
認証の主な役割は、ユーザー名やパスワードなど一連の資格情報をユーザーに提供し、ユーザーがアプリケーションへのアクセスを希望するときに正しい資格情報を提供しているかどうかを検証することです。したがって、将来比較を行うときのために、データベースにこうした資格情報を格納する方法が必要となります。しかし、サーバー側に認証用のパスワードを格納するのは難しい課題です。ここではパスワードを安全かつ簡単に格納するメカニズムの1つであるハッシュ化について考えてみます。
パスワードの格納は複雑で危険である
パスワードを格納する簡単な方法は、データベースにユーザー名とパスワードをマップするテーブルを作ることです。ユーザーがログインすると、サーバーはユーザー名とパスワードを含んだペイロードで認証のリクエストを受け取ります。テーブルでユーザー名を探し、提供されたパスワードと保存されているパスワードを比較します。パスワードが一致すると、ユーザーはアプリケーションにアクセスできます。
このモデルのセキュリティ強度と耐性は、パスワードの格納方法によって異なってきます。最も基本的で、また安全性の低いパスワードの格納形式はクリアテキストです。
Denim GroupのDan Cornell氏の説明によると、クリアテキストとは、例えば暗号化されていないテキストなど、"平文で転送または格納された判読可能なデータ"のことです。プレーンテキストやテキスト形式という用語もよく見かけますね。どこが違うのでしょう?Cornell氏によると、プレーンテキストとは暗号化アルゴリズムへの入力として使われるデータのことですが、テキスト形式はテキスト形式ファイルや.txtのコンテンツなど、書式が設定されていないテキストのことを指します。これから先へ進むにつれて、こうした用語の違いを知っておくことが重要になります。
パスワードをクリアテキストに格納することは、デジタルペーパーに書くのと同じことです。ハッカーがデータベースに侵入してパスワードテーブルを盗んだとすると、ハッカーはその後すべてのユーザーアカウントにアクセスできてしまいます。多くのユーザーがパスワードを再利用したり、同じパスワードを少し変えて使用したりするために、ハッカーが侵入したものとは別のサービスにもアクセスが可能となり、この事態はさらに悪化します。これはセキュリティにとって悪夢でしかありません!
攻撃は組織内部からもたらされることもあります。データベースへのアクセス権をもつソフトウェアエンジニアがその権限を悪用してクリアテキスト形式の資格情報を取得したとすると、あらゆるアカウントにアクセスできてしまいます。
パスワードをより安全に格納する方法は、元のパスワードに変換し直すことができないデータにパスワードを変換してしまうことです。このメカニズムは"ハッシュ化"として知られています。そこでハッシュ化の理論、その利点や限界について説明したいと思います。
“私たちは、組織内外の不正アクセスからユーザーアカウントを守らなくてはなりません。クリアテキストは、パスワードを格納する際の選択肢であってはなりません。ハッシュ化とソルトをパスワード管理戦略の一環として必ず取り入れるべきです。”
Tweet This
ハッシュ化とは何か?
辞書ではハッシュ化とは、"何かを小片に切り刻んで"、それを"雑然としたもの"のように見せることを指すとあります。この定義は、コンピューターで意味するハッシュ化によくあてはまります。
暗号化におけるハッシュ関数は、どんなサイズのデータでも固定サイズのビット列にマップしてしまう数学アルゴリズムです。この関数入力をメッセージまたは単に入力と呼ぶことができます。固定サイズ文字列の関数出力はハッシュまたはメッセージダイジェストとして知られています。OWASPで述べられているように、暗号化に使用されるハッシュ関数の主な特徴は次のとおりです。
- ハッシュを計算するのは簡単で実用的だが、ハッシュ値だけが分かっている場合に元の入力値を復元するのは困難または不可能である。"
- 特定の出力値に一致する初期入力値を作成するのは難しい。
したがって、暗号化とは対照的に、ハッシュ化は一方通行のメカニズムなのです。ハッシュ化されたデータを"ハッシュ化されていない"元のデータに戻すことは、実質的に不可能です。
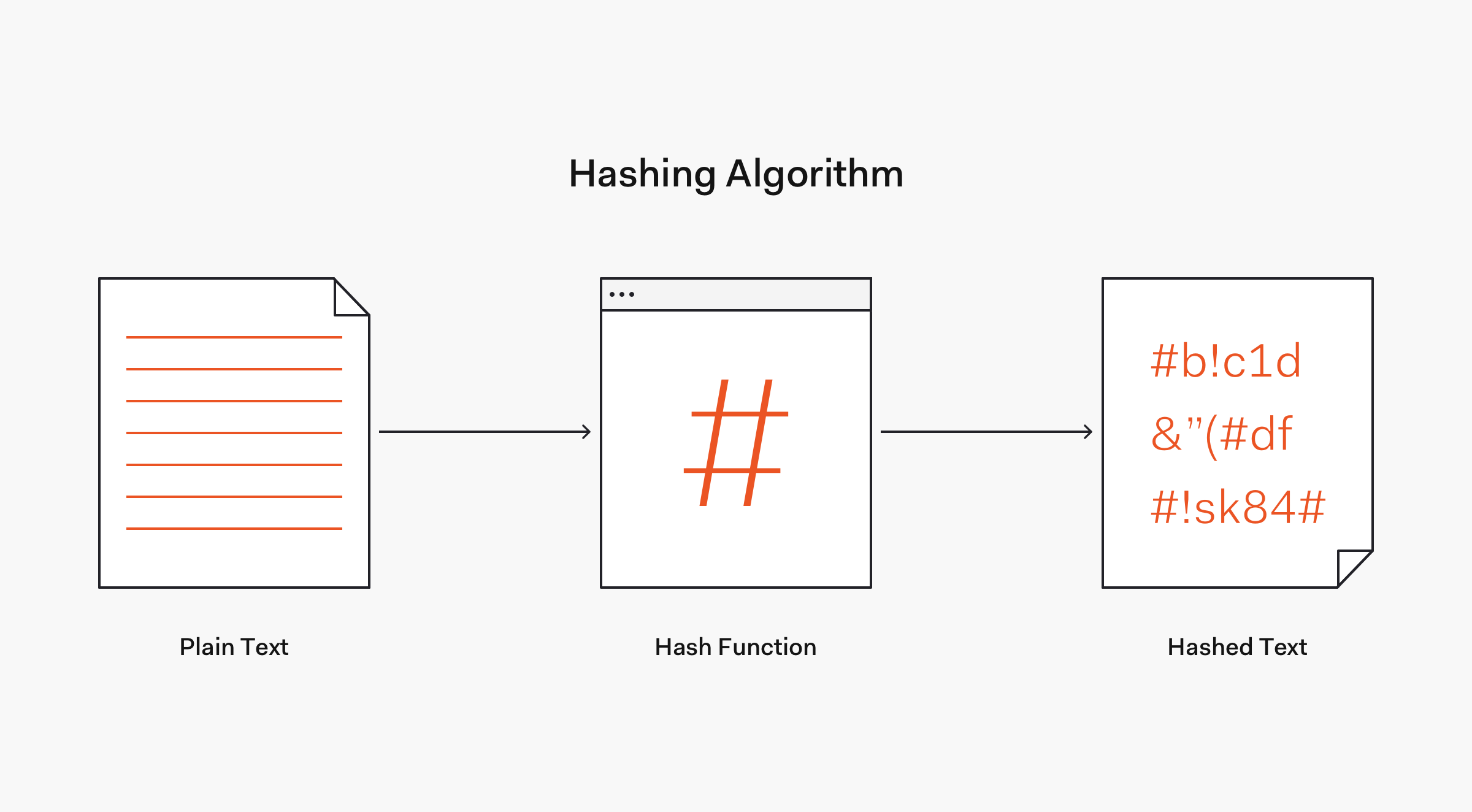
一般的に使用されるハッシュ化アルゴリズムには、MD5などのメッセージダイジェスト(MDx)のほかに、SHA-1や広く使用されているSHA-256アルゴリズムを含むSHA-2ファミリなどのセキュアハッシュアルゴリズム(SHA)などがあります。これらのアルゴリズムの長所、計算能力の急速な発展やセキュリティの脆弱性によって一部のアルゴリズムが使用されなくなった理由については、あとで説明します。
ビットコインでは、整合性とブロックチェーンでSHA-256アルゴリズムを基盤の暗号学的ハッシュ関数として使用しています。SHA-256とPythonを使用したハッシュ化の例を見てみましょう。
実際に操作をしたい場合は、オンラインのPython repl.it IDEを使用するとPythonスクリプトを簡単に実行することができます。
Python repl.it IDEは、Pythonコードを入力するコードエディタ、スクリプトを保存や実行するボタン、スクリプト出力を可視化するコンソールを提供してくれます。
コードエディタで、次のコマンドを入力してhashlibモジュールからSHA-256ハッシュアルゴリズムのコンストラクタメソッドをインポートします。
from hashlib import sha256
下の行で、sha256クラスのインスタンスを作成します。
h = sha256()
次に、update()メソッドを使用してハッシュオブジェクトを更新します。
h.update(b'python1990K00L')
その後、hexdigest()を使用して、update()メソッドに渡す文字列のダイジェストを取得します。
hash = h.hexdigest()
ダイジェストはハッシュ関数の出力です。
最後にhash変数をプリントして、コンソールでハッシュ値を確認します。
print(hash)
完全なスクリプトは次のようになります。
from hashlib import sha256 h = sha256() h.update(b'python1990K00L') hash = h.hexdigest() print(hash)
このスクリプトを実行するには、画面上部の「実行」ボタンをクリックします。コンソールで次の出力を確認してください。
d1e8a70b5ccab1dc2f56bbf7e99f064a660c08e361a35751b9c483c88943d082
要点をまとめると、ハッシュ関数に入力として文字列を提供し、ハッシュ化された入力を表す出力として別の文字列を受け取ることになります。
入力:
python1990K00L
ハッシュ(SHA-256):
d1e8a70b5ccab1dc2f56bbf7e99f064a660c08e361a35751b9c483c88943d082
試しに文字列pythonをハッシュ化してみましょう。次のハッシュが得られましたか?
11a4a60b518bf24989d481468076e5d5982884626aed9faeb35b8576fcd223e1
“ブロックチェーンや、ビットコインなどの暗号通貨を理解することは、暗号学的ハッシュ関数がどのように機能するかを理解することよりも簡単です。”
これをツイートする
ここではSHA-256を使用して、ランダムサイズの入力を固定サイズのビット文字列に変換しました。python1990K00Lとpythonは長さに違いがあるにもかかわらず、各入力は同じ長さのハッシュを生成している点に注目してください。これはなぜでしょう?
hexdigest()を使用して、16進数表現のハッシュ値を生成したからです。どんな入力であっても、各メッセージダイジェストの出力は16進数形式で64桁になります。2桁の対がそれぞれ1バイトを表します。したがって、ダイジェストは32バイトです。1バイトに8ビットの情報が保持されるので、ハッシュ文字列は合計256バイトの情報を表します。このアルゴリズムがSHA-256と呼ばれるのがこれが理由です。すべての入力から同じサイズの出力が得られます。
一部のハッシュ関数は広く使われていても、その特性と要件ではセキュリティが提供されないものもあります。例えば、巡回冗長検査(CRC)はエラーを検知するためにネットワークアプリケーションで使用されるハッシュ関数ですが、原像計算困難性がないため、デジタル署名などのセキュリティアプリケーションでの使用には不向きです。
この記事では、セキュリティアプリケーションでの使用に適したハッシュ関数に必要とされる特性について見ていきます。はじめに、たとえ暗号学的ハッシュ関数への入力がどのように計算されてハッシュ化されるかについて詳しく分かったとしても、ハッシュを入力に戻すことは現実的ではないことを知っておく必要があります。これはなぜでしょう?
暗号学的ハッシュ関数は実質的に元に戻せない
ハッシュ関数は、モジュロ演算など元に戻すのが極めて難しく煩わしい数学演算を使用して、一方向関数として機能します。
モジュロ演算は除算の余りを求める演算です。例えば、正数の除算で5 / 3の余りは2なので、5 mod 3は2です。同じ入力からは常に同じ出力が生成されるとするならば、数学的に5 / 3の結果は常に2となり、この演算は確定的です。しかし、モジュロ演算の重要な特性は、その結果に基づいて、元となったオペランドを探し出せないことです。そういった意味で、ハッシュ関数は元に戻せません。
モジュロ演算の結果が2であるのは、xをyで割った余りが2であることだけがわかるのであって、xとyが何であるかはわかりません。x mod yが2となる際のxとyに置き換えられる変数は無数にあります。
7 mod 5 = 2
9 mod 7 = 2
2 mod 3 = 2
10 mod 8 = 2
...
暗号学的ハッシュ関数を使用するときに、ハッシュに基づいて原像を探すことができては意味がありません。原像は、ハッシュ関数への入力として使用した場合に特定のハッシュを生成する値のことであり、つまりはプレーンテキスト値です。したがって、暗号学的ハッシュ関数は原像攻撃に耐えうるよう設計されており、原像攻撃困難性でなくてはなりません。つまり、ハッカーがハッシュを知っていても、その特定の出力にハッシュ化される入力を探し出すことは、計算論的に不可能なのです。この特性こそがビットコインやブロックチェーンの基盤の一部をハッシュ化する理由です。
ハッシュ関数の仕組みについて知りたい方は、ウィキペディアの記事にセキュアハッシュアルゴリズム2(SHA-2)の仕組みが詳しく書かれていますのでご覧ください。
小さな変更が大きく影響する
セキュアハッシュ関数のもう1つの長所に、出力を予測するのは簡単ではないことが挙げられます。例えば、dontpwnme4とdontpwnme5では、文字列の最後の文字だけが異なり、2つの文字列はアルファベット順で隣同士になるにもかかわらず、そのハッシュはかなり違う結果になります。
入力:
dontpwnme4
ハッシュ(SHA-256):
4420d1918bbcf7686defdf9560bb5087d20076de5f77b7cb4c3b40bf46ec428b
入力:
dontpwnme5
ハッシュ(SHA-256):
3fc79ff6a81da0b5fc62499d6b6db7dbf1268328052d2da32badef7f82331dd6
念のため、これらの値の計算に用いられるPythonスクリプトを次に示します。
from hashlib import sha256 h = sha256() h.update(b'<STRING>') hash = h.hexdigest() print(hash)
<STRING>をハッシュしたい文字列に置き換えて、repl.itで実行してみてください。
この特性は雪崩効果として知られていて、入力がわずかに変わると出力が大幅に変わるという望ましい効果が得られます。
その結果、前の2つのハッシュに基づいてdontpwnme6のハッシュが何であるかを判断する方法はありません。出力に連続性がないためです。
よりセキュアなパスワード格納のために暗号学的ハッシュを使用する
復元不可能というハッシュの数学的特性によって、パスワードを保存状態でも移動中でも隠すことができる驚異的なメカニズムが作り出されます。ハッシュ関数がパスワードの格納に適している重要なもう1つの特性として、確定的な関数であることが挙げられます。
確定的な関数とは、同じ入力から常に同じ出力が生成される関数です。これは、特定のパスワードが常に同じハッシュを生成するという保証が必要とされる認証処理には欠かせません。でなければ、この技術を使用してユーザーの資格情報を一貫した方法で確認することはできなくなります。
パスワード格納のワークフローにハッシュ化を組み入れるには、ユーザーが作成されるときにクリアテキストでパスワードを格納するのではなく、パスワードをハッシュ化して、ユーザー名とハッシュ化されたパスワードのペアをデータベーステーブルに格納します。ユーザーがログインするときは、送信されたパスワードをハッシュ化して、入力されたユーザー名に関連付けられているハッシュと比較します。ハッシュ化されたパスワードと格納されていたハッシュが一致すると、ログインが有効になります。この過程では決してクリアテキストのパスワードを格納しないように注意することが重要です。ハッシュ化をしたら下のパスワードは忘れましょう。
パスワードの送信は暗号化が必要ですが、パスワードハッシュは格納時に暗号化する必要がありません。正しく実装されているパスワードハッシュは暗号学的に安全なのです。この実装には、ハッシュ関数の限界を克服するためソルトが使用されます。
一意性はソルトの重要な特性であり、これには長さが役立ちます。
ハッシュ関数の限界
ハッシュ化はかなり堅牢なように見えます。しかし、ハッカーがサーバーに侵入してパスワードハッシュを盗んだ場合、ハッシュ関数のアーキテクチャのおかげで、ハッカーにはプレーンテキストに置き換えられないランダムなデータしか見えません。ハッカーはハッシュ関数に入力を提供して、あとで認証に使用できるハッシュを作成しなければなりません。これは、サーバーで警告を発することなく、オフラインで行うことができます。
ハッカーはその後、最新のフィッシングやスプーフィング技法を用いてクリアテキストのパスワードをユーザーから盗むか、一致するハッシュが見つかるまでハッシュ関数に無作為にパスワードを入力するブルートフォースアタックを試すかのいずれかを行います。
ハッシュ関数の実行はかなり長くなるよう設定できることから、ブルートフォースアタックは効率的でありません。このハッシュ化の減速バンプについては後で詳しく説明します。ハッカーに残されたオプションは?
ハッシュ関数は確定的(入力が同じであれば常に同じハッシュになる)なので、複数のユーザーが同じパスワードを使用すると、そのハッシュは同一になります。多くの人が同じハッシュにマップされると、そのハッシュが一般によく使用されるパスワードを表すサインとなってしまい、これによってハッカーはブルートフォースで侵入するために使用するパスワードの数を大幅に減らすことができます。
さらに、ハッカーはレインボーテーブルアタックを使用して、あらかじめ計算済みの膨大な量のハッシュチェインのデータベースを使用して、盗んだパスワードハッシュの入力値を探すことができます。ハッシュチェインは、初期のハッシュ値と、その値に何度も繰り返し計算を適用して得られた最終値を格納したレインボーテーブルの1行を指します。レインボーテーブルアタックではこうした多くの処理を再計算しなくてはならないので、値を格納する時点で無作為のデータを各入力に加えることでハッシュ化を強化すると、レインボーテーブルアタックを緩和できます。この方法はハッシュにソルトを付加する方法として知られていて、ソルト付きパスワードハッシュを生成します。
ソルトが付加されているので、ハッシュはパスワードの値だけを基にしていないことになります。入力はパスワードとソルトで構成されます。レインボーテーブルはソルトが付いていないハッシュのセット用に作成されています。各原像に一意で予測不可能な値が含まれている場合、レインボーテーブルは役に立ちません。ハッカーはソルトを手に入れると、レインボーテーブルを再計算しなくてはならず、それには希望的観測ですがとても長い時間がかかるので、さらに攻撃ベクトルを緩和することができます。
「ハッシュを"解読する"のにかかる労力の方がその結果得られる価値よりもずっと大きいようにすることが秘訣なのです。それは"ハッキングが不可能"ということではなく、そんな努力に値しないほど難しくしてしまうということです」-Tony Hunt氏談
高速化は不要
Jeff Atwood氏によると、「セキュリティに使用するハッシュは低速にする必要がある」そうです。パスワードのハッシュ化に使用される暗号学的ハッシュ関数の計算は、特に現代のハードウェア力が急速に発展していることもあり、高速で計算するアルゴリズムによってブルートフォースアタックの実効性が高まってしまうため、低速にする必要があります。これを成し遂げるため、内部反復を多く使用したり、計算メモリを集約したりしてハッシュの計算を低速にしました。
ハッシュ計算の速度は悪意のあるユーザーとそうでないユーザーの両方に影響を与えるため、低速の暗号学的ハッシュ関数は攻撃のプロセスを阻むことはあってもプロセスを停止させることはありません。ハッシュ関数においては速度と有用性のバランスを保つことが重要です。善意のユーザーが有効なログインを1回試みる位では、パフォーマンスに顕著な影響は現れません。
衝突攻撃によりハッシュ関数が使用廃止に
ハッシュ関数はどんなサイズの入力も受け入れますが、生成するハッシュは固定サイズの文字列なので、入力可能なセットは無限にあるのに対して出力可能なセットには限界があります。そのため、複数の入力を同一のハッシュにマップするという可能性が存在します。よって、ハッシュを元に戻すことができたとしても、結果が選択した入力になると確信することはできません。これは衝突として知られ、望ましい影響ではありません。
暗号学的衝突は、2つの一意の入力が同一のハッシュを生成するときに生じます。したがって、衝突攻撃は同一のハッシュを生成する2つの原像を探そうとします。ハッカーはこの衝突を利用して、不正なあるいは悪意あるデータで有効なハッシュを偽造することにより、ハッシュ化された値に依存するシステムを欺くことができます。そのため、暗号学的ハッシュ関数は、ハッカーがこうした一意の値を簡単には見つけられないようにすることで、衝突攻撃に対する耐性も備える必要があります。

Source: 初めてのSHA1衝突例を発表する(Google)
“入力の長さは無限大ですが、ハッシュの長さは固定されているため、衝突は起こり得ます。衝突のリスクは統計的に非常に低いとされているにもかかわらず、よく使われているハッシュ関数で衝突が見つかっています。”
Tweet This
シンプルなハッシュアルゴリズムであれば、簡単なGoogle検索でハッシュを元のクリアテキストの入力に変換するツールが見つけられます。MD5アルゴリズムは今日では有害と見なされており、Googleは2017年に初のSHA1衝突を発表しました。暗号学的衝突が発生したことを受けて、どちらのハッシュアルゴリズムも安全ではないと考えられ、Googleでは非推奨になっています。
GoogleはSHA-256やSHA-3などのより堅牢なハッシュアルゴリズムの使用を推奨しています。その他に実際によく使用されているのは、この暗号学的アルゴリズムのリストに記載されているbcryptやscryptなどです。しかし、先ほど学んだように、ハッシュ化だけでは十分でありません。ソルトと組み合わせるべきです。詳細については、ハッシュにソルトを付加してパスワードをより賢く格納する方法をご覧ください。
まとめ
では本稿で学んだことをまとめましょう。
- ハッシュの主な目的は、データの整合性を検査するためデータの指紋を作ることである。
- ハッシュ関数は任意の入力を受け入れ、これを固定長の出力に変換する。
- 暗号学的ハッシュ関数にふさわしいのは、原像計算困難性と衝突攻撃耐性を備えたハッシュ関数である。
- レインボーテーブルがあるため、大規模な悪用からパスワードを守るにはハッシュ化だけでは不十分である。こうした攻撃ベクトルを緩和するには、ハッシュを暗号学的ソルトと組み合わせて使う必要がある。
- パスワードのハッシュ化は、ログイン中に送信されたパスワードの整合性を格納されたハッシュと比較して確認するために使用されるので、実際のパスワードを格納する必要はない。
- 暗号学的アルゴリズムのすべてが現代産業に適しているわけではない。本稿の執筆時、MD5とSHA-1については衝突攻撃の被害を受けやすいとGoogleが報告している。SHA-2ファミリーがより優れた選択肢とされている。
Auth0でパスワード管理を簡素化する
Auth0を利用すればハッシュやソルト、パスワード管理のオーバーヘッドを最小限に抑えられます。非常に複雑なアイデンティティユースケースでも、簡単に統合し拡張できるプラットフォームで解決し、毎月数十億件にのぼるログインを安全に保護しています。
Auth0は重要なアイデンティティ管理データが悪の手に渡るのを防ぐお手伝いをします。パスワードをクリアテキストで格納することは決してありません。必ずbcyptを使用してハッシュ化し、ソルトを付与します。さらにデータは、少なくとも128ビットAES暗号化を行うTLSを使用して、格納中も送信中も暗号化されます。当社の製品は最新のセキュリティ技術を使って構築されています。貴社のビジネスとユーザーを保護するのにぜひ役立ててください。
今すぐ無料のAuth0アカウントに登録して、インターネットの安全を守りましょう。
About the author

Dan Arias
Software Engineer (Auth0 Alumni)