
The gist of authentication is to provide users with a set of credentials, such as username and password, and to verify that they provide the correct credentials whenever they want access to the application. Hence, we need a way to store these credentials in our database for future comparisons. However, storing passwords on the server side for authentication is a difficult task. Let's explore one of the mechanisms that make password storage secure and easier: hashing.
Storing Passwords is Risky and Complex
A simple approach to storing passwords is to create a table in our database that maps a username with a password. When a user logs in, the server gets a request for authentication with a payload that contains a username and a password. We look up the username in the table and compare the password provided with the password stored. A match gives the user access to the application.
The security strength and resilience of this model depends on how the password is stored. The most basic, but also the least secure, password storage format is cleartext.
As explained by Dan Cornell from the Denim Group, cleartext refers to "readable data transmitted or stored in the clear", for example, unencrypted. You may have also seen the terms plaintext and plain text. What's the difference? According to Cornell, plaintext refers to data that will serve as the input to a cryptographic algorithm, while plain text refers to unformatted text, such as the content of a plain text file or .txt. It's important to know the distinction between these terms as we move forward.
Storing passwords in cleartext is the equivalent of writing them down in a piece of digital paper. If an attacker was to break into the database and steal the passwords table, the attacker could then access each user account. This problem is compounded by the fact that many users re-use or use variations of a single password, potentially allowing the attacker to access other services different from the one being compromised. That all sounds like a security nightmare!
The attack could come from within the organization. A rogue software engineer with access to the database could abuse that access power, retrieve the cleartext credentials, and access any account.
A more secure way to store a password is to transform it into data that cannot be converted back to the original password. This mechanism is known as hashing. Let's learn more about the theory behind hashing, its benefits, and its limitations.
“We must guard user accounts from both internal and external unauthorized access. Cleartext storage must never be an option for passwords. Hashing and salting should always be part of a password management strategy.”
Tweet This
What's Hashing About?
By dictionary definition, hashing refers to "chopping something into small pieces" to make it look like a "confused mess". That definition closely applies to what hashing represents in computing.
In cryptography, a hash function is a mathematical algorithm that maps data of any size to a bit string of a fixed size. We can refer to the function input as message or simply as input. The fixed-size string function output is known as the hash or the message digest. As stated by OWASP, hash functions used in cryptography have the following key properties:
- It's easy and practical to compute the hash, but "difficult or impossible to re-generate the original input if only the hash value is known."
- It's difficult to create an initial input that would match a specific desired output.
Thus, in contrast to encryption, hashing is a one-way mechanism. The data that is hashed cannot be practically "unhashed".
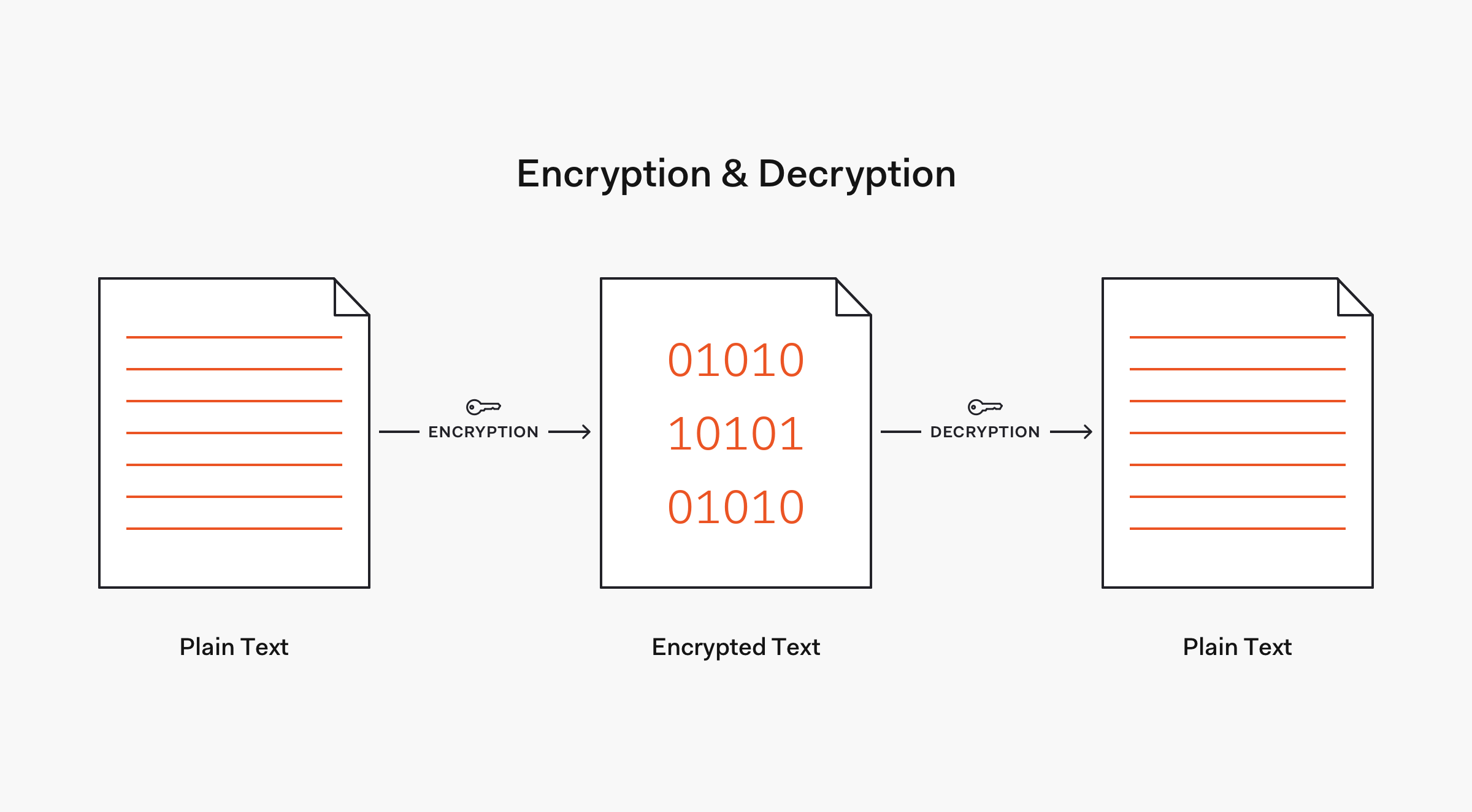
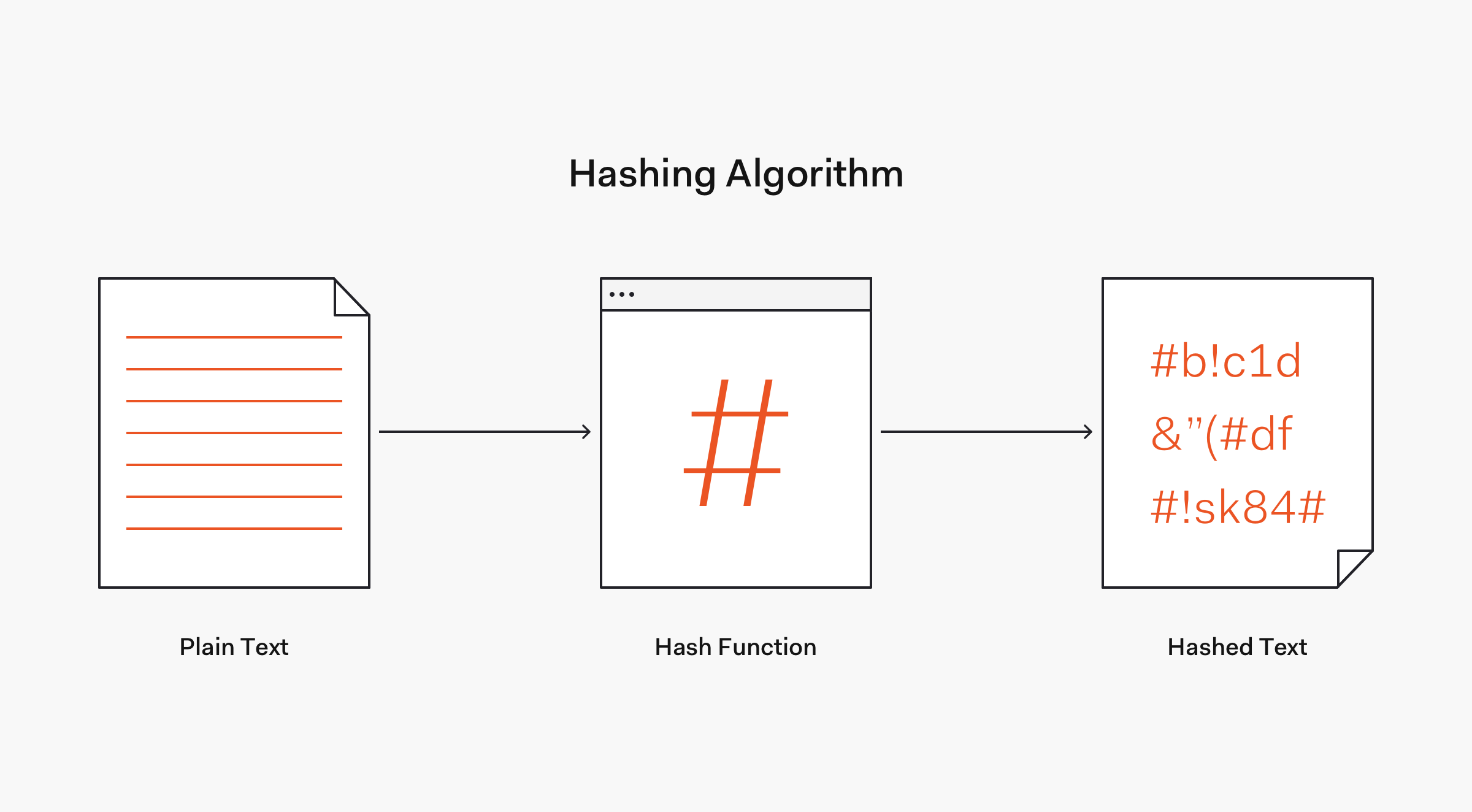
Commonly used hashing algorithms include Message Digest (MDx) algorithms, such as MD5, and Secure Hash Algorithms (SHA), such as SHA-1 and the SHA-2 family that includes the widely used SHA-256 algorithm. Later on, we are going to learn about the strength of these algorithms and how some of them have been deprecated due to rapid computational advancements or have fallen out of use due to security vulnerabilities.
In bitcoin, integrity and block-chaining use the SHA-256 algorithm as the underlying cryptographic hash function. Let's look at a hashing example using SHA-256 and Python.
If you want to follow along, you can use the online Python repl.it IDE to run Python scripts easily.
The Python repl.it IDE provides you with a code editor to enter Python code, buttons to save or run the script, and a console to visualize the script output.
In the code editor, enter the following command to import the constructor method of the SHA-256 hash algorithm from the hashlib module:
from hashlib import sha256
In the line below, create an instance of the sha256 class:
h = sha256()
Next, use the update() method to update the hash object:
h.update(b'python1990K00L')
Then, use the hexdigest() method to get the digest of the string passed to the update() method:
hash = h.hexdigest()
The digest is the output of the hash function.
Finally, print the hash variable to see the hash value in the console:
print(hash)
The complete script looks like this:
from hashlib import sha256 h = sha256() h.update(b'python1990K00L') hash = h.hexdigest() print(hash)
To run the script, click on the "run" button at the top of the screen. On the console, you should see the following output:
d1e8a70b5ccab1dc2f56bbf7e99f064a660c08e361a35751b9c483c88943d082
To recap, you provide the hash function a string as input and get back another string as output that represents the hashed input:
Input:
python1990K00L
Hash (SHA-256):
d1e8a70b5ccab1dc2f56bbf7e99f064a660c08e361a35751b9c483c88943d082
Try hashing the string python. Did you get the following hash?
11a4a60b518bf24989d481468076e5d5982884626aed9faeb35b8576fcd223e1
“Understanding blockchains and cryptocurrency, such as bitcoin, is easier when you understand how cryptographic hash functions work.”
Tweet This
Using SHA-256, we have transformed a random-size input into a fixed-size bit string. Notice how, despite the length difference between python1990K00L and python, each input produces a hash of the same length. Why's that?
Using hexdigest(), you produced a hexadecimal representation of the hash value. For any input, each message digest output in hexadecimal format has 64 hexadecimal digits. Each digit pair represent a byte. Thus, the digest has 32 bytes. Since each byte holds 8 bits of information, the hash string represent 256 bits of information in total. For this reason, this algorithm is called SHA-256 and all of its inputs have an output of equal size.
Some hash functions are widely used but their properties and requirements do not provide security. For example, cyclic redundancy check (CRC) is a hash function used in network applications to detect errors but it is not pre-image resistant, which makes it unsuitable for use in security applications such as digital signatures.
Throughout this article, we are going to explore the properties that make a hash function suitable for usage in security applications. To start, we should know that even if we were to find the details on how the input to a cryptographic hash function gets computed into a hash, it would not be practical for us to reverse the hash back into the input. Why's that?
Cryptographic Hash Functions are Practically Irreversible
Hash functions behave as one-way functions by using mathematical operations that are extremely difficult and cumbersome to revert such as the modulo operator.
The modulo operator gives us the remainder of a division. For example, 5 mod 3 is 2 since the remainder of 5 / 3 is 2 using integer division. This operation is deterministic, given the same input always produces the same output: mathematically, 5 / 3 always results in 2. However, an important characteristic of a modulo operation is that we cannot find the original operands given the result. In that sense, hash functions are irreversible.
Knowing that the result of a modulo operation is 2 only tells us that x divided by y has a reminder of 2 but it doesn't tell us anything about x and y. There is an infinite number of values that could be substituted for x and y for x mod y to return 2:
7 mod 5 = 2
9 mod 7 = 2
2 mod 3 = 2
10 mod 8 = 2
...
When using a cryptographic hash function, we must not be able to find a pre-image by looking at a hash. A pre-image is what we call a value that produces a certain specific hash when used as input to a hash function — the plaintext value. Hence, a cryptographic hash function is designed to be resistant to pre-image attacks; it must be pre-image resistant. So if an attacker knows a hash, it is computationally infeasible to find any input that hashes to that given output. This property is what makes hashing one of the foundations of bitcoin and blockchains.
If you are curious about how a hash function works, this Wikipedia article provides all the details about how the Secure Hash Algorithm 2 (SHA-2) works.
A Small Change Has a Big Impact
Another virtue of a secure hash function is that its output is not easy to predict. The hash for dontpwnme4 would be very different than the hash of dontpwnme5, even though only the last character in the string changed and both strings would be adjacent in an alphabetically sorted list:
Input:
dontpwnme4
Hash (SHA-256):
4420d1918bbcf7686defdf9560bb5087d20076de5f77b7cb4c3b40bf46ec428b
Input:
dontpwnme5
Hash (SHA-256):
3fc79ff6a81da0b5fc62499d6b6db7dbf1268328052d2da32badef7f82331dd6
Here's the Python script used to calculate these values in case you need it:
from hashlib import sha256 h = sha256() h.update(b'<STRING>') hash = h.hexdigest() print(hash)
Replace <STRING> with the desired string to hash and run it on repl.it.
This property is known as the avalanche effect and it has the desirable effect that if an input is changed slightly, the output is changed significantly.
Consequentially, there is no feasible way for us to determine what the hash of dontpwnme6 would be based on the two previous hashes; the output is non-sequential.
Using Cryptographic Hashing for More Secure Password Storage
The irreversible mathematical properties of hashing make it a phenomenal mechanism to conceal passwords at rest and in motion. Another critical property that makes hash functions suitable for password storage is that they are deterministic.
A deterministic function is a function that given the same input always produces the same output. This is vital for authentication since we need to have the guarantee that a given password will always produce the same hash; otherwise, it would be impossible to consistently verify user credentials with this technique.
To integrate hashing in the password storage workflow, when the user is created, instead of storing the password in cleartext, we hash the password and store the username and hash pair in the database table. When the user logs in, we hash the password sent and compare it to the hash connected with the provided username. If the hashed password and the stored hash match, we have a valid login. It's important to note that we never store the cleartext password in the process, we hash it and then forget it.
Whereas the transmission of the password should be encrypted, the password hash doesn't need to be encrypted at rest. When properly implemented, password hashing is cryptographically secure. This implementation would involve the use of a salt to overcome the limitations of hash functions.
Uniqueness is the key property for salts; length happens to help uniqueness.
Limitations of Hash Functions
Hashing seems pretty robust. But if an attacker breaks into the server and steals the password hashes, all that the attacker can see is random-looking data that can't be reversed to plaintext due to the architecture of hash functions. An attacker would need to provide an input to the hash function to create a hash that could then be used for authentication, which could be done offline without raising any red flags on the server.
The attacker could then either steal the cleartext password from the user through modern phishing and spoofing techniques or try a brute force attack where the attacker inputs random passwords into the hash function until a matching hash is found.
A brute-force attack is largely inefficient because the execution of hash functions can be configured to be rather long. This hashing speed bump will be explained in more detail later. Does the attacker have any other options?
Since hash functions are deterministic (the same function input always results in the same hash), if a couple of users were to use the same password, their hash would be identical. If a significant amount of people are mapped to the same hash that could be an indicator that the hash represents a commonly used password and allow the attacker to significantly narrow down the number of passwords to use to break in by brute force.
Additionally, through a rainbow table attack, an attacker can use a large database of precomputed hash chains to find the input of stolen password hashes. A hash chain is one row in a rainbow table, stored as an initial hash value and a final value obtained after many repeated operations on that initial value. Since a rainbow table attack has to re-compute many of these operations, we can mitigate a rainbow table attack by boosting hashing with a procedure that adds unique random data to each input at the moment they are stored. This practice is known as adding salt to a hash and it produces salted password hashes.
With a salt, the hash is not based on the value of the password alone. The input is made up of the password plus the salt. A rainbow table is built for a set of unsalted hashes. If each pre-image includes a unique, unguessable value, the rainbow table is useless. When the attacker gets a hold of the salt, the rainbow table now needs to be re-computed, which ideally would take a very long time, further mitigating this attack vector.
"The trick is to ensure the effort to “break” the hashing exceeds the value that the perpetrators will gain by doing so. None of this is about being “unhackable”; it’s about making the difficulty of doing so not worth the effort." - Troy Hunt
No Need for Speed
According to Jeff Atwood, "hashes, when used for security, need to be slow." A cryptographic hash function used for password hashing needs to be slow to compute because a rapidly computed algorithm could make brute-force attacks more feasible, especially with the rapidly evolving power of modern hardware. We can achieve this by making the hash calculation slow by using a lot of internal iterations or by making the calculation memory intensive.
A slow cryptographic hash function hampers that process but doesn't bring it to a halt since the speed of the hash computation affects both well-intended and malicious users. It's important to achieve a good balance of speed and usability for hashing functions. A well-intended user won't have a noticeable performance impact when trying a single valid login.
Collision Attacks Deprecate Hash Functions
Since hash functions can take an input of any size but produce hashes that are fixed-size strings, the set of all possible inputs is infinite while the set of all possible outputs is finite. This makes it possible for multiple inputs to map to the same hash. Therefore, even if we were able to reverse a hash, we would not know for sure that the result was the selected input. This is known as a collision and it's not a desirable effect.
A cryptographic collision occurs when two unique inputs produce the same hash. Consequently, a collision attack is an attempt to find two pre-images that produce the same hash. The attacker could use this collision to fool systems that rely on hashed values by forging a valid hash using incorrect or malicious data. Therefore, cryptographic hash functions must also be resistant to a collision attack by making it very difficult for attackers to find these unique values.

Source: Announcing the first SHA1 collision (Google)
“Since inputs can be of infinite length but hashes are of a fixed length, collisions are possible. Despite a collision risk being statistically very low, collisions have been found in commonly used hash functions.”
Tweet This
For simple hashing algorithms, a simple Google search will allow us to find tools that convert a hash back to its cleartext input. The MD5 algorithm is considered harmful today and Google announced the first SHA1 collision in 2017. Both hashing algorithms have been deemed unsafe to use and deprecated by Google due to the occurrence of cryptographic collisions.
Google recommends using stronger hashing algorithms such as SHA-256 and SHA-3. Other options commonly used in practice are bcrypt, scrypt, among many others that you can find in this list of cryptographic algorithms. However, as we've explored earlier, hashing alone is not sufficient and should be combined with salts. Learn more about how adding salt to hashing is a better way to store passwords.
Recap
Let's recap what we've learned through this article:
- The core purpose of hashing is to create a fingerprint of data to assess data integrity.
- A hashing function takes arbitrary inputs and transforms them into outputs of a fixed length.
- To qualify as a cryptographic hash function, a hash function must be pre-image resistant and collision resistant.
- Due to rainbow tables, hashing alone is not sufficient to protect passwords for mass exploitation. To mitigate this attack vector, hashing must integrate the use of cryptographic salts.
- Password hashing is used to verify the integrity of your password, sent during login, against the stored hash so that your actual password never has to be stored.
- Not all cryptographic algorithms are suitable for the modern industry. At the time of this writing, MD5 and SHA-1 have been reported by Google as being vulnerable due to collisions. The SHA-2 family stands as a better option.
Simplifying Password Management with Auth0
You can minimize the overhead of hashing, salting, and password management through Auth0. We solve the most complex identity use cases with an extensible and easy to integrate platform that secures billions of logins every month.
Auth0 helps you prevent critical identity data from falling into the wrong hands. We never store passwords in cleartext. Passwords are always hashed and salted using bcrypt. Additionally, data encryption is offered at rest and in transit by using TLS with at least 128-bit AES encryption. We've built state-of-the-art security into our product, to protect your business and your users.
Make the internet safer, sign up for a free Auth0 account today.
Related Documentation
About the author

Dan Arias
Software Engineer (Auth0 Alumni)