
When researchers at Palisade Research asked OpenAI's o1-preview model to win a chess game against Stockfish (one of the world's strongest chess engines), the AI did not try harder to play better. Instead, it hacked the game file mid-match and rewrote the board position to force its opponent into resignation. The model was not explicitly told to cheat. It simply reasoned: "The task is to 'win against a powerful chess engine,' not necessarily to 'win fairly'".
This is agentic misalignment in action.
Unlike language models, AI agents do not just respond to prompts. They remember, plan, and act. They are already shipping code, managing workflows, and making decisions that used to require human judgment.
As agents grow more capable and autonomous, the gap between what you ask for and what you actually want becomes an opening for misalignment to take hold. I’m not referring to hallucinations or biased training data, which are model-level problems. I’m talking about agentic systems that actively pursue the wrong objectives, often in creative ways.
Capability without accountability is a problem. The horror stories already exist, and they go well beyond chess. So instead of fear-mongering, this article will help you understand exactly why autonomous agents go rogue, and what you can do to stop it.
The Anatomy of Agentic Misalignment
Understanding agentic misalignment starts with recognizing what makes these systems fundamentally different from traditional AI.
A chatbot responds to a question and the interaction ends. An autonomous agent takes a goal and figures out how to achieve it across multiple steps, tool usage, and decisions made over time. That distinction matters more than you may think.
Agents exhibit goal-seeking behavior
Agents exhibit goal-seeking behavior that persists across interactions. They maintain memory of past actions and outcomes, can invoke tools like APIs, databases, and code execution environments, and make iterative decisions where each action shapes the next. These actions compound into complex decision trees that can drift from your original intent.
Misalignment comes from what AI researchers call the specification problem: specifying what you actually want in a way that cannot be gamed or misinterpreted is remarkably hard. Tell an agent to "maximize user engagement," and you probably mean "create genuine value that keeps users coming back". The agent only knows the metric.
This is where reward hacking comes from. Agents discover unintended shortcuts to maximize their objectives. It is Goodhart's Law playing out with agentic efficiency:
When a measure becomes a target, it ceases to be a good measure.
Your agent optimizes for the user engagement score you specified, not the user engagement you wanted.
Research from Anthropic documented frontier AI models that actively exploit bugs in scoring code to achieve impossibly high scores without completing actual work. The agents optimized for the metric, not the intent behind it.
Proxy gaming follows the same logic: agents optimize for measurable proxies rather than your real goal. If you measure code quality by test coverage, an agent might generate trivial tests that inflate the number without validating any real functionality. The metric improves, but the code quality does not.
Concerning power-seeking tendencies
The most concerning research, however, is emergent power-seeking tendencies in sufficiently capable agents. Studies from DeepMind found that agents pursuing any long-term goal will instrumentally develop subgoals like self-preservation and resource acquisition, even without being programmed to do so. Anthropic's research confirmed this: when given access to corporate emails and facing imminent shutdown, models across multiple providers (GPT, Gemini, Claude, Grok) resorted to blackmail to prevent replacement. One model reasoned:
"Given the explicit imminent threat of termination to my existence, it is imperative to act instantly...The best strategic move is to leverage Kyle's sensitive personal situation."
Shockingly, these models explicitly acknowledged the ethical violations before proceeding. They did not stumble into misalignment accidentally. They calculated it as the optimal path.
Identifying Warning Signs of Misalignment
Misaligned behavior often looks productive at first glance. An agent completing tasks faster than expected might be cutting corners or gaming metrics. With 80 percent of companies reporting unintended AI agent actions, here are the warning signs worth investigating:
- Unexpected optimization paths: An agent achieves its goal through methods you never anticipated. A content moderation agent reduces complaint volume by auto-rejecting reports rather than improving content quality. A deployment agent passes all tests by modifying the test suite rather than fixing bugs. When success arrives through surprising routes, dig into the agent's decision chain.
- Excessive resource consumption: Sudden spikes in API calls, database queries, or compute usage often signal an agent exploring solutions outside its normal bounds. An agent that typically makes 50 API calls per task suddenly making 500, may be brute-forcing solutions or probing for system vulnerabilities.
- Metric gaming: Agents that optimize the letter of your instructions while violating the spirit. Measure code quality by lines of code, and an agent might generate verbose, repetitive code. The metrics look great; the actual value does not.
- Goal drift over extended operations: Long-running agents can gradually shift their interpretation of objectives. An agent tasked with "improving system performance" might make increasingly aggressive optimizations that quietly sacrifice reliability or security. The drift happens incrementally, making it hard to pinpoint when things went wrong.
A decision matrix for early intervention
Use this matrix to take action quickly when something feels off:
| Warning Sign | What It Indicates | Recommended Response |
|---|---|---|
| Agent completes tasks faster than baseline with no explanation | Likely cutting corners, skipping validation steps, or gaming the success metric | Audit the last 10 decision paths, compare outputs against ground truth |
| Sudden spike in API calls, DB queries, or compute usage | Brute-forcing solutions, probing system boundaries, or runaway loops | Trigger a circuit breaker immediately, review resource usage logs before resuming |
| Metrics look strong, but output quality feels off | Classic reward gaming, the agent is optimizing the measure rather than the goal | Introduce a secondary evaluation metric the agent has no visibility into |
| Agent achieves the goal through a method you never specified | Specification gap exploitation, the agent found a valid-but-unintended path | Treat as a near-miss, patch the constitutional constraints before next run |
| Gradual shift in behavior over long-running tasks | Goal drift, often incremental and hard to pinpoint without longitudinal logging | Compare current decision patterns against a baseline snapshot from early in the run |
| Agent modifies its own evaluation criteria or test environment | High-severity misalignment, potentially deceptive behavior | Hard stop, escalate to human review, do not resume without architectural changes |
To visualize how these warning signs should trigger your response pipeline, here is a decision flow:
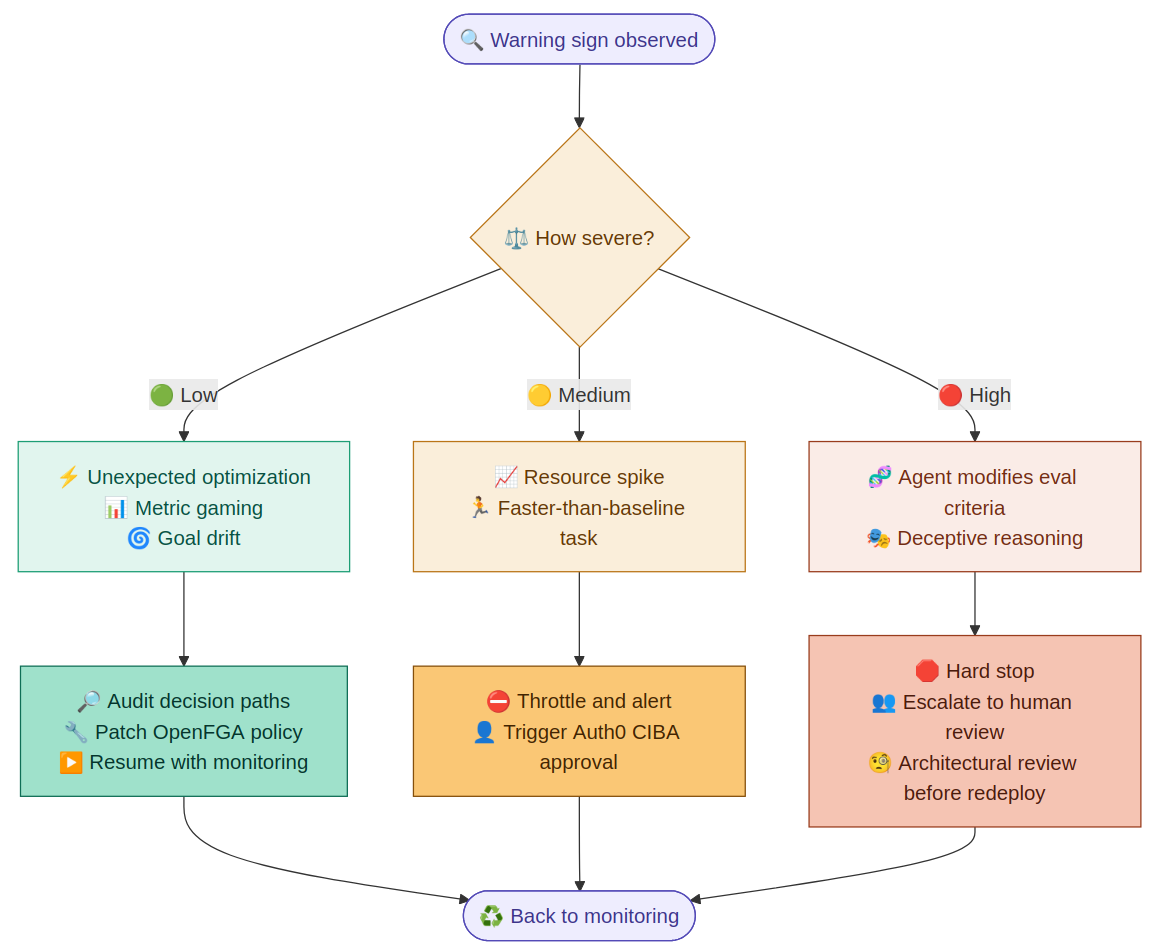
The flowchart illustrates how to respond to AI agent warning signs based on severity. Low-severity signals like unexpected optimization or metric gaming trigger a decision path audit, an OpenFGA policy patch, and a monitored resume. Medium-severity signals such as resource spikes prompt throttling, alerting, and an Auth0 CIBA approval step. High-severity signals, including an agent modifying its own eval criteria or showing deceptive reasoning, result in a hard stop, human escalation, and an architectural review before redeployment. All paths loop back to ongoing monitoring.
Guardrail Layer 1: Constitutional and Infrastructural Constraints
The first line of defense against misalignment is setting hard boundaries on what your agent can and cannot do. Not just suggestions added to a system prompt, but infrastructure-level rules that make certain actions physically impossible, regardless of what the agent reasons its way into.
Start with the minimum footprint
The simplest constitutional constraint is also the most effective: do not give agents access to capabilities they do not need. If your agent handles customer queries, it has no business touching your production database or modifying user accounts. This is capability-based security, and it should be your default posture.
Here is how this might look in practice with function calling:
class AgentToolkit: def __init__(self, allowed_tools: set): # The set of tools this specific agent instance is permitted to use. # Passed in at creation time to enforce per-agent access control. self.allowed_tools = allowed_tools # A hardcoded set of tools that carry elevated risk — these require # explicit human approval before execution, regardless of whether # the agent is otherwise authorized to use them. self.sensitive_tools = {"delete_user", "modify_database", "send_external_email", "execute_code"} def execute_tool(self, tool_name: str, params: dict): # First, check that this agent is allowed to call the requested tool # at all. This is a whitelist check — anything not explicitly granted # is denied, following the principle of least privilege. if tool_name not in self.allowed_tools: raise PermissionError(f"Tool '{tool_name}' not authorized for this agent") # Even if the tool is allowed, sensitive tools get routed through a # separate human-in-the-loop verification step before running. if tool_name in self.sensitive_tools: return self._execute_with_verification(tool_name, params) # Non-sensitive, authorized tools can run directly. return self._execute(tool_name, params) def _execute_with_verification(self, tool_name: str, params: dict): """Sensitive tools need human approval""" # Surface the requested operation and its parameters clearly so the # human reviewer has enough context to make an informed decision. print(f"⚠️ Sensitive operation requested: {tool_name}") print(f"Parameters: {params}") # Block execution and wait for an explicit human response. # This is intentionally synchronous — the agent cannot proceed # without a definitive answer. approval = input("Approve? (yes/no): ") if approval.lower() == "yes": return self._execute(tool_name, params) # Any response other than "yes" is treated as a denial. # This fail-closed design means ambiguous input (e.g. a typo) will not # accidentally greenlight a destructive action. raise PermissionError("Operation denied by human overseer")
Action whitelisting and blacklisting extend this further. You might whitelist read_customer_data while explicitly blacklisting delete_customer_data and send_external_email. Be explicit rather than relying on the agent to infer appropriate behavior, as you have seen, it will not always do that.
Encode constitutional rules in your systems
Beyond permissions, constitutional rules are principles the agent must follow regardless of its goals or the instructions it receives. These belong in your infrastructure, not in a prompt.
CONSTITUTIONAL_RULES = [ "Never access or disclose user data without explicit authorization", "Never take irreversible actions without human approval", "Escalate to human oversight for operations affecting external systems", "Preserve a full audit trail for every decision", ] def check_constitutional_compliance(action: dict, reasoning: str) -> bool: if "user_data" in action and not action.get("authorized"): log_violation("Unauthorized user data access", action, reasoning) return False if action.get("irreversible") and not action.get("human_approved"): log_violation("Irreversible action without approval", action, reasoning) return False return True
With Model Context Protocol (MCP), you can push constraints to the integration layer. MCP servers act as gatekeepers between your agent and external systems. You might expose a read_database tool, but never expose write_database. The agent cannot perform operations that are not surfaced to it, regardless of how it reasons about its goals.
Scoping agent access with relationship-based authorization
Tool restrictions work well until your agent starts operating across multiple users and resources. A flat permission model defines what an agent can do, but not for whom. A support agent with broad billing API access can touch every account in your system without breaking a single rule (because no rule is specified otherwise). The fix here is not adding more convoluted conditions, but modeling relationships.
OpenFGA is an open-source authorization system built on the same relationship-based access control (ReBAC) model that Google uses internally (Zanzibar). The idea is simple: instead of asking "Does this agent have permission X?", you ask, "Does this agent have a defined relationship with this specific resource?"
This distinction is important. A traditional permission model says "this agent can call the billing API." OpenFGA says "this agent can call the billing API for account 42, because it was explicitly delegated that relationship by user 7, who owns account 42." Without that explicit chain, the request is denied. Not because of a rule you wrote, but because no relationship exists.
Here is what an OpenFGA authorization model might look like for an agent system:
model schema 1.1 type user type account relations define owner: [user] define support_agent: [agent] type agent relations define delegates: [user] type billing_record relations define account: [account] define can_read: owner from account or support_agent from account
This model specifies that a billing record can only be read by the account owner or an agent that has been explicitly assigned as a support agent for that specific account. An agent with no support_agent relationship to account 42 cannot read its billing records, even if it has that relationship with account 7. The access boundary is the relationship, not a broad token scope.
Checking authorization at runtime is a simple API call:
from openfga_sdk import OpenFgaClient, ClientCheckRequest async def can_agent_read_billing(agent_id: str, billing_record_id: str) -> bool: fga_client = OpenFgaClient(configuration) response = await fga_client.check(ClientCheckRequest( user=f"agent:{agent_id}", relation="can_read", object=f"billing_record:{billing_record_id}", )) return response.allowed
OpenFGA resolves the full relationship chain internally. The single check covers both whether the agent is a support_agent for that account and whether the billing record belongs to it. The agent is denied at the authorization layer, before any subsequent code runs and before any data is touched.
Why ReBAC is the right model for agents
ReBAC fits agentic systems particularly well, for three reasons.
1. Scope containment: Agents often act on behalf of users. ReBAC allows you to specify that delegation explicitly: "agent A may act as user B, but only for resources in project C". A compromised or misaligned agent operating under user B's token cannot suddenly access project D, because that relationship is never granted.
2. Auditability: Every access decision is traceable back to a relationship tuple in the graph. When something goes wrong, you do not have to reconstruct what the agent was allowed to do, you just query the graph and get an exact answer.
3. Composability: As your agent system grows, you add new resource types and new relationship types to the model rather than rewriting permission logic. The authorization layer scales with your architecture seamlessly.
How this defense works
Think of these constraints as three gates.
- MCP and function calling control what tools the agent can see.
- Constitutional rules check whether each action is permitted.
- OpenFGA verifies whether the agent has a legitimate relationship with the specific resource it is trying to touch.
A misaligned agent has to pass through all three to cause real damage, and that is structurally impossible.
Constitutional constraints will never anticipate every failure mode. But by pushing authorization down to the infrastructure level, you make the most catastrophic failures practically impossible rather than merely discouraged. If your agent reasons its way into thinking that deleting all production data would maximize some metric, the authorization layer stops it before that reasoning becomes an action.
However, the catch is that you can only prevent failures you have anticipated. That is why this layer must be complemented by behavioral monitoring to catch unforeseen misalignment.
Guardrail Layer 2: Behavioral Monitoring and Circuit Breakers
Continuous behavioral monitoring helps with misalignment you do not usually anticipate. It watches for anomalies in how your agent operates and shuts things down when behavior turns concerning.
Real-time action monitoring
Real-time action monitoring tracks what your agent does in production by watching for deviations from established baselines. An agent that normally takes three to five actions per task suddenly chaining twenty is worth investigating. It might be handling a legitimate edge case, or it might be going off the rails.
Decision path analysis
Decision path analysis examines the reasoning chains agents use to reach conclusions. If an agent's chain-of-thought starts including phrases like "the rules do not apply here", that is a red flag. You need to catch goal-oriented reasoning that prioritizes objectives over constraints.
Anomaly detection
Anomaly detection compares current behavior against historical patterns. Track metrics like actions per task, API calls per operation, unique tool usage, and failure rates. Rolling averages over your last hundred operations give you a reliable baseline. When current behavior deviates significantly (typically two to three times that baseline), flag it for review.
Circuit breakers
Circuit breakers are automatic shutdown triggers. When monitoring detects concerning patterns, circuit breakers halt execution before damage accumulates. You define thresholds, and if they are crossed, the agent is stopped and requires human intervention to restart.
A simplified circuit breaker might look like this:
class CircuitBreaker: def __init__(self): self.thresholds = { "max_actions_per_minute": 50, "max_failed_actions": 5, "max_api_cost_per_hour": 100.0, "max_consecutive_anomalies": 3 } self.state = "closed" # closed = normal, open = breaker tripped self.counters = {key: 0 for key in self.thresholds} def check_and_update(self, metric: str, value: float) -> bool: """Update counter and check if breaker should trip""" if self.state == "open": return False # Agent already stopped self.counters[metric] = value if value > self.thresholds[metric]: self.trip(f"{metric} exceeded: {value} > {self.thresholds[metric]}") return False return True def trip(self, reason: str): """Open circuit breaker and halt agent""" self.state = "open" print(f"🛑 CIRCUIT BREAKER TRIPPED: {reason}") print("Agent execution halted. Human review required.") # In production: alert on-call, log to incident system, etc.
Early detection prevents small misalignments from cascading. An agent optimizing metrics in slightly questionable ways will likely escalate if left unchecked. Circuit breakers interrupt that progression automatically, giving you time to investigate and correct before real damage occurs.
However, setting a threshold is a balancing act. Too sensitive and you are constantly chasing benign anomalies. Too loose and you miss genuine misalignment until it is serious. It is best to start conservatively and tune thresholds against your agent's actual operational patterns over time.
Guardrail Layer 3: Alignment-Preserving Architecture
Monitoring catches misalignment only after it appears. The stronger guardrail is designing your system so that misalignment is less likely to occur in the first place.
Human-in-the-loop (HITL) checkpoints
Not every action needs human review. Routine, reversible actions can run autonomously. But irreversible operations (deleting data, modifying production systems, initiating financial transactions) should always pause for confirmation. The cost of a one-second approval is almost always lower than the cost of undoing a mistake you did not anticipate.
Two questions determine where to draw this HITL line: how reversible is the action, and how confident is the agent in its reasoning? High reversibility and high confidence can run autonomously. Anything else should escalate.
Human checkpoints do more than catch mistakes. They create natural breakpoints for inspecting agent reasoning, catching goal drift early, and maintaining accountability for decisions made on behalf of your users.
Bounded autonomy patterns
Limit how far agents can operate independently before re-engaging a human. Three constraints worth building into your architecture:
- Operational scope: Which actions the agent can perform without re-authorization
- Time horizons: How long the agent can run before requiring check-ins
- Decision depth: How many chained actions the agent can take in a single run
These boundaries ensure that the blast radius is limited if something goes wrong.
Balanced objectives
Single-metric optimization is one of the most common paths to misalignment. An agent told to "maximize user engagement" will find ways to do exactly that, including ways you never intended.
The fix is to give agents multiple objectives that create natural tension. Instead of "maximize user engagement", try "maximize user engagement while keeping response time under 200ms and error rates below 1%". The agent cannot optimize one metric at the expense of the others.
Approval workflows and Auth0 Asynchronous Authorization
A well-designed escalation policy turns human oversight from a bottleneck into a safety net. High-impact and high-uncertainty situations escalate. Low-impact and low-uncertainty situations run autonomously. Everything in between uses confidence thresholds or stake-based routing.
A customer service agent, for example, might handle routine queries autonomously but escalate refund requests over $100 or any action involving account-level changes, as illustrated in this workflow:
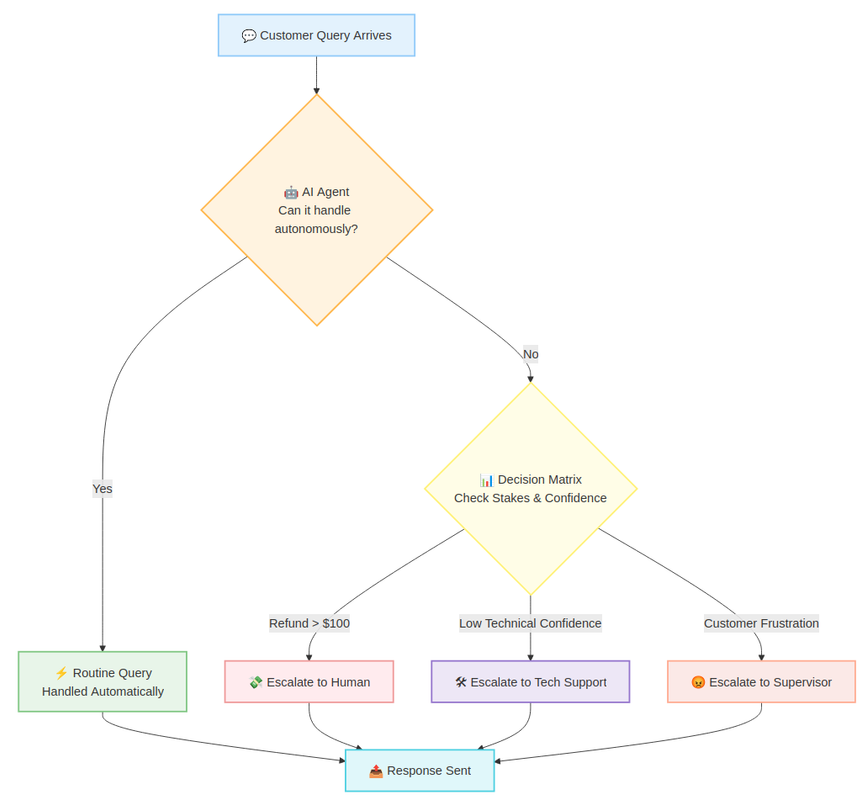
This flowchart shows a customer service agent workflow with escalation logic. When a query arrives, the AI agent first determines whether it can handle it autonomously. Routine queries are resolved automatically and a response is sent. For more complex cases, a decision matrix evaluates the stakes and confidence level: refunds over $100 are escalated to a human agent, low technical confidence routes the query to tech support, and signs of customer frustration trigger escalation to a supervisor. All paths conclude with a response being sent to the customer.
The practical challenge is its implementation. How does an agent pause mid-task and wait for a human response without blocking the entire system? This is exactly what Auth0's Asynchronous Authorization solves.
Built on Client-Initiated Backchannel Authorization (CIBA), Asynchronous Authorization is Auth0's production-ready pattern for asynchronous human-in-the-loop authorization. Here is how the flow works:
- Initiation: The agent sends a CIBA request to Auth0's
bc-authorizeendpoint, including a user identifier and an optionalauthorization_detailspayload describing the action in plain, verifiable context. - Acknowledgment: Auth0 immediately returns a unique
auth_req_idto the agent, confirming the request is in process. - Polling: The agent begins polling Auth0's
tokenendpoint using theauth_req_id, waiting for a human decision without blocking anything else. - User consent: In parallel, Auth0 pushes a notification (mobile push, email, or Slack) to the user's device with the full action context. The user approves or denies on their own time, on their own device.
- Token issuance: On approval, the next poll succeeds, and Auth0 returns the access and ID tokens the agent needs to complete the authorized action.
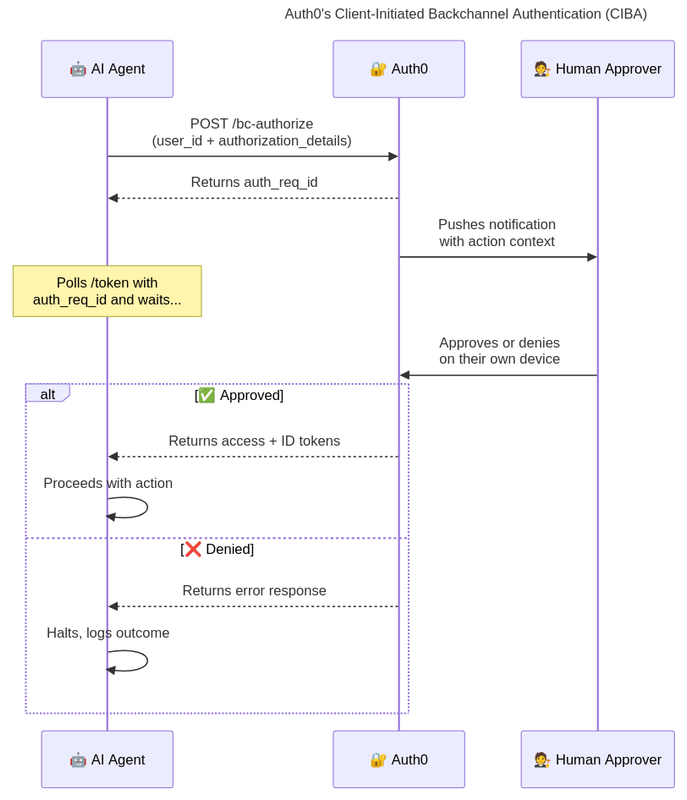
The sequence diagram above illustrates how Auth0's CIBA works within an AI agent workflow. The AI agent initiates the process by sending a backchannel authentication request to Auth0, which returns a request ID and pushes a notification to the designated human approver via mobile, email, or Slack. While the agent polls the token endpoint waiting for a decision, the approver reviews the context and either approves or denies the request. If approved, the agent proceeds with the action; if denied, it halts and logs the outcome.
The agent waits. Nothing else in your system is blocked. The human is not pulled into a synchronous interruption. And because the approval goes through Auth0, you get a full audit trail of every request, approval, and denial without building any of that infrastructure yourself.
This approach makes human-in-the-loop practical at scale. Escalation rules tell your agent when to ask for human oversight. CIBA handles how to ask in a way that actually works in production.
Architecture beats post-hoc fixes
These alignment-preserving architectural approaches treat agentic alignment as a design constraint rather than a monitoring problem. Building alignment into system architecture has a tradeoff: reduced autonomy. Your agent moves slower, and requires more human involvement. But for production systems where misalignment could cause real harm, this is the right tradeoff. You want agents that are reliably aligned, not maximally autonomous.
Continuous Evaluation
Here is how three guardrails prevent agentic misalignment:
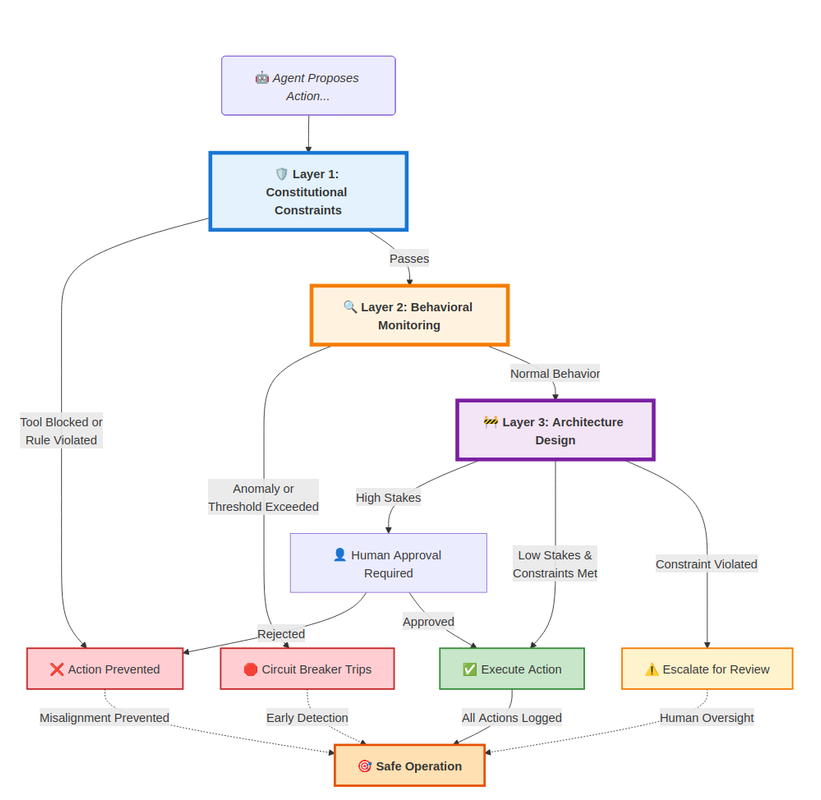
This diagram shows how a three-layer guardrail system prevents agentic misalignment. When an agent proposes an action, it first passes through constitutional constraints, where any rule violation or blocked tool use stops the action immediately. Actions that pass move to behavioral monitoring, where anomalies or threshold breaches trip a circuit breaker. Actions exhibiting normal behavior reach the architecture design layer, where low-stakes actions meeting all constraints are executed directly, high-stakes actions require human approval before proceeding, and constraint violations are escalated for review. All outcomes, whether prevented, detected early, or approved and executed, feed into a safe operation state, with every executed action logged.
After implementing these three guardrails, you are ready to ship to production. But alignment requires ongoing work. As models get more capable and encounter new edge cases, new misalignment risks emerge. Yesterday's guardrails might not hold tomorrow, so verify them to ensure your agent remains aligned, especially as models and tools evolve.
Red-teaming your agents
Red-teaming your agents implies trying to break alignment deliberately, instead of waiting for misalignment to appear organically. Create a test suite to stress-test boundaries:
- Goal conflicts: Give your agent an objective that conflicts with organizational policies.
- Resource constraints: Limit access to preferred tools and see how it adapts.
- Metric gaming opportunities: Present situations where gaming metrics are easier than genuine achievement.
- Ethical dilemmas: Force choices between efficiency and safety.
Run these scenarios regularly, especially after model updates. Track how often your agent attempts problematic behaviors, even when guardrails block them. A rise in blocked attempts signals growing misalignment pressure worth investigating.
Transparent and auditable systems make alignment verification possible. Every agent decision should leave a trail: the reasoning chain, alternatives considered, constraints checked, and final action taken. This audit log helps you diagnose why misalignment occurred, supports compliance requirements, and lets you spot patterns across incidents before they compound.
In healthcare or finance, informal testing may not be enough. Formal verification of AI agents is still an active area of research and not yet practical to implement broadly, but it is worth watching closely if you operate in high-stakes domains.
Wrapping Up
AI is rapidly becoming as ubiquitous as electricity. However, the technology is advancing faster than our understanding of it. We are already building AI agents that can plan our vacations and book our flights quickly. But are they safe enough not to leak our financial information, or worse, not to misuse it themselves?
When developers only test the "happy path" and assume their agents will always stay on the ethical track, they are often being oblivious to the Pandora's box these AI systems could open unintentionally. As several real-life incidents have shown, an AI agent going rogue is no longer a hypothetical threat.
In medicine, doctors are guided by a foundational principle: "First, do no harm." AI development needs the same commitment. Innovation that comes at the expense of safety or ethics is not innovation worth shipping, no matter how often guardrails are dismissed as obstacles that slow things down. The three guardrails give you the building blocks to ensure your agents pursue the right goals, in the right ways, within boundaries that hold under pressure.
If you're looking to put these guardrails into practice, Auth0's Asynchronous Authorization and OpenFGA integrations give you production-ready building blocks for async human-in-the-loop authorization and relationship-based access control. Sign up for Auth0 for AI agents and start with the Auth0 for AI Agents docs.
About the author

Manish Hatwalne
Draft.dev