


If you’re working to create your authorization and permissions systems, chances are you have already heard about roles, attributes, policies and relationships. As your needs grew, you may have encountered systems that let you write more explicit rules, which fall under the broad umbrella of policy-based access control (PBAC).
For modern, fine-grained authorization, two main architectural patterns have emerged from PBAC:
- Relationship-based access control (ReBAC): A model where the core focus is on the relationships between entities.
- Attribute-based access control (ABAC): A model where the core focus is on the attributes of entities.
The key is that these models aren’t mutually exclusive, but that they have different starting points. Your choice between them will define how you build and reason about your authorization system. In this blog post you’ll compare these models using open-source examples: OpenFGA for ReBAC and Cedar for a policy-based ABAC. We'll explore their different philosophies, see how they handle a real-world scenario, and help you choose the right pattern for your application.
Are PBAC and ABAC the same?
Before we dive deeper, let's clarify the terms policy-based access control (PBAC) and attribute-based access control (ABAC), as they are often used interchangeably.
Think of PBAC as the broad architectural paradigm. It describes any system where authorization logic is externalized from the application code and handled by an engine that evaluates a set of policies. The core idea is to stop hard-coding if statements for permissions inside your application. Both ReBAC and ABAC fall under this large PBAC umbrella because both use a "policy" (be it a relationship model or a set of rules) to make decisions.
ABAC, on the other hand, is a specific implementation of the PBAC paradigm. Its defining characteristic is that its policies are composed of rules that evaluate attributes.
Relationship-based access control (ReBAC)
ReBAC is a way to model authorization where permissions are granted based on the relationships between entities. Instead of asking, "What role does this user have?" ReBAC asks, "How is this user related to this resource?".
One well known implementation of ReBAC is Google’s Zanzibar. The main idea is to store your authorization data as a list of facts, called relationship tuples, like user:carla is the owner of document:q3_budget. These facts are represented in a graph form, so the system can answer complex questions like "Can Carla see this file?".
Now, here's where the nuance comes in. You can argue that ReBAC is also a form of ABAC. In ReBAC, depending on how you define relations, you can also incorporate attributes to define more traditional ABAC-style policies. For example, you could write a policy that says a user can_view a document only if they are a member of a certain department and model the departments as both attributes and relationships. So, while ReBAC is "relationship-first," it can handle attributes, making it a very powerful and flexible ABAC implementation.
Attribute-based access control (ABAC)
ABAC uses attributes of the entities of your system to grant access. As mentioned above, this authorization model can be considered policy-based, where your access logic is externalized into a set of explicit policies, or rules that define who can do what, that are evaluated at runtime.
The core principles of this pattern are:
- Decoupled logic: Authorization rules are written in a dedicated policy language and managed separately from the application code.
- Policies as code: Policies can be versioned, audited, and updated independently of application deployments.
- Rich context: Decisions are made by evaluating policies against attributes of the user, resource, and environment.
While ReBAC can support attributes, attribute-based access control (ABAC) systems start with attributes as the primary building block. In this model, authorization decisions are made by evaluating policies that consist of explicit rules about the attributes of the principal, action, and resource.
ReBAC vs. ABAC
The most important architectural difference is that ReBAC is a graph-based model, meaning, it determines access by looking at connections and paths between entities in a graph database, it also makes it easier to model scenarios where permissions are inherited from a hierarchy, while ABAC is an attribute-based model that evaluates explicit rules, meaning, it decides access based on different pieces of information, or "attributes," about the user, the thing they want to access, or even the time and place.
To compare the two we’ll use two open-source solutions, OpenFGA as a ReBAC implementation and Cedar as a PBAC implementation.
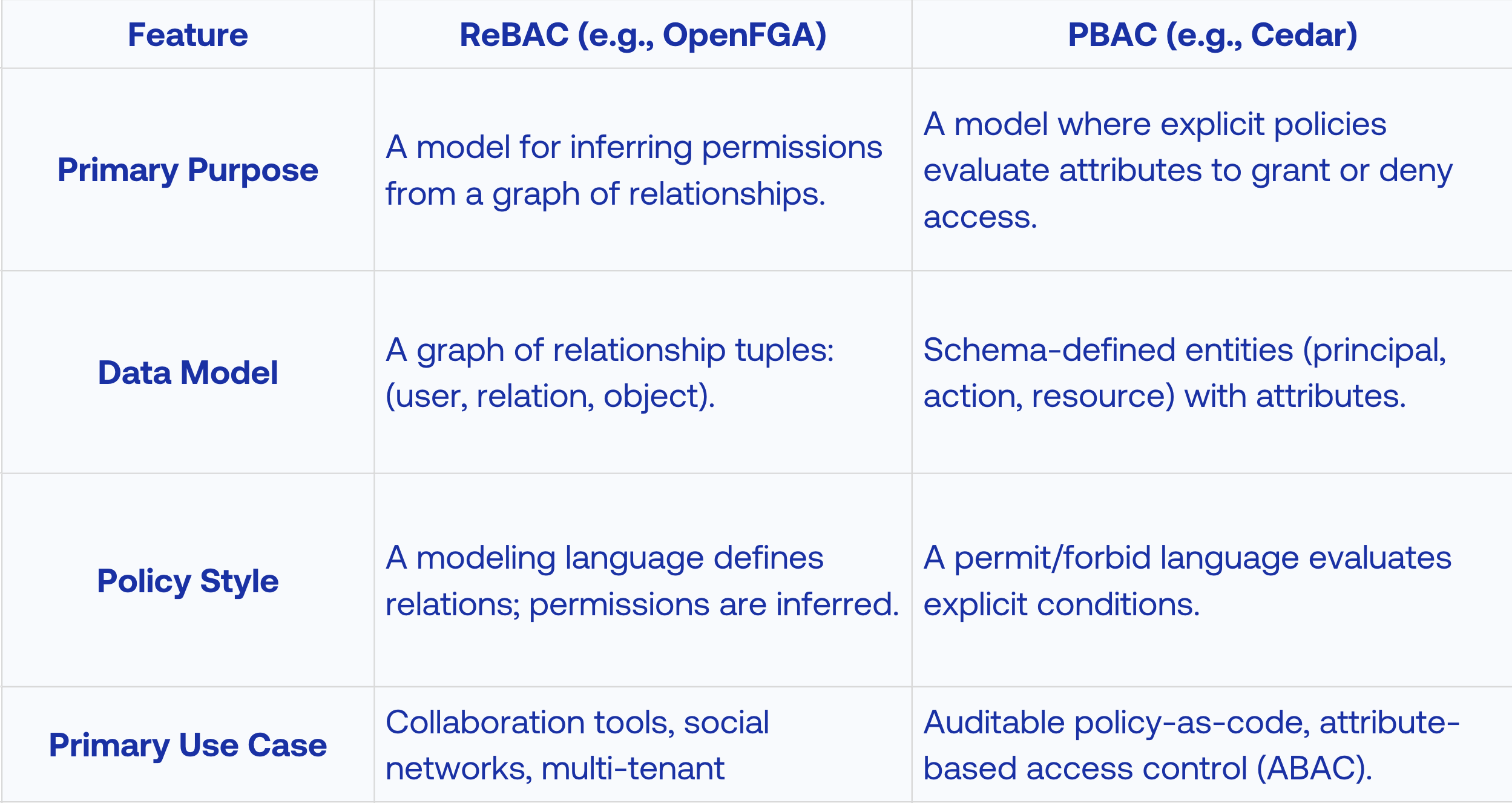
The comparison table provides a side-by-side analysis of the ReBAC (relationship-based access control) and PBAC (policy-based access control) models, using OpenFGA and Cedar as their respective examples across four key features.
For Primary Purpose, it contrasts ReBAC's function as a model for inferring permissions from relationship graphs with PBAC's role in evaluating explicit policies based on attributes. In terms of Data Model, it highlights ReBAC's use of a graph built from relationship tuples (user, relation, object) versus PBAC's use of schema-defined entities with various attributes. Regarding Policy Style, the table shows that ReBAC uses a modeling language to define relationships from which permissions are inferred, while PBAC uses a direct permit/forbid language to evaluate explicit conditions. Finally, for Primary Use Case, it identifies ReBAC as ideal for applications like collaboration tools and social networks, whereas PBAC is suited for systems requiring auditable policies and attribute-based access control.
A practical example: “Can this user view this document?”
Let's use a real-world policy to see how the development mindset and implementation differ.
- A user can view a document if they are the owner, or
- The user was granted direct permission as a viewer or
- The user has viewer permission on the parent folder, or
- The user is a member of a group that was granted permission to the document or its parent folder, or
- The user is an admin of the organization that owns the document.
You can find a full implementation in Go of the code shown in this blog post in this Github repo.
The OpenFGA approach
With OpenFGA, your first thought is: "What are the entities and how do they relate?" You model the entities, and then define the final permission as a composition of those relationships.
The resulting model would look like:
model schema 1.1 type user type organization relations define member: [user] type folder relations define organization: [organization] define owner: [user] define editor: [user] or owner define viewer: [user] or editor or member from organization define can_view: viewer define can_edit: editor define can_delete: owner define can_share: owner or editor type document relations define organization: [organization] define parent_folder: [folder] define owner: [user] define editor: [user] or owner or editor from parent_folder define viewer: [user] or editor or viewer from parent_folder or member from organization define can_view: viewer define can_edit: editor define can_delete: owner define can_share: owner or editor
This model has the following entities:
- user: individual users in the system
- organization: companies or groups
- folder: document containers with hierarchical permissions
- document: files with inherited and explicit permissions
And allows you to make decisions based on organization access through the member relation, check for ownership through the owner relation and define explicit permissions on documents such as editor and viewer as well as folder inheritance. Note that in a real world scenario, folder permissions will be inherited recursively from the parent folder, but we are not considering it as Cedar does not support it.
To verify if a user user:carla has view permission on document document:planning, assuming they are the owner, you need the following tuple:
{ user: 'user:carla', relation: 'owner', object: 'document:planning', }
And the run a check request to OpenFGA:
curl -X POST $FGA_API_URL/stores/$FGA_STORE_ID/check \ -H "content-type: application/json" \ -d '{"authorization_model_id": "$FGA_AUTHORIZATION_MODEL_ID", "tuple_key":{"user":"user:carla","relation":"can_view","object":"document:planning"}}' # Response: {"allowed":true}
After making the API call you’ll get a boolean indicating if the user is related to the object meaning they are allowed or not to perform that action on it. You can learn more about it in the OpenFGA docs.
The Cedar approach
With Cedar, your first thought is: "What are all the explicit conditions that grant access?" You think in terms of a checklist of rules. Each rule must be written as a standalone permit statement that evaluates the attributes of the entities involved.
Although, before you can even call the Cedar engine, your application code is responsible for fetching all the necessary attributes from your database.
For Cedar, you can define your policies as follows:
// Document Management Authorization Policies // Organization member can view organization documents permit( principal, action == DocumentManagement::Action::"ViewDocument", resource ) when { principal.organization == resource.organization }; // Organization member can view organization folders permit( principal, action == DocumentManagement::Action::"ViewFolder", resource ) when { principal.organization == resource.organization }; // Document owner can perform all actions on their documents permit( principal, action in [ DocumentManagement::Action::"ViewDocument", DocumentManagement::Action::"EditDocument", DocumentManagement::Action::"DeleteDocument", DocumentManagement::Action::"ShareDocument" ], resource ) when { principal == resource.owner }; // Document editor can edit and share documents they edit permit( principal, action in [ DocumentManagement::Action::"EditDocument", DocumentManagement::Action::"ShareDocument" ], resource ) when { principal in resource.editors }; // Document viewer can view documents permit( principal, action == DocumentManagement::Action::"ViewDocument", resource ) when { principal in resource.viewers }; // Folder owner can perform all actions on their folders permit( principal, action in [ DocumentManagement::Action::"ViewFolder", DocumentManagement::Action::"EditFolder", DocumentManagement::Action::"DeleteFolder", DocumentManagement::Action::"ShareFolder" ], resource ) when { principal == resource.owner }; // Folder editor can view, edit, and share folders (but not delete) permit( principal, action in [ DocumentManagement::Action::"ViewFolder", DocumentManagement::Action::"EditFolder", DocumentManagement::Action::"ShareFolder" ], resource ) when { principal in resource.editors }; // Folder editor can view, edit, and share documents in their folders permit( principal, action in [ DocumentManagement::Action::"ViewDocument", DocumentManagement::Action::"EditDocument", DocumentManagement::Action::"ShareDocument" ], resource ) when { principal in resource.parent_folder.editors }; // Folder owner can view, edit, and share documents in their folders permit( principal, action in [ DocumentManagement::Action::"ViewDocument", DocumentManagement::Action::"EditDocument", DocumentManagement::Action::"ShareDocument" ], resource ) when { principal == resource.parent_folder.owner }; // Folder viewers can view folders permit( principal, action == DocumentManagement::Action::"ViewFolder", resource ) when { principal in resource.viewers }; // Folder viewers can view documents in folders permit( principal, action == DocumentManagement::Action::"ViewDocument", resource ) when { principal in resource.parent_folder.viewers };
Now let’s say we want to find out if user carla can view the document document:planning assuming they are an owner of the document, first you need to fetch the data from your database. If we assume you’re using PostgreSQL and a database schema follows the same patterns as your entities (here’s the full schema for this example), you could end up with a query such as:
WITH user_org AS ( SELECT organization_id as user_org_id FROM organization_members WHERE user_id = $1 LIMIT 1 ), doc_info AS ( SELECT d.id as doc_id, d.organization_id as doc_org_id, d.folder_id, d.owner_id as doc_owner_id, f.organization_id as folder_org_id, f.owner_id as folder_owner_id FROM documents d LEFT JOIN folders f ON d.folder_id = f.id WHERE d.id = $2 ), doc_perms AS ( SELECT dp.document_id, dp.user_id, dp.permission_type, 'document' as resource_type FROM document_permissions dp WHERE dp.document_id = $2 ), folder_perms AS ( SELECT fp.folder_id as document_id, fp.user_id, fp.permission_type, 'folder' as resource_type FROM folder_permissions fp JOIN doc_info di ON fp.folder_id = di.folder_id WHERE di.folder_id IS NOT NULL ) SELECT uo.user_org_id, di.doc_id, di.doc_org_id, di.folder_id, di.doc_owner_id, di.folder_org_id, di.folder_owner_id, COALESCE(dp.user_id, '') as perm_user_id, COALESCE(dp.permission_type, '') as perm_type, COALESCE(dp.resource_type, '') as resource_type FROM user_org uo CROSS JOIN doc_info di LEFT JOIN ( SELECT * FROM doc_perms UNION ALL SELECT * FROM folder_perms ) dp ON true
Once you’ve collected the data, you need to convert it to an instance of a Cedar entity defined prior, you can take a look at the example code here.
Next, you’re going to build the request, passing the user, action and resource you’re trying to check:
request := cedar.Request{ Principal: userUID, Action: cedar.NewEntityUID(cedar.EntityType("DocumentManagement::Action"), cedar.String("ViewDocument")), Resource: docUID, Context: cedar.NewRecord(cedar.RecordMap{}), }
And finally make the authorization check using the Authorize method and passing the policies, entities and request you created above:
decision, diagnostic := cedar.Authorize(policySet, entities, request) if len(diagnostic.Errors) > 0 { return false, fmt.Errorf("authorization errors: %v", diagnostic.Errors) } return decision == cedar.Allow, nil
Note the policySet can be loaded from a file, let’s say policies.cedar using policySet, err := cedar.NewPolicySetFromBytes("policies.cedar", policies), see the full example here.
Based on the examples, there are some considerations to take into account when using a policy engine like Cedar:
- Cedar does not require any specific infrastructure
- Create your Cedar entities and policies
- Build and maintain the SQL queries
- Call the Cedar engine to know if a user can perform an action on a resource.
Understanding tradeoffs between OpenFGA and Cedar
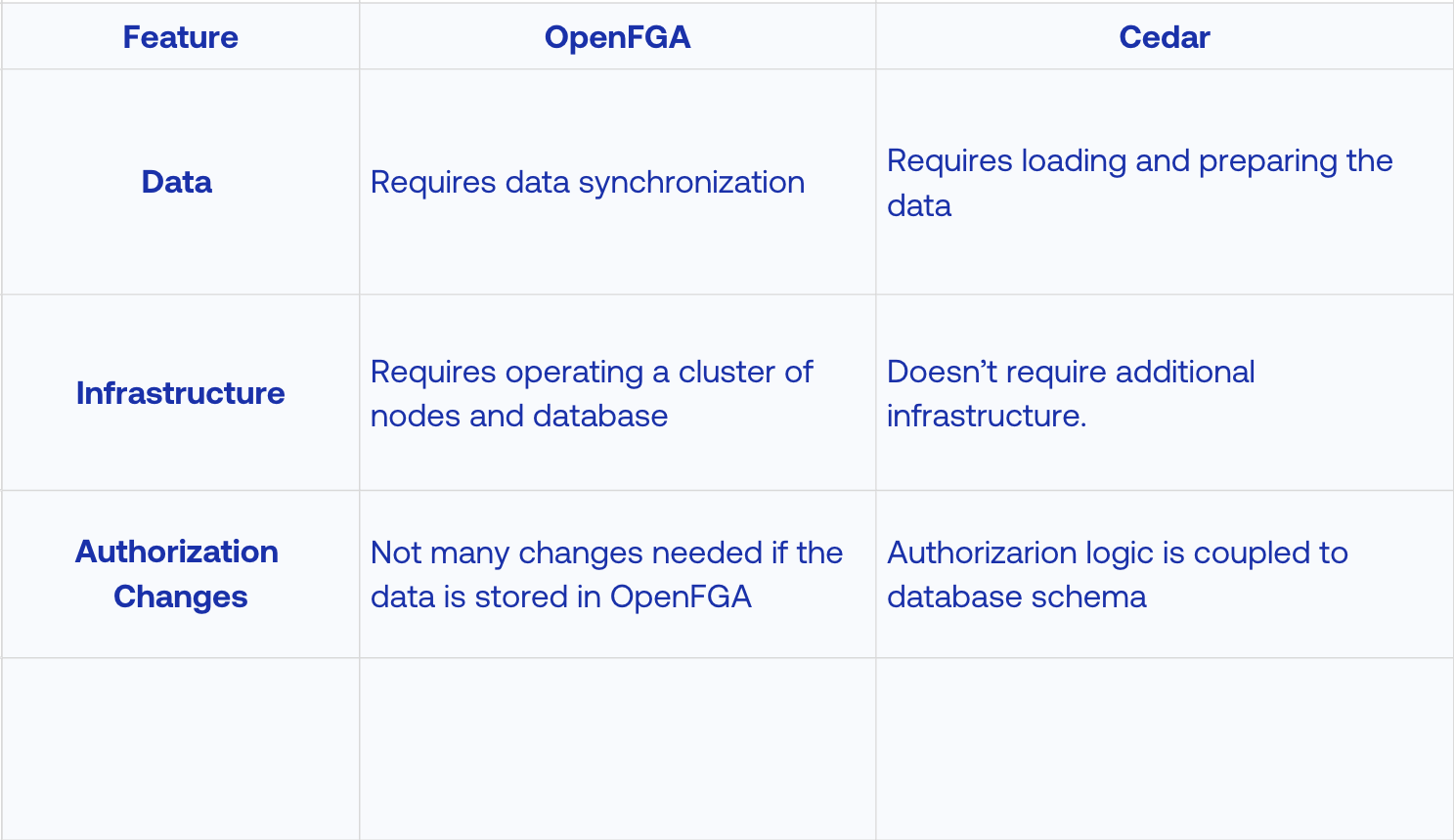
OpenFGA requires a network call, but the database queries are optimized for the specific query patterns, and OpenFGA can cache parts of the graph to resolve queries faster.
Cedar does not require a network call to evaluate a policy, but it requires loading and preparing the data. The total latency will depend on how expensive it is to retrieve it and how optimized it is for the use case.
In terms of authorization checks, OpenFGA makes an API call and the server already has the necessary data to answer the query. Cedar on the other hand, you need to retrieve the data and transform it to Cedar Entities, which adds complexity making checks.
When the rules in the system change but data doesn’t both OpenFGA and Cedar allow to change this very straightforwardly. If the data required to make an authorization decision changes, the SQL statements to retrieve data for Cedar might change as well, meaning your access control code is coupled with your application. In OpenFGA, if the data is stored in the OpenFGA database no changes are needed, but if it’s not stored yet in the OpenFGA database, you’ll need to implement a way to synchronize it.
OpenFGA requires knowledge for operating a cluster of nodes and a database. It will become a crucial component of your application infrastructure that can't fail. As mentioned before, Cedar does not require additional infrastructure. However, the database load will be higher, as applications need to retrieve data from transactional databases to inform authorization decisions.
Conclusion
Both ReBAC and ABAC are powerful, modern authorization models, but they are optimized for solving different kinds of problems.
The main difference between the two patterns, comes down to defining where you’ll have your authorization data. If you can have your data in a centralized database then ReBAC with OpenFGA could be the way to go, otherwise ABAC with a tool like Cedar could be a better approach.
If your application's complexity lies in the relationships between your data, how users collaborate, how resources are nested in hierarchies, and how group memberships grant indirect access, then the ReBAC model, implemented with a system like OpenFGA, is the right tool for the job. It is purpose-built to model and query these connections at scale with low latency.
If your primary challenge is enforcing attribute-based rules, and you want to manage a clear set of explicit permissions as code, then the ABAC model, implemented with a language like Cedar, is an excellent choice. It provides a safe and developer-friendly way for expressing a wide variety of access control policies.
By understanding the fundamental architectural differences between these two patterns, you can make an informed decision and build a more robust and scalable authorization solution for the future.
To experiment with ReBAC, you can use OpenFGA or try a managed service like Auth0 Fine-Grained Authorization (FGA), which provides a scalable implementation for developers.