’s not to say that Data Pipelines just carry simple domain/product events. Application logs, exception stack traces, Stripe purchase orders, Salesforce billing updates, etc., are all events that can be emitted and flow through a pipeline.
“The Data Pipeline is a series of tubes.” — Michael Scott
Eh, close enough.
Our Guiding Principles
Before jumping into implementation, it’s important to understand that our requirements are not necessarily your requirements. The decisions we’ve made might not be the correct decisions for you! When evaluating solutions and discussing tradeoffs, these are some of the key points that helped guide us.
Event Durability
Event durability is a supremely important requirement for us; missing and out-of-order events are a non-starter.
If we imagine emitting a simple event, e.g., “UserCreated,” there are a few approaches:
- Integration/domain event from application code
- Outbox Pattern
- Change Data Capture (CDC)
Discussing tradeoffs between these is a blog post in itself, so I’ll just simply say that they’re complementary and fit different needs, with the main tradeoff being durability vs. coupling.
Events emitted by application code can get lost with failures during dual writes. Outbox Pattern struggles if you don’t have strong transactional guarantees with your database of choice and doubles your write load. Change Data Capture (CDC) is the most durable of the three but “ships” the database table schema in each event, promoting unnecessarily tight coupling and having limited access to only the modified row.
Data Governance (O Data, Where art thou?)
Data Pipelines come in different shapes and sizes.
- Are messages serialized as Avro, JSON, or Protobuf? XML? Crickets.
- Are they encrypted or plain text?
- What is the expected throughput? Sustained or burst?
- Streaming or batch processing?
- Do producers retry or drop events during downtime?
- What enrichments/transforms do we need to apply?
Before discussing these technical details of a pipeline, we must first consider what is in the pipeline.
- Do messages within the pipeline contain Customer Data?
- Do messages within the pipeline need to leave the region where they originated?
If you answered “Yes” to one or more of the previous questions, calmly go outside and light your computer on fire. Joking aside, by asking and answering those questions, you can begin to understand the security/compliance posture you must take. This is likely to lead you down the road of even more questions.
- What region is data being shipped to relative to where it’s generated?
- Are we sending aggregated data or individual records?
- How is this data encrypted in transit and at rest?
- What Customer Data (down to each individual field) are we processing?
- Are there treatments that are sufficient for each field to be compliant while still fulfilling the business need? Masking, partial redaction, hashing, encryption, etc.
Remember that data is a valuable resource but can also be a hazardous material and must be handled properly. If you discover cases of processing Customer Data and shipping it across geographic boundaries, find yourself a buddy in the compliance department to help sort it out.
Inertia
Event streaming technology is an active area of development, with many new companies and products entering the space. This is great because we can stand on the shoulders of giants, but if you’re not careful, it can leave you prone to painful churn, deprecation, incompatibility, or entire products going bust.
While we don’t want to fully jump into the Boring Technology Club pool, we do want to build on robust tools that will survive a hype cycle. If a project doesn’t have enough inertia and community buy-in to survive the departure of the original stewards, it might be best to consider an alternative.
Composition
The only constant in life is changing, especially technological and business requirements. We need to consider how our technology choices can be composed, merged, bent, broken, and smeared together to get the job done. If we choose a solution too rigid, it’ll be re-written often. A solution too flexible is unlikely to be fully understood. We should try and use tools that provide a healthy balance.
It's Dangerous to Go Alone! Take This
We’re not the only company building on data pipeline technologies, thankfully. We can stand on the shoulders of those before us. Using our guiding principles outlined above, here’s the alphabet soup of open source technologies we chose to plug together to make our data go.
Kafka
The original Auth0 platform was built to run only on AWS and heavily leveraged Kinesis, SQS, and RabbitMQ. When evaluating cloud-agnostic solutions for the new platform, it was difficult to say no to Kafka. With most cloud providers offering a hosted solution (or API-compatible layer), it’s becoming the lingua franca for durable event backends. With relatively sane approaches to implementing encryption at rest or in-flight, it meets most of our needs right out of the gate.
Kafka Connect
Kafka Connect has a solid ecosystem of integrations that is relatively plug-and-play (although schema vs. schema-less can be a pain). The AWS S3 sink connector was available to us immediately, and an open-source Opensearch connector popped up quickly after the Elasticsearch license fork snafu.
Single Message Transforms (SMT) within a connector are simple mechanisms for stateless transformation/enrichment of all messages. This works well for us to inject static metadata from the new platform like Space, POP, Cloud, current deployment version, etc.
Schema Registry
Kafka Connect heavily utilizes the Confluent Schema Registry for message serialization and validation. While some connectors support “schemaless” messages, you’ll find yourself, as we have, swimming upstream if you don’t leverage the registry with these tools. We haven’t fully realized our vision here and plan further investment over the next few quarters.
Debezium
As I mentioned before, event durability was an extremely important requirement for us, so we started with Change Data Capture (CDC) powered by Debezium. With their MongoDB and Postgres source connectors, we’re immediately plugged into the Kafka Connect ecosystem.
Data Shield
When it comes to data policy enforcement for streaming messages, there didn’t seem to be many free/open-source solutions we could take off the shelf. For this, we wrote our own in-house solution in golang.
Data Shield handles data policy enforcement with schemas, data mutation, and topic muxing. With it, we can define events flowing through a topic using an IDL like protobuf. The IDL is not tied to the serialization format in the topic, e.g., we can use a protobuf IDL for JSON events.
Let’s walk through a quick example. Let’s say we emit events of Company records that have a field for their EIN.
message Company {
string name = 1;
string address = 2;
string ein = 3;
string url = 4;
}
Field enforcement is zero-trust by default, so any fields not defined in the IDL are automatically excluded. This is a critical capability for us since we receive many JSON/BSON-based events with loose schemas where fields can easily be added/removed by the upstream producer. This minimizes the blast radius of an upstream service accidentally or intentionally producing new fields with Customer Data on streams that leave the region.
Using the IDL, we annotate fields with policy details like classification and treatment rules. From our Company example, let's assume the ein field is classified as Personally Identifiable Information (PII). We could model this as:
string ein = 3 [
json_name = "ein",
(auth0.proto.options.fields.v1.classification) = {
classification: PII,
},
(auth0.proto.options.fields.v1.transform) = {
processor: {
name: OPENSEARCH,
transforms: [
{ mask: { length: 4, character: "*", reverse: true } }
]
},
processor: {
name: FRAUD_DETECTION,
transforms: []
},
processor: {
name: EU_DATA_LAKE,
transforms: [
{ drop: { } }
]
},
}
}
];
Each separate data processor of the stream can apply their own independent rules based on their business function. In this case, our Observability stack in Opensearch has the last four characters masked, our Fraud Detection feature receives the value in plain text, and the Data Lake processor in the EU doesn’t receive it at all.
With this IDL definition and some minor service configuration, we can tell Data Shield to enforce the policy on one or more topics. In the simple case, it will take the incoming “dirty” topics and output “clean” topics, one for each data processor with their specific rules applied.
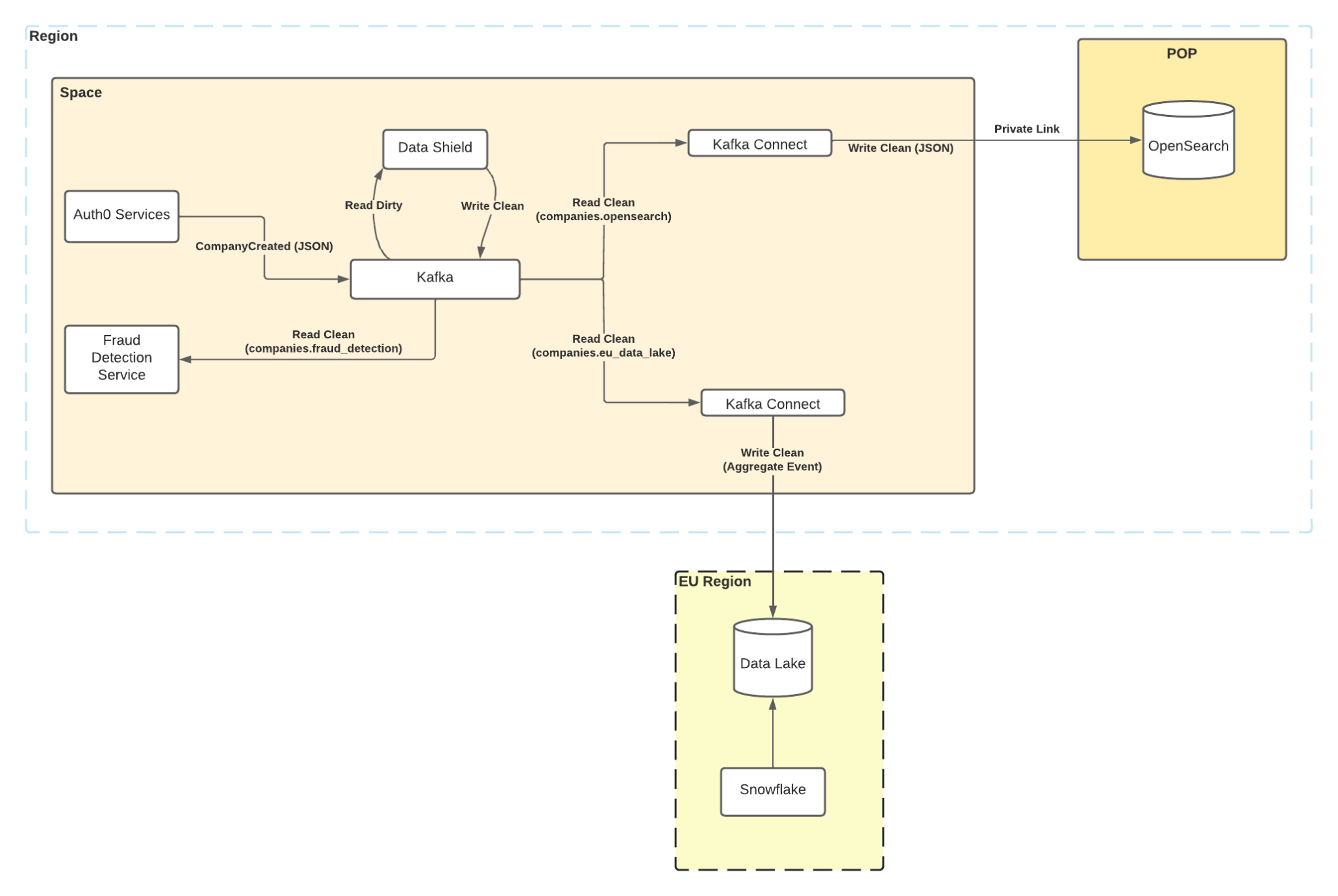
This multiplexing increases our storage costs but allows us to leverage different retention policies and Kafka ACLs so consumers can only access data from their assigned topics. While this is a cost we are (currently) willing to pay for strict data isolation, it is an area for future investment with a potential “decryption and schema enforcement on reading” strategy.
As we’ve iterated on the Data Shield concept, we’ve added a few more features to make our lives easier.
- One-to-many topic to IDL schema mapping for topics with heterogeneous message types. This is very helpful for topics that contain app/service logs.
- Schema format conversions, e.g., read JSON, write Avro
- Extend IDL to support field enrichment with generated runtime values
- Golang API for pluggable actions to modify processing pipeline as events flow through
- Rate-based sampling for sinks that can be overwhelmed
Scenarios
With our guiding principles leading us to those tools, let’s diagram out a few simplified versions of scenarios we run on the new Auth0 platform.
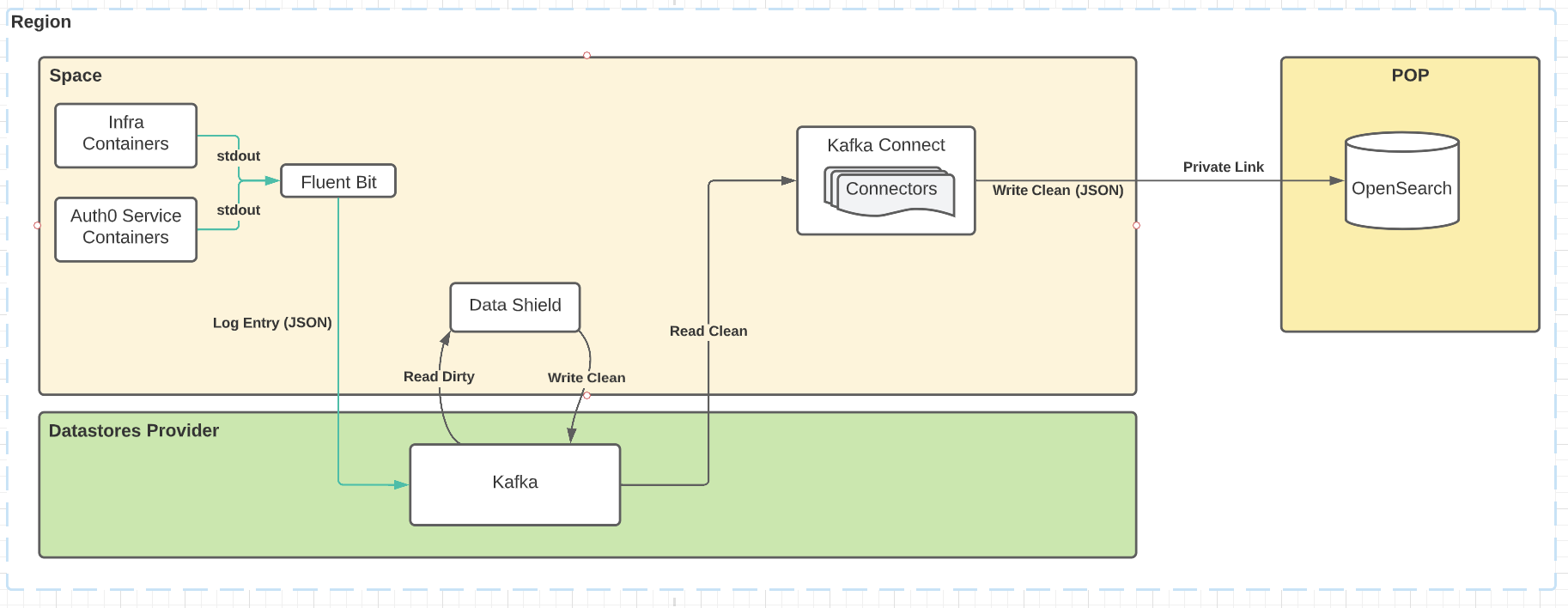
Application logs for incident response
In this scenario, we’re using Fluent Bit to consume service logs from all pods within the Space Kubernetes cluster. They’re shipped to Kafka, where Data Shield consumes the raw log messages, applies its enforcement rules, and produces them back to Kafka. They’re consumed by Opensearch connectors, who ship them across the private link to the POP, where they’re accessible to Operations teams for incident response.
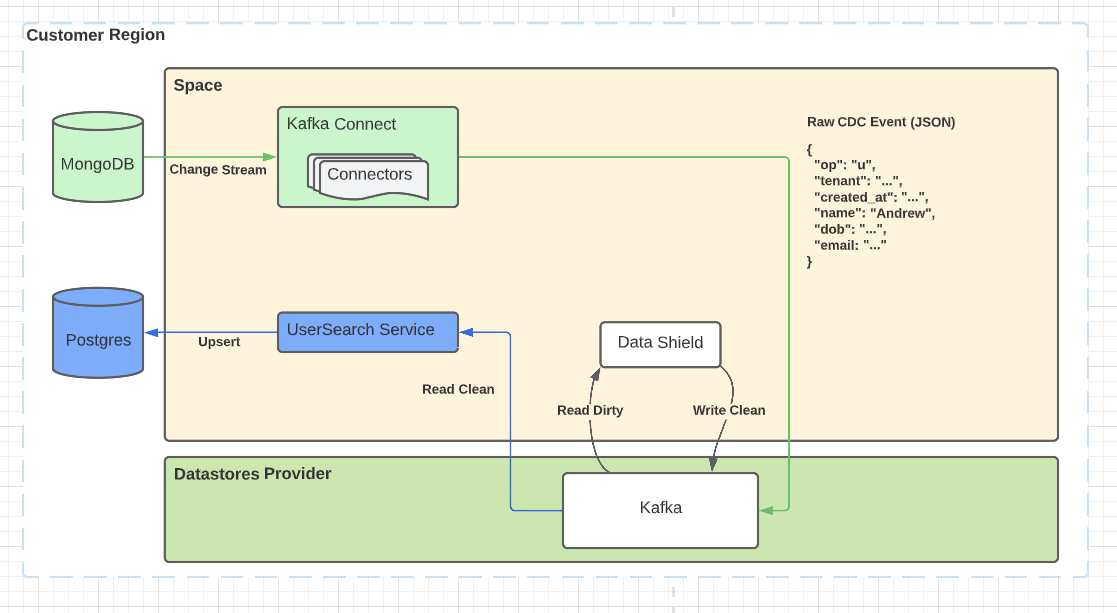
Events for autocomplete search
In this scenario, we’re using Debezium to consume MongoDB change streams to emit events for Auth0 Users into Kafka. Data Shield consumes them, applies its enforcement rules, transforms the structure, and produces them back to Kafka. They’re consumed by another service that processes them and writes them into Postgres running in the same region.
Event counts to a data lake
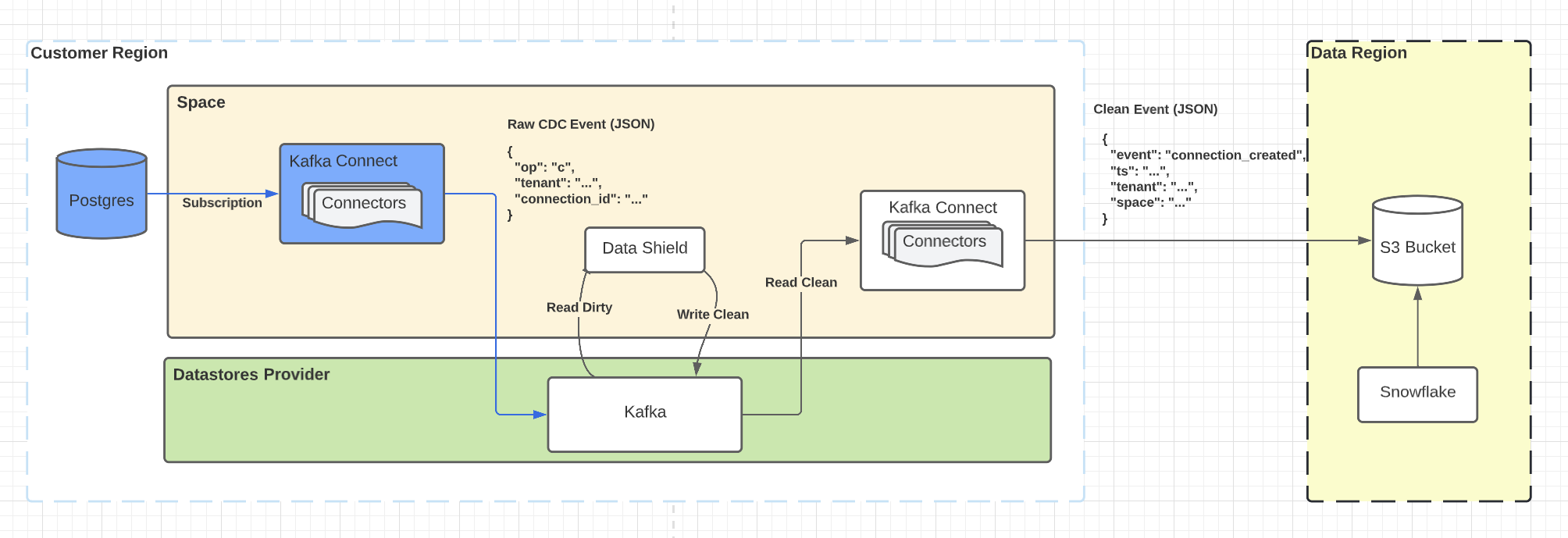
In this scenario, we’re using Debezium to consume the Postgres logical replication protocol to emit events for Auth0 Connections into Kafka. Data Shield consumes them, applies its enforcement rules, and ships them back to Kafka. They’re consumed by S3 connectors that ship them to an S3 bucket running in a different region.
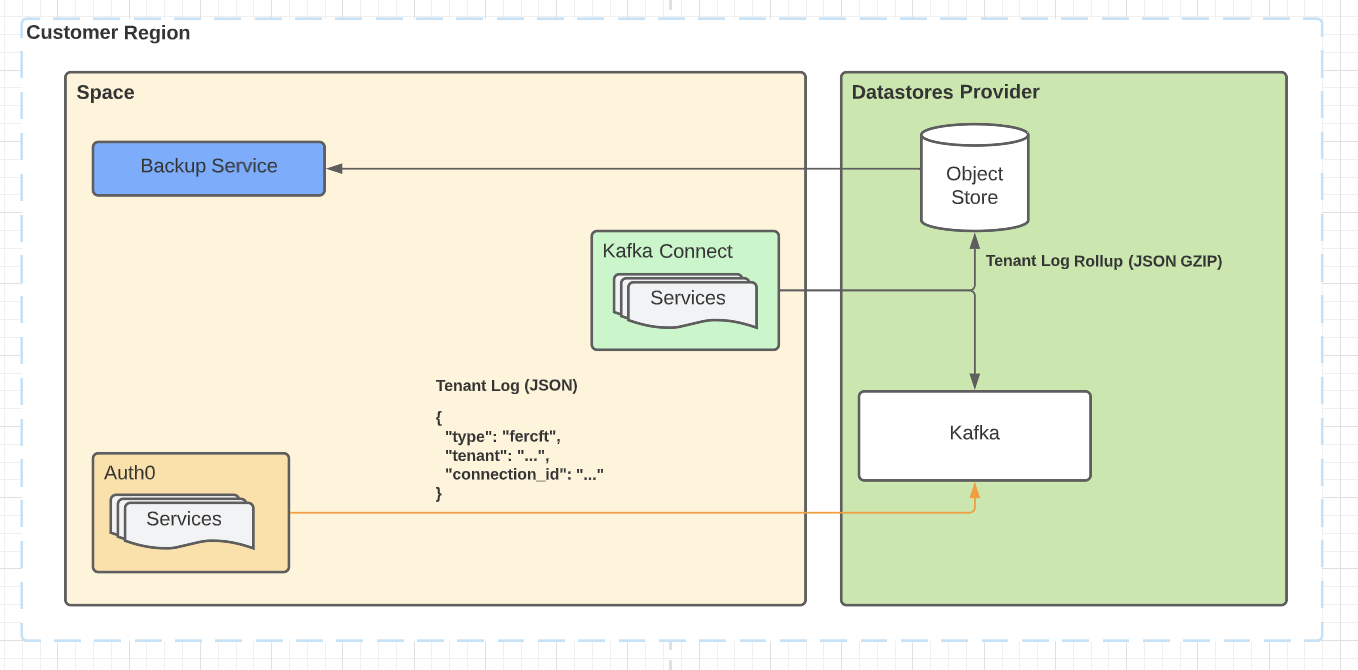
User requested backups
In this scenario, we're emitting product events for Auth0 Tenants into Kafka. Prior to processing by Data Shield, they’re backed up in-region to object storage. The backups are then periodically rolled up and offered as a data download upon user request in a dashboard.
We’re Just Getting Started
Although these sample scenarios aren’t terribly complex, they really show the power of composability. We can mix and match a few Kafka connectors with Data Shield to meet the needs of our customers while providing the data controls we require. With more data-intensive use cases on the horizon needing stream processing and OLAP databases, this composability means our pipelines can easily evolve to support them. More importantly, even with a team experienced in stream processing and OLAP databases, we’ll still plan an R&D phase to make sure our choices once again align with our guiding principles.
Interested in hearing more about streaming joins, windowing, and OLAP databases? Well, you’ll have to wait for my next blog post then! Muahaha.
I would be remiss if I did not tell you that Auth0 (and specifically my team) are hiring! Join me in building the next Auth0 data platform solving real problems for real people. Interested in solving problems for fake people instead? Visit the social network nearest you.
About the author

Andrew Hawker
Staff Engineer