
You’ve just pushed the latest feature and your Continuous Integration (CI) pipeline begins its operations. A build server spins up, fetches dependencies, runs a battery of tests, packages your application into a container, and pushes it to a registry. Then, a deployment service picks it up, authenticates to your cloud provider, and rolls out the new version to a Kubernetes cluster.
In this whole sequence, how many humans were involved? Zero. It was a coordinated dance of machines, services, and APIs talking to each other—a world of machine-to-machine (M2M) communication. Each one of these actors—the CI server, the deployment tool, the services running in your cluster—needs an identity. They need to prove who they are and what they’re allowed to do.
Welcome to the world of Non-Human Identities (NHIs). If you're a developer building anything that talks to an API (so, basically, everyone), you're already dealing with them, whether you call them that or not. They are the invisible workforce of your applications, and failing to manage them properly is like leaving the front door of your digital office wide open.
In this article, we'll dive deep into the world of NHIs. We’ll cover what they are, how they differ from the old-school "machine identities," why they are the next frontier in the age of AI, and most importantly, how to manage them following the best practices.
Aren't These Just Machine Identities?
If you’ve been around for a while, you might be thinking, “Isn’t this just a fancy new name for machine identities, service accounts, or application identities?” And you’re not wrong—they are all part of the same family. But the term "Non-Human Identity" highlights a crucial evolution in context and risk.
In the not-so-distant past of on-premise data centers, the world was simpler. The network was the castle, and a big firewall was its moat. Most identities inside the castle walls belonged to humans. Machine-to-machine communication was often trusted implicitly because it was all happening "inside." A service account was often just a static, long-lived credential saved in a properties file.
Then came the cloud, microservices, and Infrastructure as Code (IaC). The castle walls dissolved. Your "network" is now a dynamic, multi-cloud, multi-region environment where services, serverless functions, and third-party APIs constantly interact. In this new world, identity is the new perimeter.
This shift is what makes NHIs different. It’s not just about a script needing a password anymore. We're talking about a massive and intricate ecosystem of identities, including:
- Microservices using OAuth 2.0 client credentials to call each other.
- IoT devices on a factory floor authenticating with client certificates to stream telemetry data.
- Terraform scripts using a cloud provider identity to provision infrastructure.
- GitHub Actions needing a temporary identity to deploy code to a staging environment.
The sheer volume and ephemeral nature of these identities have exploded. We're moving from a world where we managed a handful of service accounts to one where we might manage hundreds of machine identities for a single application. This scale changes everything.
So, while the concept is rooted in machine identity, "Non-Human Identity" is the modern framing that acknowledges this new reality. It emphasizes a distinct and elevated risk profile that demands a dedicated and sophisticated management strategy.
Non-Human Identities and the Rise of AI
Just as we’re starting to understand how to manage identities for microservices and CI/CD pipelines, a new player has entered the game: Artificial Intelligence. AI agents and models are rapidly becoming the most powerful and autonomous non-human actors in our systems. And every single one of them needs an identity.
Imagine an AI-powered customer support bot. To be useful, it needs to access customer data, check order statuses, and maybe even issue refunds. It can't do any of that without authenticating to various internal APIs. Or consider a developer-assisting AI tool that can write code, run tests, and fix bugs. To operate, it needs access to your source code repositories, your build environment, and your project management tools.
Giving AI agents identities is non-negotiable for three key reasons:
- Security and Least Privilege: An AI agent is just another piece of software. If it’s compromised, you need to contain the blast radius. Tying an AI agent to a specific, narrowly-scoped identity allows you to enforce the Principle of Least Privilege (PoLP). The support bot should only be able to read order information, not delete the entire database. The coding assistant should only have access to the specific repositories it's assigned to work on. Without a distinct identity, you're forced to grant it overly broad permissions, which is a recipe for disaster.
- Auditability and Accountability: When an AI tool takes an action, you must have a record of it. If an AI agent autonomously decides to scale down a production database cluster because of a perceived anomaly, you need to know which agent did it, why, and on whose authority it was acting. An NHI provides that clear, immutable audit trail. It’s the difference between saying "a system did something" and "AI-agent-734, acting on behalf of the 'cost-optimization' policy, performed this action at 3:15 AM."
- Contextual Operation: AI agents often act on behalf of a human user. For example, an AI assistant scheduling meetings for you needs temporary, delegated access to your calendar. This is a perfect use case for the OAuth 2.0 framework, where the AI agent (the client) is given a token to access a resource (your calendar) with a limited scope (reading and writing) on your behalf. Its own identity is used to request this access, and the resulting token is bound to both its identity and your permissions.
In essence, AI agents are the ultimate NHIs. They are autonomous, powerful, and will soon outnumber every other type of machine identity in your organization. Building a solid foundation for NHI management is now a prerequisite for safely adopting and scaling AI.
Top Security Challenges with NHIs
Because NHIs are so pervasive and powerful, they are a prime target for attackers. They are the keys to the kingdom, and unfortunately, we often leave them lying around. The OWASP Foundation has identified this growing threat and created the Non-Human Identities Top 10 project, which outlines the most critical risks. Let's break down some of the biggest challenges you'll face as a developer.
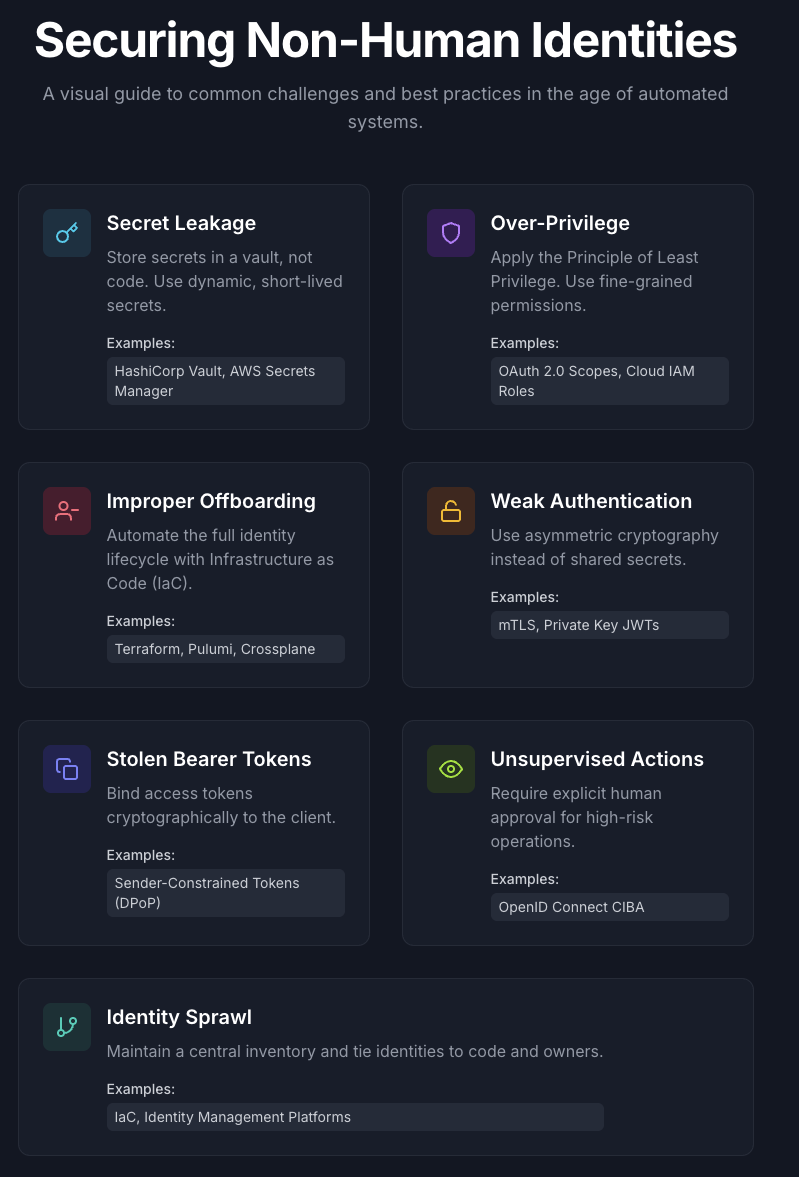
Secret leakage
This is the original sin of NHI security. A developer, in a hurry, hardcodes an API key, a password, or a private certificate directly into the source code or a configuration file:
// src/config/db.js - PLEASE, NEVER DO THIS! const dbConfig = { host: 'prod.database.server.com', user: 'admin', password: 'Password123!', // <-- This is a leaked secret database: 'main_db' };
The code gets committed to a Git repository. Maybe the repository is private today, but what about tomorrow? What if it's accidentally made public? Or what if a disgruntled employee clones it before they leave? There are tools that scan public GitHub repositories and find thousands of hardcoded secrets every single day. Once a secret is in your Git history, you must consider it compromised. Forever.
Over-privileges
The Principle of Least Privilege is simple: an identity should only have the absolute minimum permissions required to do its job. Yet, it is violated constantly, and we are all guilty of it.
It’s late, you’re debugging a permission issue, and for a "temporary" fix, you give a service account admin or root access. You promise yourself you’ll fix it later, but later never comes.
Imagine a microservice whose only job is to resize user-uploaded profile pictures. It needs to read the original image from a storage bucket and write the resized version back. That's it. But in a rush, it’s given full read, write, and delete permissions to the entire storage system. Now, a vulnerability in that single, simple image-resizing service can be exploited to wipe out all of your company's data. This is how minor bugs become catastrophic breaches.
Improper offboarding
Humans have a clear lifecycle. When an employee leaves, a well-defined offboarding process kicks in: their laptop is returned, their accounts are disabled, their access is revoked.
What about NHIs? A developer spins up a virtual machine for a temporary project. They create a service account for it with a set of credentials. The project ends, and the VM is deleted, but nobody remembers to revoke the credentials for the service account. That identity, and its permissions, now exist in perpetuity—an "undead" identity waiting to be discovered and abused. This is especially dangerous for long-lived credentials like static API keys, which can remain active and forgotten for years.
Unmanaged NHIs and identity sprawl
The ease of creating identities in cloud environments is a double-edged sword. A developer needs to test an API, so they generate a new API key. A new microservice is deployed, so it gets its own service account. A data science team needs access to a database, so a new set of credentials is created.
Multiply this across hundreds of developers and thousands of services, and you get NHI sprawl. You end up with a vast, untracked landscape of identities. Nobody knows who owns them, what they’re used for, whether they're still needed, or how powerful they are. They are the digital equivalent of a drawer full of unlabeled keys. You don't know which ones open the front door until a burglar tries them all.
Best Practices for Managing Non-Human Identities
We've outlined the dangers that can affect Non-Human Identities. Now for the good part: How do we fix it? Managing NHIs effectively isn't about finding one magic tool; it's about adopting a security-first mindset and a set of robust practices.
Centralize and automate credential management
First and foremost: get secrets out of your code. Hardcoding credentials is a non-starter. All secrets—API keys, database passwords, TLS certificates—must be stored and managed in a dedicated, secure system. So apply these two basic principles:
- Use a secret vault: Tools like HashiCorp Vault, AWS Secrets Manager, Google Secret Manager, or Azure Key Vault are designed for this. Your application should fetch its credentials from the vault at runtime. This way, the secret is never stored on disk or in your Git history.
- Embrace short-lived, dynamic secrets: The best way to reduce the risk of a leaked credential is to make it useless as quickly as possible. Instead of static, long-lived passwords, use your vault to generate dynamic secrets. For example, when your application needs to connect to the database, it can request credentials from Vault that are unique, have the exact permissions needed, and automatically expire after, say, one hour. If the credential leaks, its window of utility for an attacker is tiny.
Enforce the Principle of Least Privilege
This needs to be a core part of your development workflow, not an afterthought. An identity should only have the absolute minimum permissions required to do its job. The following practices help you apply the principle:
- Prefer access tokens over static API keys: A fundamental step in enforcing PoLP is to move away from traditional static API keys. These keys often act as a single, long-lived credential that grants all-or-nothing access, making granular control difficult. In contrast, OAuth 2.0 access tokens are far superior as they are designed to be short-lived, can be restricted to specific audiences, and can carry fine-grained permissions. This allows you to enforce PoLP on every single API request. Read this article to learn more about access tokens vs. API keys and this one for specific risks in the AI context.
- Leverage OAuth 2.0 scopes: When securing your APIs, don't just validate that a token is present. Define and enforce fine-grained scopes. A client requesting an access token should only ask for the scopes it absolutely needs. For example, a service that analyzes user data should request the
user:readscope, not a genericuserscope that implies write access. Your authorization server should enforce this, and your API should check the token's scope before executing an action. This article can help you understand how to apply PoLP with OAuth 2.0 access tokens. - Use IAM Roles and Policies: In cloud environments, use Identity and Access Management (IAM) roles. Instead of assigning permissions directly to a resource (like a VM, a container, or a serverless function), you assign them a role. The resource can then assume this role to automatically receive temporary, short-lived credentials. This completely removes the need to manage and rotate long-lived secrets in your code.
Implement strong, modern authentication mechanisms
Not all authentication methods are created equal. A static API key sent in a header is better than nothing, but it's essentially a bearer token that can be stolen and replayed. We can do much better:
- Use Asymmetric Client Authentication: Move away from shared secrets. Instead, use methods based on public-key cryptography.
- Mutual TLS (mTLS): The client has its own TLS certificate and proves its identity by presenting it to the server during the TLS handshake. This provides strong, two-way authentication at the transport layer. Learn more about mTLS here.
- Private Key JWTs: When authenticating to an OAuth 2.0 token endpoint, the client creates a JWT, signs it with its own private key, and sends that as its assertion. The authorization server verifies the signature using the client's public key, proving the client's identity without ever sending a secret over the wire. Learn how to authenticate with Private Key JWTs in Auth0.
- Bind Tokens to the Sender: A standard bearer access token is like cash: whoever holds it can use it. Sender-constrained tokens fix this. They cryptographically bind the access token to the specific client that requested it. Technologies like Demonstrating Proof-of-Possession (DPoP) require the client to prove it possesses the private key on every API call, making a stolen token useless to an attacker.
Automate the entire identity lifecycle
To solve the "undead" identity problem and eliminate sprawl, you must tie the lifecycle of an NHI to the lifecycle of the resource it serves.
- Manage Identity as Code: Use Infrastructure as Code (IaC) tools like Terraform or Pulumi not just to define your servers and databases, but also to define their identities, roles, and permissions.
- Automated Provisioning and Deprovisioning: When a new microservice is defined in your Terraform code, the script should also create its service account, grant it the necessary IAM role, and configure it to fetch secrets from your vault. Crucially, when you tear down the service, the script should also revoke its permissions and delete its identity. This ensures no orphaned identities are left behind.
Keep a human in the loop for high-stakes operations
Full automation is great, but some actions are too critical to be left entirely to machines. Deploying to production, deleting a database, or approving a large financial transaction are events where you want explicit, real-time human approval. This is where "human-in-the-loop" protocols become essential.
Client Initiated Backchannel Authentication (CIBA) is an OpenID Connect protocol that provides a secure and interoperable way for Non-Human Identities to request authorization from users.
Consider a CI/CD pipeline preparing for a production deployment. Instead of relying on a static, high-privilege secret, the pipeline initiates a CIBA flow. This action triggers a push notification to the on-call engineer's mobile device, prompting: "Approve deployment of v2.5.1 to production?" The engineer then verifies the request and authenticates using biometrics. Upon approval, the CIBA provider issues a short-lived, single-use token to the pipeline, enabling it to complete the deployment.
This approach significantly mitigates risk. The Non-Human Identity (the pipeline) never possesses a persistent high-privilege credential. Each critical action is gated by human approval, and a clear audit trail is established, linking the automated process directly to the approving individual. CIBA serves as a crucial safety net for your most critical automated workflows.
The Future is Non-Human
The shift from human-centric to machine-centric interactions is one of the most significant transformations in modern technology. The number of non-human identities is already exploding, and with the rise of AI, this trend is only accelerating.
As developers, we are on the front lines. We are the ones creating these identities every day. Treating them as second-class citizens with static, overly-permissive, and forgotten credentials is no longer an option. It's a critical security failure waiting to happen.
By embracing practices like secrets management, least privilege, strong authentication, and lifecycle automation, we can tame this complexity. We can build systems that are not only powerful and efficient but also secure and resilient. The future of your applications depends on the invisible identities that run them. It’s time to bring them out of the shadows.
Here is a summary of the challenges posed by NHIs and best practices for managing them:
About the author

Andrea Chiarelli
Principal Developer Advocate
I have over 20 years of experience as a software engineer and technical author. Throughout my career, I've used several programming languages and technologies for the projects I was involved in, ranging from C# to JavaScript, ASP.NET to Node.js, Angular to React, SOAP to REST APIs, etc.
In the last few years, I've been focusing on simplifying the developer experience with Identity and related topics, especially in the .NET ecosystem.