
TL;DR: 本書では Flask や Python を使って RESTful API を開発していきます。まず、静的データ(ディクショナリ)を返すエンドポイントを作成しましょう。後で、2 つの専門分野といくつかのエンドポイントでクラスを作成し、これらクラスのインスタンスを挿入・取得します。最後に、Docker コンテナ上で API を実行する方法を見ていきます。最終コードは本書の至るところで開発されており、この GitHub レポジトリで見つけることができます。どうぞ、お楽しみください!
“Flask は Python 開発者による軽量 RESTful API の作成を可能にします。”
これをツイートする
要約
本書は次の章に分かれています。
- Python をなぜ使用するか?
- Flask をなぜ使用するか?
- Flask アプリケーションをブートストラップする
- Flask で RESTful エンドポイントを作成する
- Python クラスでモデルをマッピングする
- オブジェクトを Marshmallow でシリアル化や逆シリアル化する
- Flask アプリケーションを Docker 化する
- Auth0 で Python API をセキュアにする
- 次のステップ
Python をなぜ使用するか?
最近、Python を使ってアプリケーションを開発するのが人気になっています。最近の StackOverflow の分析によると、Python は最も急成長しているプログラミング言語のひとつで、プラットフォーム上で質問される数では Java さえも超えています。GitHub 上ではこの言語は大幅な導入の兆候が示され、2016 年に開かれたプル要求 の数では第三位を占めます。
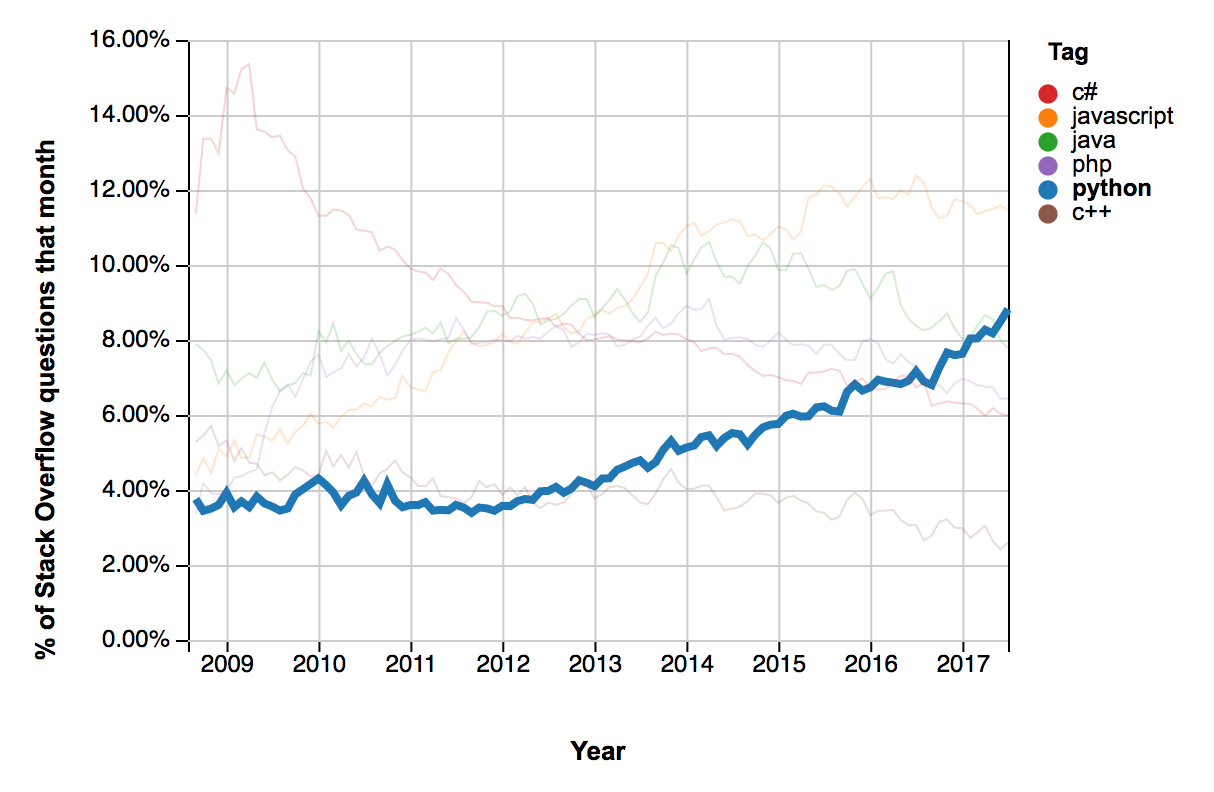
Python のまわりで形成される巨大なコミュニティは言語のあらゆる面を改善しています。増々多くのオープンソースライブラリがリリースされ、人工知能、機械学習、Web 開発などさまざまなサブジェクトに対処しています。コミュニティ全体が大きな支援を受けているほかに、Python ソフトウェア財団も優れたドキュメントを提供し、 新規採用者たちがその本質を素早く学ぶことができます。
Flask をなぜ使用するか?
Python での Web 開発に関しては、広く用いられるフレームワークが 2 つあります。Django と Flask です。Django の方が古く、より成熟しており、その人気も少し上です。GitHub 上ではこのフレームワークは 28,000 ほどのスター、1,500 の貢献者、170 未満のリリース、 11,000 以上のフォークを獲得しています。StackOverflow 上では Django に関係する質問がひと月におよそ 1.2% 投稿されています。
Flask の人気は低いですが、いい勝負です。GitHub 上では Flask は 30,000 近くのスター、445 未満の貢献者、21 未満のリリース、 10,000 近くのフォークを獲得しています。StackOverflow 上では Flask に関係する質問がひと月に 0.2% 投稿されています。
Django の方が古いですが、コミュニティは若干大きく、Flask には強味があります。Flask はスケーラビリティとシンプルさを念頭に置いて一から作られました。Flask アプリケーションは主に Django の対応部分と比較されるとき、軽量なことでよく知られます。Flask デベロッパーはこれをマイクロフレームワークと呼び、マイクロ(説明はこちら)は、目標はコアをシンプルでかつ拡張可能にすることを意味します。Flask はどのデータベースを使用するか、どのテンプレート エンジンを選択するかなどの決定はしません。最後に、Flask にも広範囲なドキュメンテーション があり、開発者が学び始める必要がある要素全てに対処しています。
軽量、導入簡単、充実したドキュメンテーション、高い人気の Flask は RESTful API を開発する上で非常に良いオプションです。
Flask アプリケーションをブートストラップする
何よりもまず、開発コンピューターに依存関係をインストールする必要があります。基本的に、インストールする必要があるものは Python 3 、Pip (Python Package Index)、 Flask です。幸運なことに、これら依存関係をインストールするプロセスは非常にシンプルです。
Python 3 をインストールする
人気の高い Linux ディストリビューション(Ubuntu)の最新バージョンを使用するのであれば、すでにコンピューターに Python 3 をインストールしている可能性があります。Windows を実行するのであれば、このオペレーションシステムはバージョンをまったく発送しないのでおそらく Python 3 をインストールする必要があります。Python 2 は Mac OS にデフォルトでインストールされており、Python 3 を自分でインストール する必要があります。
マシンに Python 3 をインストールした後、以下のコマンドを実行して予定どおりにすべてが設定されているかを確認します。
python --version # Python 3.6.2
上記のコマンドは、異なる Python バージョンを使う場合は異なる出力を生成する可能性がありますのでご注意ください。重要なことは、出力は Python 3 で始まり、Python 2 でないことです。後者が出た場合は、python3 --version の発行を試すことができます。このコマンドが正しい出力を生成すれば、本書の至る所ですべてのコマンドを置換しなければなりません。
Pip をインストールする
[Pip は Python パッケージをインストールするための推奨ツールです。公式のインストールのページ には、 Python 2 >= 2.7.9 または Python 3 >= 3.4 を使用するのであれば pip はすでにインストールされていると記載されていますが、apt を通して Ubuntu に Python をインストールすることは pip をインストールすることではありません。よって、別に pip をインストール必要があるか、またはすでにそれがあるかを確認しましょう。
pip --version # pip 9.0.1 ... (python 3.X)
上記のコマンドが pip 9.0.1 .... (python 3.X) と同様の出力を生成すれば、用意ができました。pip 9.0.1 ...(python 2.X) を取得すれば、pip と pip3 の置換を試すことができます。コンピュータで Python 3 の Pip を見つけることができなければ、Pip をインストールするにはこちら の手順に従います。
Flask をインストールする
Flask についてやその機能についてはすでに知っていますので、それをコンピュータにインストールすることやベーシックな Flask アプリケーションを実行できるかを見てみましょう。最初のステップは pip を使って次のように Flask をインストールします。
pip install Flask
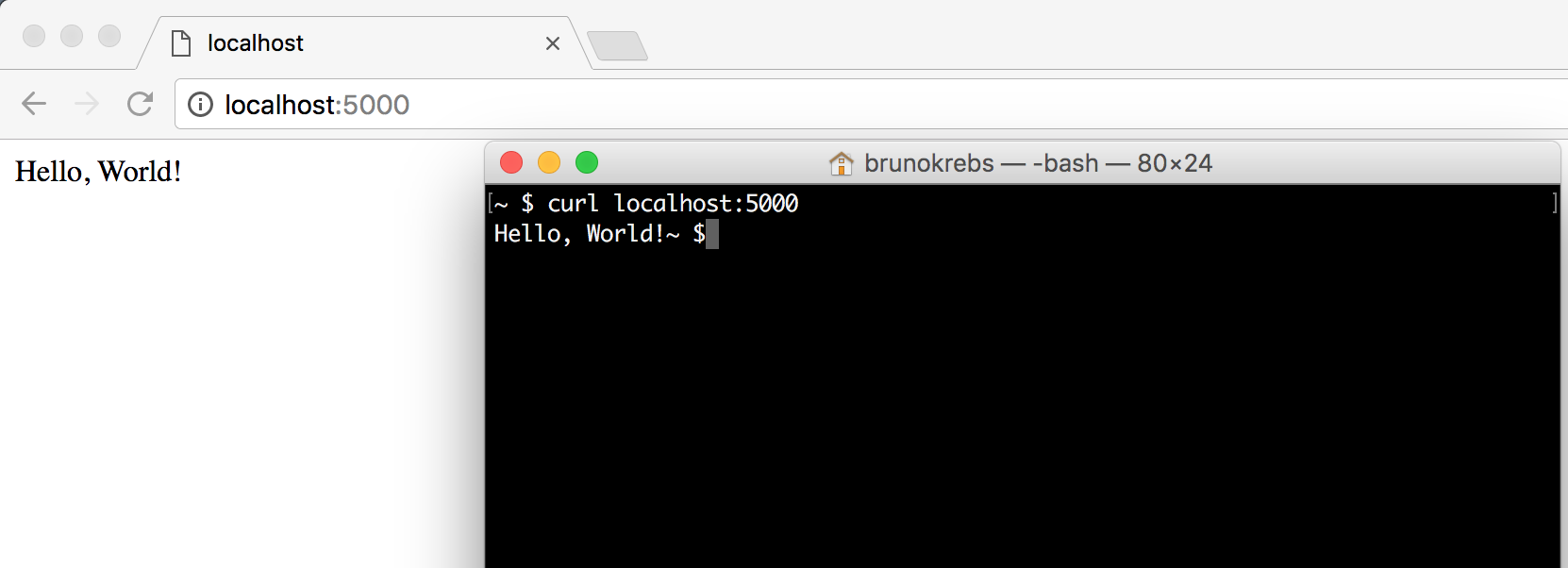
そのパッケージをインストールした後、hello.py と呼ばれるファイルを作成し、それにコード行を 5 つ追加します。Flask が正しくインストールされているかを確認するためにこのファイルを使用するので、新規ディクショナリにそれをネストする必要はありません。
from flask import Flask app = Flask(__name__) @app.route("/") def hello_world(): return "Hello, World!"
これら 5 つのコード行は HTTP 要求を処理するために必要なもので、「世界の皆さん、こんにちは!」というメッセージを返します。それを実行するには、FLASK_APP と呼ばれる環境変数をエクスポートする必要があり、それから次のように flask を実行します。
export FLASK_APP=hello.py flask run # * Serving Flask app "hello" # * Running on http://127.0.0.1:5000/ (Press CTRL+C to quit)
Flask を直接実行するには Ubuntu 上で、$PATH 変数を編集する必要があるかもしれません。そのためには、touch ~/.bash_aliases を実行してから echo "export PATH=$PATH:~/.local/bin" >> ~/.bash_aliases を実行しましょう。
これらのコマンドを実行した後、ブラウザを開けて http://127.0.0.1:5000/ に移動するか、curl http://127.0.0.1:5000/ を発行してアプリケーションに到達します。
仮想環境(virtualenv)
PyPA(Python Packaging Authority 団体)は Python をインストールするツールとして pip を勧めていますが、プロジェクトの依存関係を管理するには別のパッケージを使う必要があります。pip は requirements.txt ファイルを介するパッケージ管理 をサポートしますが、このツールはさまざまな製品や開発コンピュータで実行するために、重大なプロジェクトで使用する一部の機能が欠けています。その問題の中で、最大の問題原因となるものは次のとおりです。
pipがグローバルにパッケージをインストールし、同じコンピュータで同じパッケージの複数のバージョンを管理することが困難になるrequirements.txtは明示的にリストされているすべての依存関係と副次的な依存関係、退屈でエラーが発生しそうな手動プロセスが必要である
これら問題を解決するために、Pipenv を使用していきます。Pipenv は依存関係マネージャで、プライベート環境でプロジェクトを分離し、パッケージによるプロジェクト当たりのインストールが可能になります。NPM または Ruby 同梱についておなじみの方は、これらツールの考え方の点で同様です。
pip install pipenv
では、本格的な Flask アプリケーションを作成し始めるために、ソースコードを保留する新ディレクトリを作成しましょう。本書では、ユーザーが収益や費用を管理できる小規模の RESTful API、Cashman を作成しましょう。よって、cashman-flask-project と呼ばれるディレクトリを作成します。その後、pipenv を使ってプロジェクトを開始し、依存関係を管理します。
mkdir cashman-flask-project && cd cashman-flask-project pipenv --three pipenv install flask
2 つめのコマンドは仮想関係を作成し、そこですべての依存関係がインストールされます。3 つめのものは最初の依存関係として Flask を追加します。プロジェクトのディレクトを確認すれば、これら 3 つのコマンドを実行した後に次のように 2 つのファイルが作成されているのが分かります。
Pipfileは私たちが使用している Python バージョンのようなプロジェクトや、プロジェクトが必要なパッケージの詳細を含むファイル。Pipfile.lockはプロジェクトが依存する各パッケージの正確なバージョンと、その推移的な依存関係を含むファイル。
Python モジュール
その他主流のプログラミング言語のように、開発者がサブジェクト/機能に従ってソースコードを整理するために、Python にもモジュールの概念があります。Java パッケージや C# 名前空間と同様に、その他 Python スクリプトによってインポートされる Python のモジュールはディレクトリで整理するファイルです。Python アプリケーションにモジュールを作成するには、フォルダを作成し、__init__.py と呼ばれる空のファイルをそれに追加する必要があります。
最初のモジュールをアプリケーションで作りましょう。これは、すべての RESTful エンドポイントを使って、メインモジュールになります。アプリケーションに作成したディレクトリ内に、同じ名前の cashman をもうひとつ作りましょう。前に作成したメイン cashman-flask-project ディレクトリには持っている依存関係のように、プロジェクトのメタデータを保留すると同時に、この新しいものは Python スクリプトを使ったモジュールになります。
mkdir cashman && cd cashman touch __init__.py
メインモジュール内に、index.py と呼ばれるスクリプトを作りましょう。このスクリプト内で、アプリケーションのプライマリ エンドポイントを定義します。
from flask import Flask app = Flask(__name__) @app.route("/") def hello_world(): return "Hello, World!"
丁度前例のように、このアプリケーションは「世界の皆さん、こんにちは!」というメッセージを返します。すぐにこれを改善しますが、まず bootstrap.sh と呼ばれる実行可能ファイルをアプリケーションのメインディレクトリに作成しましょう。
cd .. touch bootstrap.sh chmod +x bootstrap.sh
このファイルの目標はアプリケーションのスタートアップを容易にすることです。そのソースコードは次のとおりです。
#!/bin/sh export FLASK_APP=./cashman/index.py source $(pipenv --venv)/bin/activate flask run -h 0.0.0.0
最初のコマンドは丁度、「世界の皆さん、こんにちは!」アプリケーションを実行したように、Flask が実行するメインスクリプトを定義します。2 つめのコマンドは pipenv を作成することで仮想環境をアクティベートしますからアプリケーションはその依存関係を見つけ、実行できます。最後にコンピュータ上の全てのインターフェイスをリッスンする Flask アプリケーションを実行します(-h 0.0.0.0)。
このスクリプトが正しく動作しているかを確認するために、ここで ./bootstrap.sh を実行します。 これは、「世界の皆さん、こんにちは!」アプリケーションを実行したときと同じような結果になります。
# * Serving Flask app "cashman.index" # * Running on http://0.0.0.0:5000/ (Press CTRL+C to quit)
Flask で RESTful エンドポイントを作成する
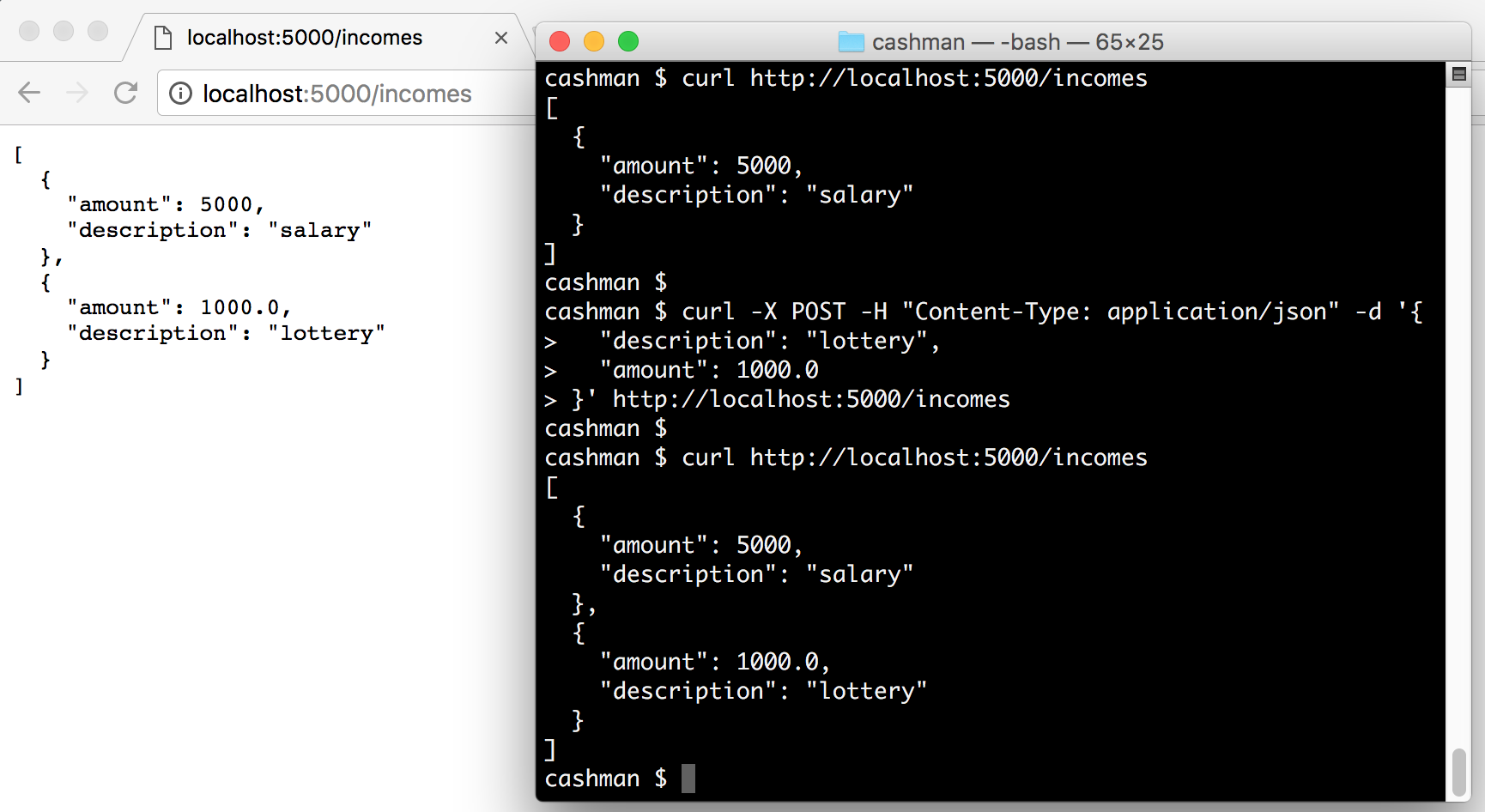
これで、アプリケーションを構造化したので、関係のあるエンドポイントを定義し始めることができます。前述したように、このアプリケーションの目標はユーザーが収益や費用を管理できるようにすることです。手始めに、収益を処理する 2 つのエンドポイントを定義することから始めましょう。./cashman/index.py ファイルのコンテンツと以下を置換しましょう。
from flask import Flask, jsonify, request app = Flask(__name__) incomes = [ { 'description': 'salary', 'amount': 5000 } ] @app.route('/incomes') def get_incomes(): return jsonify(incomes) @app.route('/incomes', methods=['POST']) def add_income(): incomes.append(request.get_json()) return '', 204
今、このアプリケーションを改善中なので、「世界の皆さん、こんにちは!」のメッセージをユーザーに返すエンドポイントを削除しました。その場所に、収益を返す HTTP GET 要求を処理するエンドポイントと、新しい収益を追加する HTTP POST 要求を処理するもうひとつのエンドポイントを定義しました。これらエンドポイントは @app.route で注釈を付け、/incomes エンドポイントの要求をリッスンすることを定義します。Flask にはこの正確な機能に関する優れた説明書があります。
現時点では、このプロセスを容易にするために収益を dictionaries として操作しています。まもなく、収益と費用を表すクラスを作成します。
作成した両方のエンドポイントとインタラクトするために、アプリケーションを始めて次の HTTP 要求を発行します。
./bootstrap.sh & curl http://localhost:5000/incomes curl -X POST -H "Content-Type: application/json" -d '{ "description": "lottery", "amount": 1000.0 }' http://localhost:5000/incomes curl localhost:5000/incomes
Python クラスでモデルをマッピングする
上記のように非常に簡単な使い方のディクショナリで十分です。ただし、さまざまなエンティティで取引したり、複数のビジネスルールや検証がある複雑なアプリケーションでは、データを Python クラス に要約する必要があるかもしれません。
クラスとしてエンティティ(収益など)をマッピングするプロセスを学ぶには、アプリケーションをリファクタします。最初に、すべてのエンティティを保留するサブモジュールを作成します。cashman モジュール内に model と呼ばれるディレクトリ(これはメインディレクトリではなく、cashman サブディレクトリです)を作成し、それに __init__.py と呼ばれる空のファイルを追加しましょう。
mkdir -p cashman/model touch cashman/model/__init__.py
Python スーパークラスをマッピングする
この新規モジュール/ディレクトリ内に、Transaction、Income、Expense の 3 つのクラスを作成します。最初のクラスは他の 2 つのクラスのベースになります。それを Transaction と呼びます。次のコードを使って、model ディレクトリ内に transaction.py と呼ばれるファイルを作成しましょう。
import datetime as dt from marshmallow import Schema, fields class Transaction(): def __init__(self, description, amount, type): self.description = description self.amount = amount self.created_at = dt.datetime.now() self.type = type def __repr__(self): return '<Transaction(name={self.description!r})>'.format(self=self) class TransactionSchema(Schema): description = fields.Str() amount = fields.Number() created_at = fields.Date() type = fields.Str()
Transaction クラスのほかに、TransactionSchema も定義することに注意してください。JSON オブジェクトから/までの Transaction のインスタンスを逆シリアル化とリリアル化する後者を使用します。このクラスはパッケージで定義されていますが、まだインストールされていない Schema と呼ばれるもうひとつのスーパークラスから継承されます。
# installing marshmallow as a project dependency pipenv install marshmallow
Marshmallow は人気の高い Python パッケージ で、オブジェクトのような複雑なデータ型をネイティブ Python データ型から、あるいはその逆に変換します。基本的に、このパッケージを使ってデータを検証し、逆シリアル化、シリアル化します。本書では検証は別のテーマになるので、検証については説明しません。前述しましたが、エンドポイントを通してエンティティをシリアル化と逆シリアル化する marshmallow を使用します。
Python クラスとして収益と費用をマッピングする
本書の内容を組織化し有意義にするために、エンドポイントでは Transaction クラスについては表示しません。要求を処理するためにIncome と Expense の 2 つの専門分野を作ります。次のコードを使って、model モジュール内に income.py と呼ばれるファイルを作成しましょう。
from marshmallow import post_load from .transaction import Transaction, TransactionSchema from .transaction_type import TransactionType class Income(Transaction): def __init__(self, description, amount): super(Income, self).__init__(description, amount, TransactionType.INCOME) def __repr__(self): return '<Income(name={self.description!r})>'.format(self=self) class IncomeSchema(TransactionSchema): @post_load def make_income(self, data): return Income(**data)
アプリケーションにこのクラスが追加する唯一の値はそのトランザクションのタイプをハードコードすることです。このタイプは Python 列挙子 で、それをまだ作成する必要があり、将来、トランザクションをフィルター処理するときに役立ちます。この列挙子を表す transaction_type.py と呼ばれるもう一つのファイルを model 内に作成しましょう。
from enum import Enum class TransactionType(Enum): INCOME = "INCOME" EXPENSE = "EXPENSE"
この列挙子のコードはとてもシンプルです。それは Enum から継承される TransactionType と呼ばれるクラスを定義し、INCOME と EXPENSE の2つのタイプを定義します。
最後に、費用を表すクラスを作りましょう。そのためには、次のコードを使って、expense.py と呼ばれる新規ファイルを model 内に作ります。
from marshmallow import post_load from .transaction import Transaction, TransactionSchema from .transaction_type import TransactionType class Expense(Transaction): def __init__(self, description, amount): super(Expense, self).__init__(description, -abs(amount), TransactionType.EXPENSE) def __repr__(self): return '<Expense(name={self.description!r})>'.format(self=self) class ExpenseSchema(TransactionSchema): @post_load def make_expense(self, data): return Expense(**data)
Income と同様に、このクラスはトランザクションのタイプをハードコードしますが、今は EXPENSE をスーパークラスにパスします。異なる点は負にパスするために amount を強制することです。よって、ユーザーが正の値や負の値を送信したとしても、それを負として保存して計算を容易にします。
オブジェクトを Marshmallow でシリアル化や逆シリアル化する
Transaction スーパークラスやその専門分野が適切に実装されたので、これらクラスに対応するエンドポイントを拡張できます。./cashman/index.py コンテンツを次に置換しましょう。
from flask import Flask, jsonify, request from cashman.model.expense import Expense, ExpenseSchema from cashman.model.income import Income, IncomeSchema from cashman.model.transaction_type import TransactionType app = Flask(__name__) transactions = [ Income('Salary', 5000), Income('Dividends', 200), Expense('pizza', 50), Expense('Rock Concert', 100) ] @app.route('/incomes') def get_incomes(): schema = IncomeSchema(many=True) incomes = schema.dump( filter(lambda t: t.type == TransactionType.INCOME, transactions) ) return jsonify(incomes.data) @app.route('/incomes', methods=['POST']) def add_income(): income = IncomeSchema().load(request.get_json()) transactions.append(income.data) return "", 204 @app.route('/expenses') def get_expenses(): schema = ExpenseSchema(many=True) expenses = schema.dump( filter(lambda t: t.type == TransactionType.EXPENSE, transactions) ) return jsonify(expenses.data) @app.route('/expenses', methods=['POST']) def add_expense(): expense = ExpenseSchema().load(request.get_json()) transactions.append(expense.data) return "", 204 if __name__ == "__main__": app.run()
実装したばかりの新しいバージョンは incomes 変数を Expenses と Incomes のリストに再定義することから始め、transactions と呼ぶことにします。この他に、収益に対応する両方の実装方法も変更しました。収益を取得するために使用するエンドポイントには、収益の JSON IncomeSchema 表記を創り出すインスタンスを定義します。また、filter も使用して transactions リストからのみ収益を抽出します。最後に、JSON 収益の配列をユーザーに戻します。
新しい収益を受理する担当のエンドポイントもリファクタリングされます。このエンドポイントの変更は、ユーザーによって送信された JSON データを基に Income のインスタンスをロードするために、IncomeSchema を追加しました。Transactions リストが Transaction とそのサブクラスを対処するので、新しい Income をそのリストに追加しました。
費用に対処する責任があるその他 2 つのエンドポイント、get_expenses と add_expense は income 対応部分のほとんどをコピーしたものです。その違いは次のとおりです。
Incomeのインスタンスに対応する代わりに、Expenseのインスタンスに対応して新しい費用を受け入れるINCOMEでフィルタする代わりに、EXPENSEでフィルタしてユーザーに費用を戻す
これで API の実装は終わりです。今 Flask アプリケーションを実行すれば、以下に表示のようにエンドポイントで対話できるようになります。
# start the application ./bootstrap.sh & # get expenses curl http://localhost:5000/expenses # add a new expense curl -X POST -H "Content-Type: application/json" -d '{ "amount": 20, "description": "lottery ticket" }' http://localhost:5000/expenses # get incomes curl http://localhost:5000/incomes # add a new income curl -X POST -H "Content-Type: application/json" -d '{ "amount": 300.0, "description": "loan payment" }' http://localhost:5000/incomes
Flask アプリケーションを Docker 化する
最終的にはクラウドで API を作成する予定ですので、Docker コンテナでアプリケーションを実行するために必要なことを説明する Dockerfile を作成して行きます。プロジェクトの Docker 化されたインスタンスをテスト・実行するために 開発コンピュータに Docker をインストールする 必要があります。Docker レシピ(Dockerfile)を定義すると、さまざまな環境で API を実行するのに役立ちます。つまり、将来、Docker もインストールし、生産 や ステージング のような環境でプログラムを実行していきます。
次のコードでプロジェクトのルート ディレクトリに Dockerfile を作りましょう。
# Using lightweight alpine image FROM python:3.6-alpine # Installing packages RUN apk update RUN pip install --no-cache-dir pipenv # Defining working directory and adding source code WORKDIR /usr/src/app COPY Pipfile Pipfile.lock bootstrap.sh ./ COPY cashman ./cashman # Install API dependencies RUN pipenv install # Start app EXPOSE 5000 ENTRYPOINT ["/usr/src/app/bootstrap.sh"]
レシピの最初のアイテムは既定の Python 3 Docker イメージ をベースに Docker コンテナを作成することを定義します。その後、APK を更新し、pipenv をインストールします。pipenv があることで、イメージで使用する作業ディレクトリを定義し、アプリケーションをブートストラップし実行するために必要なコードをコピーします。4 つめのステップでは、すべての Python 依存関係をインストールする pipenv を使用します。最後に、イメージはポート 5000 を通して通信することと、このイメージは実行されたとき、Flask を始めるために bootstrap.sh スクリプトを実行する必要があることを定義します。
作成した Dockerfile をベースにして Docker コンテナを作成・実行するには、次のコマンドを実行できます。
# build the image docker build -t cashman . # run a new docker container named cashman docker run --name cashman \ -d -p 5000:5000 \ cashman # fetch incomes from the dockerized instance curl http://localhost:5000/incomes/
Dockerfile はシンプルですが有効で、その使用方法も同様に簡単です。これらコマンドと Dockerfile で、必要なだけのAPI インスタンスを問題なく実行できます。ホストでまたは別のホストで別のポートを定義するだけです。
Auth0 で Python API をセキュアにする
Auth0 で Python API をセキュアにすることはとても簡単で、たくさんの素晴らしい機能を提示します。Auth0 を使って、次を得るために少数のコード行を書くだけです。
- 確かな アイデンティティ管理ソリューション(シングル サインオン を含む)
- ユーザー管理
- ソーシャル ID プロバイダー(Facebook、GitHub、Twitterなど)のサポート
- エンタープライズ ID プロバイダー(Active Directory、LDAP、SAMLなど)
- 独自のユーザーデータベース
例えば、Flask で書いた Python API をセキュアにするには、requires_auth デコレータを作成するだけです。
# Format error response and append status code def get_token_auth_header(): """Obtains the access token from the Authorization Header """ auth = request.headers.get("Authorization", None) if not auth: raise AuthError({"code": "authorization_header_missing", "description": "Authorization header is expected"}, 401) parts = auth.split() if parts[0].lower() != "bearer": raise AuthError({"code": "invalid_header", "description": "Authorization header must start with" " Bearer"}, 401) elif len(parts) == 1: raise AuthError({"code": "invalid_header", "description": "Token not found"}, 401) elif len(parts) > 2: raise AuthError({"code": "invalid_header", "description": "Authorization header must be" " Bearer token"}, 401) token = parts[1] return token def requires_auth(f): """Determines if the access token is valid """ @wraps(f) def decorated(*args, **kwargs): token = get_token_auth_header() jsonurl = urlopen("https://"+AUTH0_DOMAIN+"/.well-known/jwks.json") jwks = json.loads(jsonurl.read()) unverified_header = jwt.get_unverified_header(token) rsa_key = {} for key in jwks["keys"]: if key["kid"] == unverified_header["kid"]: rsa_key = { "kty": key["kty"], "kid": key["kid"], "use": key["use"], "n": key["n"], "e": key["e"] } if rsa_key: try: payload = jwt.decode( token, rsa_key, algorithms=ALGORITHMS, audience=API_AUDIENCE, issuer="https://"+AUTH0_DOMAIN+"/" ) except jwt.ExpiredSignatureError: raise AuthError({"code": "token_expired", "description": "token is expired"}, 401) except jwt.JWTClaimsError: raise AuthError({"code": "invalid_claims", "description": "incorrect claims," "please check the audience and issuer"}, 401) except Exception: raise AuthError({"code": "invalid_header", "description": "Unable to parse authentication" " token."}, 400) _app_ctx_stack.top.current_user = payload return f(*args, **kwargs) raise AuthError({"code": "invalid_header", "description": "Unable to find appropriate key"}, 400) return decorated
それから、それを次のようにエンドポイントで使用します。
# Controllers API # This doesn't need authentication @app.route("/ping") @cross_origin(headers=['Content-Type', 'Authorization']) def ping(): return "All good. You don't need to be authenticated to call this" # This does need authentication @app.route("/secured/ping") @cross_origin(headers=['Content-Type', 'Authorization']) @requires_auth def secured_ping(): return "All good. You only get this message if you're authenticated"
Python APIを Auth0 でセキュアにすることについての詳細は、このチュートリアルをご覧ください。バックエンド技術(Python、Java、PHP)のチュートリアルと平行して、Auth0 DocsWebページもモバイル/ネイティブアプリやシングルページアプリケーションの_チュートリアルも提供しています_。
次のステップ
本書では、よく構造された Flask アプリケーションを開発するために必要な基本のコンポーネントについて学びました。API の依存関係を管理するために pipenv の使用方法について見てきました。その後、JSON 応答の送受信が可能なエンドポイントを作成するために Flask や Marshmallow をインストールして使用しました。最後に、クラウドへのアプリケーシあョンのリリースを容易にする API を Docker 化する方法についても学びました。
API はよく構造化されていますが、まだそれほど役に立ちません。次の章では改善できる点の中から、次のトピックについて学んで行きます。
- SQLAlchemy に伴うデータベース
- グローバルな例外処理
- 国際化(i18n)
- JWT とのセキュリティ
見逃さないように!
About the author

Bruno Krebs
R&D Content Architect (Auth0 Alumni)