
Auth0 is providing a world-class service empowering the critical path of millions of logins around the world, so it’s important that we ensure our services are performing well while keeping our infrastructure efficient. The Performance and Resilience Testing team was established in late 2021, as Auth0 made a lot of improvements in its resilience posture. Together with Platform and Product teams, we work toward upholding that performance, reliability, and resilience posture that is such an important pillar of Auth0.
During 2022, the development of Auth0’s new Kubernetes-based platform ramped up, which allows for a more repeatable and automated deployment of public and private cloud environments. Since then, our team began a natural partnership with the Platform teams and started working on defining the Private Cloud offerings for our customers.
One of our key responsibilities has been to define performance tiers for private cloud customers based on different RPS (requests per second) thresholds - 100 RPS, 500 RPS, and 1500 RPS (with more to come). This initiative, called Tier Right-Sizing, is essential to ensuring Auth0 is able to provide our customers with offerings whose infrastructure costs are efficient for their needs, allowing our sales teams to more accurately sell to customers based on their capacity and performance needs. This blog post outlines the process we followed to define these tiers.
Our Performance Testing Tooling
As you’ll find out as you read the blog post, in order to define these tiers, our team (and many other individuals at Auth0) ran countless performance tests of varying durations. One of the key things our team works on is the tooling and infrastructure for Performance Testing for the whole Engineering organization.
For the last three years, we’ve used Artillery to run Performance Tests at Auth0, and it has allowed us to scale easily as usage of our framework organically grew within the company. This was important for a few reasons:
- Firstly, because in the last year and a half, the adoption of our framework went from a few people running Performance Tests at Auth0 to almost every engineering team;
- Secondly, because the scope of our tests also grew. For example, in December 2022, as part of the Tier Sizing for a larger customer, we ran 6,000+ RPS tests, which Artillery was able to easily handle thanks to leveraging AWS Fargate’s horizontal scaling.
We’ve also written our own CLI (a wrapper around the Artillery CLI called Airstrike), which has allowed us to standardize Artillery usage across the organization and cater to Auth0-specific use cases. Developers can now run authentication flows they’re familiar with by name, point it at an environment of their choice and simply type a target RPS, all without having to use an Artillery config. This abstracts even further the work of running a Load Test, which is especially helpful for teams that might not be product experts but still need to understand the performance impact of their work, such as platform teams. For example, anyone can run the authorizationCode scenario in a specific internal environment at any given RPS, for the duration they need, and with their desired load profile. All they need to do is run this fully configurable command:
airstrike run authorizationCodeNew --env tus1 --targetRPS 100 --targetDuration 3600 --loadProfile spike
Additionally, the latest Artillery offering, Artillery Dashboard, was also an important part of this Tier Right Sizing effort. Since Airstrike programmatically adds the relevant tags to tests by default, we were able to leverage the dashboard as a centralized location to view all our Performance Test reports for this effort, by filtering by tags to get the relevant test executions. Any load test report is available there for easy historical reference with all its results, logs, and graphs, and we found it easy to consume for stakeholders and developers alike.
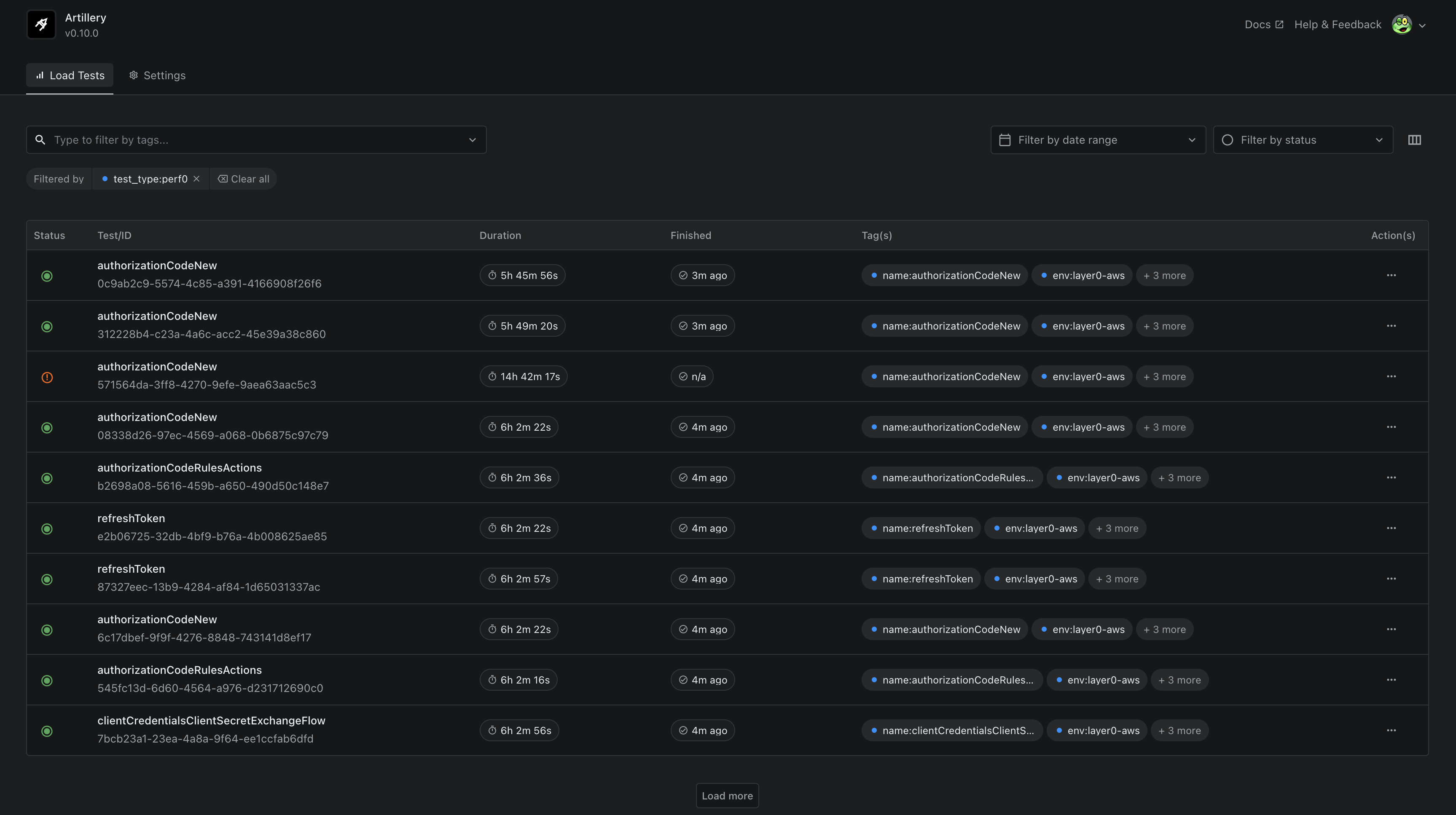
Tier Right Sizing
My team followed a thorough four-step process which I’ll outline in this section. This process was followed for each of the tiers we’ve defined (5 private cloud tiers total). For all phases, a subset of core authentication scenarios was chosen by our Product team, which represents key product patterns our customers use.
Phase 1 - Exploratory Investigations
During this phase, the team worked together with Platform experts on experimenting with several infrastructure sizings and configurations, including:
- Number of resources needed for main services;
- Database Instance Sizes;
- Burstable Instance types;
- Kubernetes Nodes Instance Sizes;
- Kubernetes resource allocation;
- etc.
Since there were a lot of permutations to try, each experiment was only a 10-15 minute load test. This phase can almost be compared to “Exploratory Testing”. Apply an infrastructure change, run a load test, analyze results, rinse and repeat. It gave my team a good sense of the “gotchas” of the new platform, and served to develop an instinct for what would work and what wouldn’t.
Once the team had arrived at what they believed to be an optimal configuration, it was time to prove that.
Phase 2 - 1-Hour Baseline Load
This phase was the main acceptance criteria given to us by Product. Once we reached a stable configuration in Phase 1, the intent was to prove that it could hold the Performance SLA for 1 Hour at the defined Max RPS for the tier, for each of the core scenarios (ran sequentially).
If it failed the SLA, it was then necessary to go back to Phase 1 with more experiments until the team narrowed down a working configuration again.
Phase 3 - 6-Hour Synthetic Load
The previous phase (1-Hour Baseline Load) gave us confidence in the performance of each individual scenario at peak load, but that’s not always a typical traffic pattern. Realizing this, we decided to borrow from a concept we have in our Staging environments we call “Synthetic Load”, which emulates production-like traffic by running multiple weighted scenarios at the same time.
For this effort, we added to our existing core scenarios a few more scenarios that customers are likely to have in their environments (Management API, Extensibility, etc.), creating a 6-hour Synthetic Load test, with a total RPS of the Max RPS for the Tier. This gave us confidence that the Tier would perform under more normal production-like conditions, when a lot more services are being hit.
Phase 4 - 72-Hour Soak Test
The final piece of due diligence was to ensure that we didn’t see a performance impact from any memory leaks, cron jobs, database background operations, etc. For that reason, after consulting with a few experts in the system, we decided to be safe and run long soak tests. These gave us confidence that we wouldn’t see a problem manifest itself over time.
This ended up being a crucial part of the process and actually revealed a few important performance improvements that had to be done in our platform.
Rollout
After the new tier definitions were live, all new customers used the new tier definitions. However, in a few cases, we had customers already migrated to our new Private Cloud platform, but not yet in our new optimized tiers. In order to guarantee a seamless transition to the newly defined tiers, a dedicated Platform team worked on a release plan.
All infrastructure changes were gradually rolled out to customers through our automated release pipeline. Changes were broken down into small batches, and thanks to our automated testing and the soak time built into our release pipeline, Platform teams were able to monitor each change going in to ensure no issues had been introduced, therefore minimizing any risk during this transition.
Conclusion
Right Sizing infrastructure is a game of balancing infrastructure cost and performance. There is no right final answer, and while this effort has taken us quite a bit of time, it will likely never be fully done - we will continue to optimize and improve on this over time. In a few cases, we have also had to do this exercise for specific customers with more unique and large-scale use cases (adapting which scenarios were used), so we will be working on generalizing some of these customer patterns.
I want to leave a final note that we were very excited to support this effort on the road to providing a modern platform for our customers. On a personal note, I am incredibly proud of my team for their contributions to this project, from the work in the tooling that eventually supported this effort to the people who directly worked on the project. It’s exciting to take our new platform to higher limits and take on bigger and bigger customers!
About the author

Bernardo Guerreiro
Engineering Manager (Performance and Resilience Testing)