
We all know that machine learning is about handling data, but it also can be seen as:
The art of finding order in data by browsing its inner information.
Some background on predictive models
There are several types of predictive models. These models usually have several input columns and one target or outcome column, which is the variable to be predicted.

So basically, a model performs mapping between inputs and an output, finding-mysteriously, sometimes-the relationships between the input variables in order to predict any other variable.
As you may notice, it has some commonalities with a human being who reads the environment => processes the information => and performs a certain action.
So what is this post about?
It's about becoming familiar with one of the most-used predictive models: Random Forest (official algorithm site), implemented in R, one of the most-used models due to its simplicity in tuning and robustness across many different types of data.
If you've never done a predictive model before and you want to, this may be a good starting point ;)
Don't get lost in the forest!

The basic idea behind it is to build hundreds or even thousands of simple and less-robust models (aka decision trees) in order to have a less-biased model.
But how?
Every 'tiny' branch of these decision tree models will see just part of the whole data to produce their humble predictions. So the final decision produced by the random forest model is the result of voting by all the decision trees. Just like democracy.
And what is a decision tree?
You're already familiar with decision tree outputs: they produce IF-THEN rules, such as, If the user has more than five visits, he or she will probably use the app.
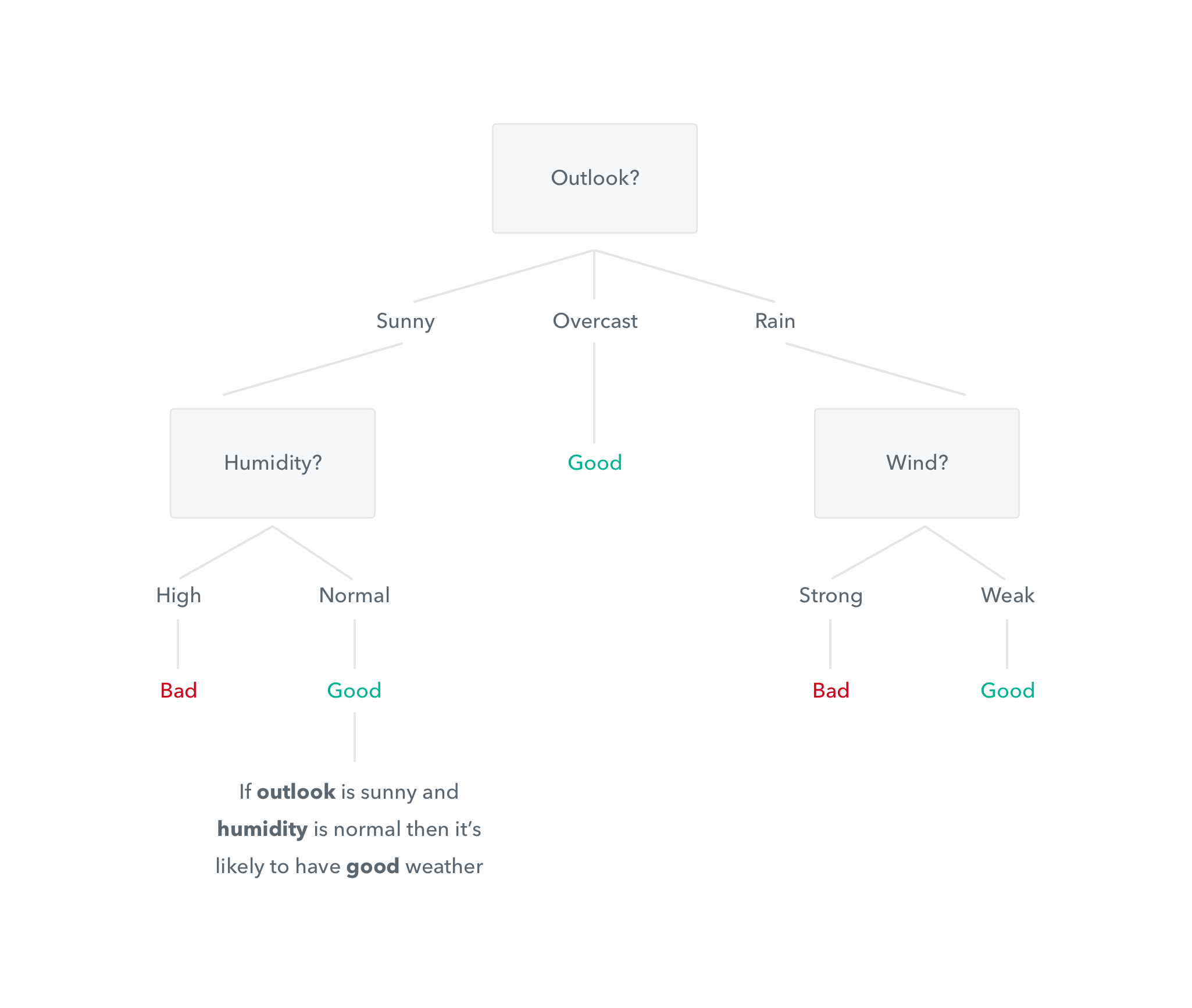
Putting all together...
If a random forest has three trees (but normally 500-plus) and a new customer arrives, then the prediction whether said customer will buy a certain product will be 'yes' if 'two trees' predict 'yes'.
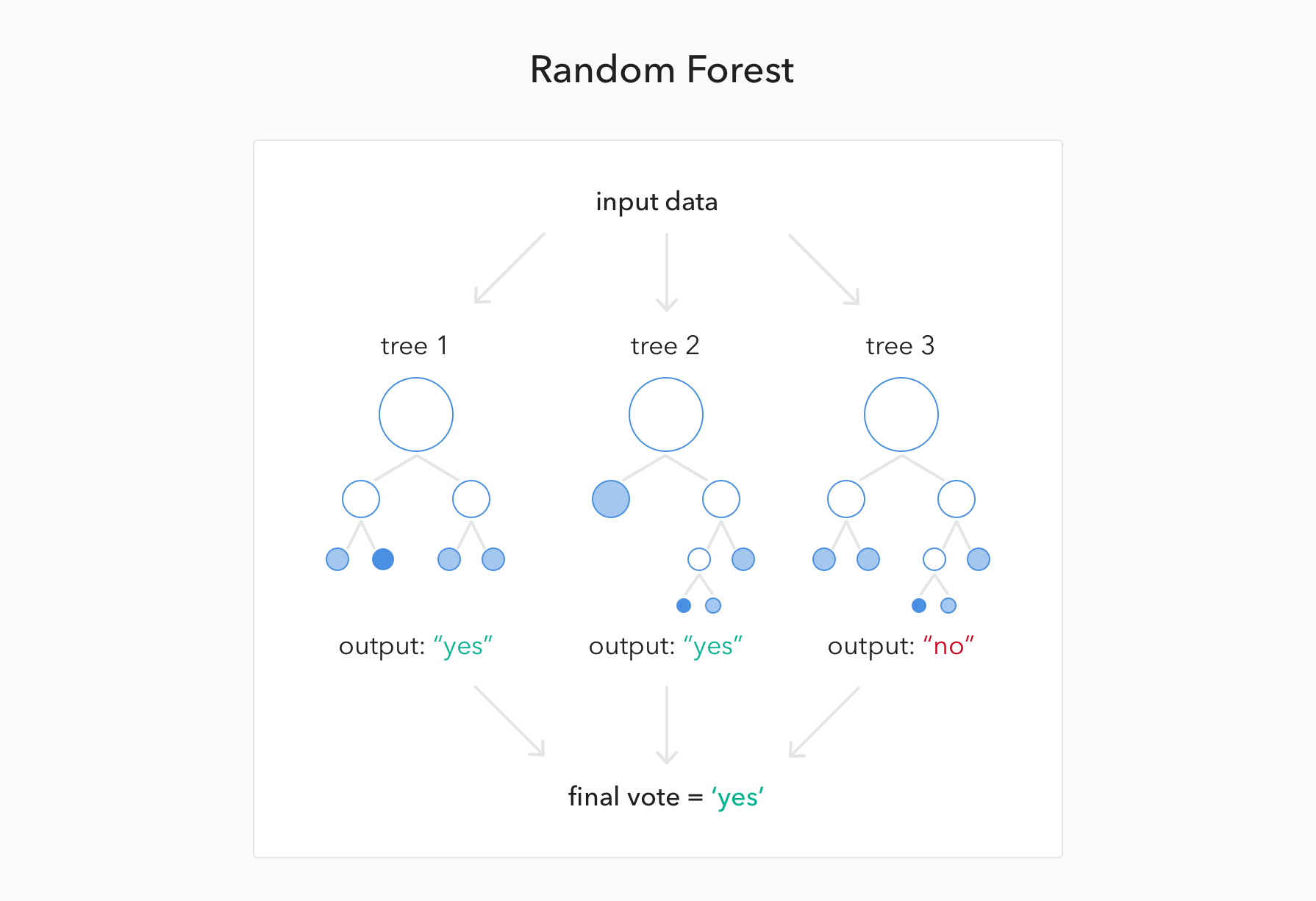
Having hundreds of opinions -decision trees- tends to produce a more accurate result on average -random forest-.
But don't panic, all of the above is encapsulated in the data scientist.
With this model, you will not be able to easily know how the model comes to assign a high or low probability to each input case. It acts more like a black box, similar to what is used for deep learning with neural networks, where every neuron contributes to the whole.
Next post...
Will contain an example -based on real data- of how random forest orders the customers according to their likelihood of matching certain business condition. Also, it will map around 20 variables into only two, therefore, it can be seen by the analyst ;)
What language is convenient for learning machine learning?
Auth0 mainly uses R software to create predictive models as well as other data processes; for example:
- Finding relationships between app features: which impacts the engineering area.
- Finding anomalies or abnormal behavior: which leads to the development of anomaly detection features.
- Improving web browsing docs: based on markov chains (likelihood of visiting
Page B being on Page C) - Reducing times for answering support tickets using deep learning (not with R but with Keras)
If you want to develop your own data science projects, you could start with R. It has a enormous community from which you can learn (and teach). It's not always just a matter of complex algorithms, but also about having support when things don't go as expected. And this occurs often when you're doing new things.
Finally, some numbers about community support
Despite the fact that R (and Python with pandas and numpy) has lots of packages, libraries, free books, and free courses, check these metrics: There are more than 160,000 questions in stackoverflow.com, and another ~15,000 in stats.stackexchange.com are tagged with R.
About the author

Pablo Casas
Sr. Data Scientist / AI (Auth0 Alumni)