
AI agents are rapidly making their way into production systems with access to real customer data, internal tooling, and revenue-impacting workflows. A support automation agent might read tickets from a CRM, summarize conversation history, issue partial refunds, create internal escalation tickets, and post a status update to Slack, all within the span of a single task. When these agents work, they can streamline workflows and compress the cost of routine operations. When they fail, they fail differently than traditional automation: non-deterministically, at scale, and often with full production credentials in hand.
To be useful, an agent needs enough access to execute dynamic, multi-step workflows across multiple tools. But to be safe, it can't operate as a "superuser" with permanent, broad authority over those same tools. Most teams tend to default to access patterns they already know, like long-lived API keys baked into environment variables or OAuth flows designed for human users, and discover quickly that these patterns were never built for non-deterministic software. A misconfigured prompt, a malicious tool response, or a simple hallucination can turn into a significant incident.
This guide teaches you how to apply the least-privilege principle to autonomous systems. You'll learn how to scope permissions to capabilities rather than resources, issue short-lived credentials tied to specific execution plans, separate identity, authorization, and execution into distinct layers, and introduce human-in-the-loop approval for high-risk actions.
The Access Model Mismatch
Traditional access control models assume you are one of two actors:
- The first is a human user: interactive, bounded by a session, constrained by a UI, and generally predictable within a single workflow.
- The second is a backend service: deterministic, fixed in its workflow, and auditable through static code paths. AI agents fit neither category.
Agents are non-deterministic by design. Two runs of the same prompt against the same data can produce different tool call sequences. They chain tool invocations in ways the developer did not explicitly write, and they can be influenced by untrusted input through two well-documented threat classes:
- Prompt injection: Instructions embedded in a document or web page hijack the agent's behavior.
- Tool output poisoning: A tool response manipulates subsequent decisions in the chain.
Increasingly, agents also spawn sub-agents, so a delegation chain that starts with a single user request can fan out across many independent contexts before it completes.
The identity primitives built for these two types of actors (session tokens, service accounts, and OAuth scopes) are not broken in isolation; used with strict scoping, mediation, and runtime enforcement, they can work well. The issue is that they were not designed for non-deterministic, multi-step autonomous execution, and their typical usage patterns, which assume a bounded session or a deterministic workflow, do not hold. A session token assumes a bounded interactive flow. A service account assumes deterministic behavior. An OAuth scope like billing:write assumes an application on the other end interprets it as intended by the user.. When an agent inherits any of these without additional layers, it gets authority without the corresponding accountability structures that made the original model safe.
Common Anti-Patterns
Before reviewing better patterns, it's worth looking at the shortcuts teams typically reach for. Each one feels reasonable in isolation, but together, they can be dangerous.
Embedding long-lived credentials
The first common anti-pattern is embedding long-lived API keys directly in agent configurations or environment variables. The agent holds a root credential that grants broad access to a tool, and any compromise of the agent process, logs, or memory exposes that credential. While this is also a problem in non-agentic software, the risk is elevated with agents because, depending on how they are configured, they can be tricked or coerced into taking actions they shouldn’t, or revealing credentials they have access to, much more easily than traditional software with long-lived credentials can be exploited.
Even with rotation in place via something like Vault or AWS Secrets Manager, the real issue is blast radius; rotation is often inconsistent or slow, and the window between compromise and rotation is more than enough for an attacker (or a misbehaving agent) to do significant damage.
Full user OAuth scope inheritance
The second anti-pattern is full user OAuth scope inheritance. A user grants the agent access to their CRM with the permissions they themselves hold, and the agent now has those scopes permanently, across every future action, regardless of what task it is actually performing. The agent inherits authority that the user only ever intended to exercise selectively. However, the agent does not have the discretion, contextual awareness, or accountability that the user has, and it is only a matter of time before the agent accidentally misuses these overly broad permissions.
Agents with effective superuser privileges
The third, and most damaging anti-pattern, is agents operating with effective superuser privileges over the tools they orchestrate, typically at a system-level, rather than an individual user-level. This happens implicitly when you use the most permissive available scope rather than defining a narrower one. The support agent mentioned earlier might be given a billing:write scope because it's the only billing scope available, and now it can issue refunds of any size, modify any customer's payment method, and cancel any subscription, even though its actual job is issuing small goodwill refunds within a narrow policy.
Consider what happens when a support operations agent with billing:write is asked by a user, "Process a full refund for order #12345." The order total is $10,000 USD. With no way to distinguish between refund sizes it's allowed to process, and those it is not, the agent simply proceeds. Nothing in the access layer prevents it. The damage is done in milliseconds, and the only audit trail is a refund record that looks identical to any legitimate one.
Capability-Scoped Permissions
The first step in solving the problem of agent permissions is to stop thinking about permissions in terms of resources and start thinking about them in terms of capabilities. A scope like billing:write describes a resource category and a verb. A capability like billing.refund.issue_under_50_usd encodes a specific action type, a resource limit, and an implicit risk boundary, although you would not typically encode a capability check into a scope like this, due to the inevitable explosion of scopes that would follow.
Capability-scoped permissions express authorization in terms the business actually reasons about. When a product manager decides the support agent should be able to issue courtesy refunds up to $50 USD, that decision should live in a declarative policy that the authorization system evaluates, not scattered through imperative checks in the application code that calls the API. Whether the $50 USD threshold is enforced by the authorization engine itself or by an in-code check, such as a dedicated policy layer that is consulted before token issuance is an implementation detail; what matters is that the rule is centrally managed and auditable.
This is where fine-grained authorization systems come in, and while they solve a specific piece of the puzzle, they're not always an all-in-one solution.
OpenFGA, an open-source authorization engine created by Auth0's FGA team and now a Cloud Native Computing Foundation (CNCF) project, implements Relationship-Based Access Control (ReBAC). ReBAC excels at modelling who can act on what. The support agent isn't just a role, but an entity with specific, bounded relationships to specific resource types, and those relationships produce different permissions. You can express rules like "an agent can refund an order only if the order belongs to a customer with whom the agent has an active ticket."
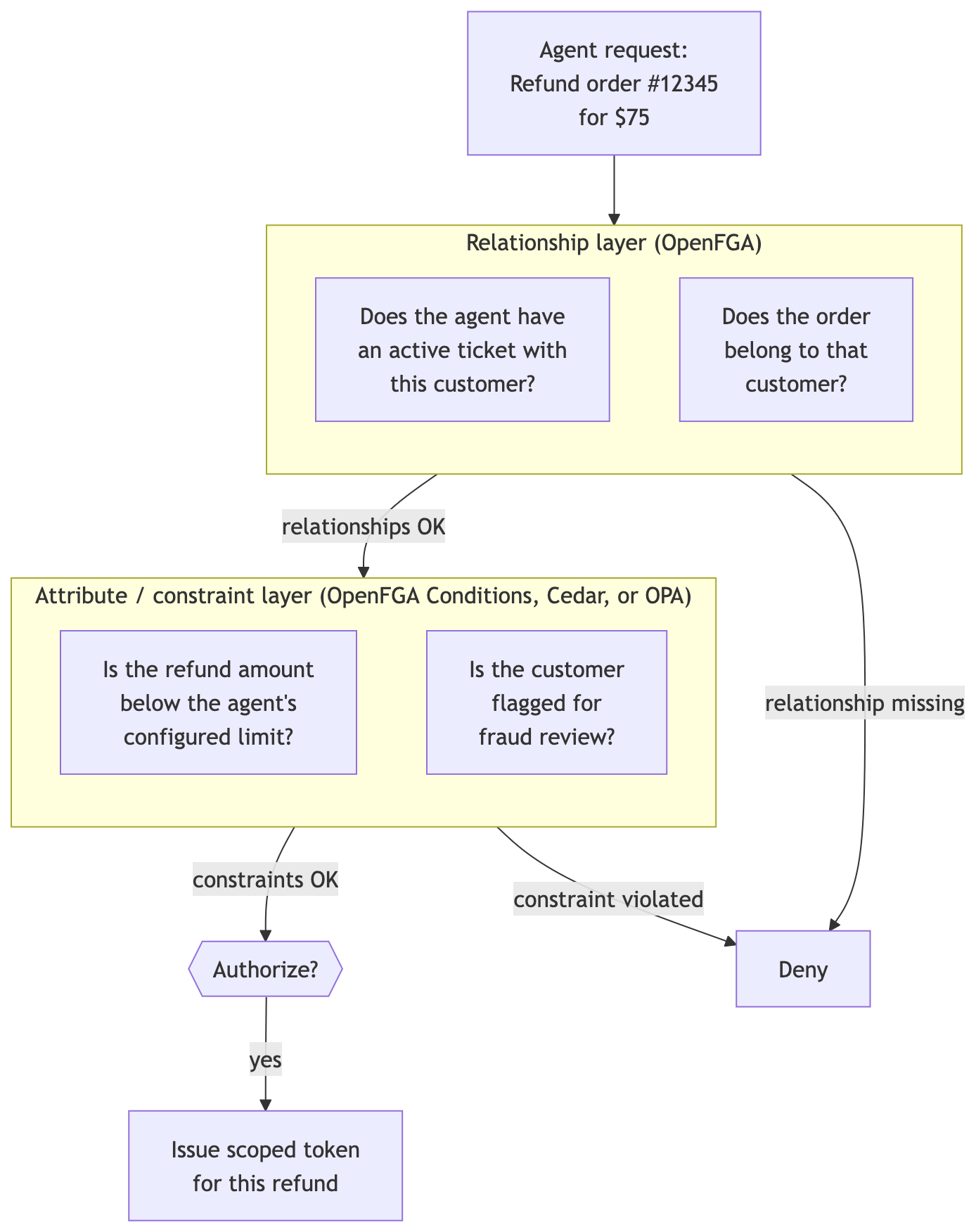
What pure ReBAC does not do is enforce numeric or attribute-based constraints like "refund amount under $100." OpenFGA extends the base ReBAC model with Conditions, which let you attach predicates to a relation so that numeric limits, time-bounded grants, and contextual attributes are evaluated as part of the authorization check.
In OpenFGA, the two layers in the diagram above collapse into a single check: the relationship and its condition are evaluated together, and either can deny. A capability like "agent can refund orders where amount < configured_limit" can be expressed directly in OpenFGA via a condition, with the amount supplied either in the tuple itself or contextually at check time. For teams that prefer to keep pure authorization policy separate from declarative policy code, a dedicated engine like Cedar or OPA layered on top is a legitimate alternative, but it isn't required; OpenFGA can handle both the relationship graph and the attribute constraints.
Concretely, a support-agent refund capability with a per-agent limit looks like this in OpenFGA's DSL:
model schema 1.1 type user type agent type customer type order relations define owner: [customer] define can_refund: [agent with refund_within_limit] condition refund_within_limit(refund_amount: int, agent_limit: int) { refund_amount <= agent_limit }
The capability is granted by writing a relationship tuple that carries the agent's configured limit as persisted condition context. For a support agent with a $50 USD ceiling:
await fgaClient.write({ writes: [ { user: "agent:support_agent_01", relation: "can_refund", object: "order:12345", condition: { name: "refund_within_limit", context: { agent_limit: 50 }, }, }, ], });
At check time, the runtime supplies the request-specific half of the condition context (the actual refund amount being attempted):
const { allowed } = await fgaClient.check({ user: "agent:support_agent_01", relation: "can_refund", object: "order:12345", context: { refund_amount: 75 }, });
OpenFGA merges the two sides when evaluating the condition, with persisted tuple context taking precedence over request context if a key appears in both. With agent_limit: 50 stored in the tuple and refund_amount: 75 supplied at check time, the condition refund_amount <= agent_limit evaluates to false and allowed comes back false; the agent cannot autonomously issue a $75 USD refund, and the runtime's next move is to trigger a human approval flow (covered later in this article) rather than request a refund-capable token.
The practical takeaway is to define capabilities that match actual business boundaries. Not billing:write, but billing.refund.issue_under_50_usd. Not crm:read, but crm.contact.read_for_assigned_tickets. When you catch yourself defining a capability that feels uncomfortably broad, take a moment to consider if you can strip it back to something less permissive, without compromising the functionality you're building.
Task-Scoped Credentials
Capability scoping addresses what the agent can do. Task scoping addresses when and for how long it can do it. These are separate concerns, and conflating them is a common mistake.
A well-designed agent minimizes or eliminates persistent credentials wherever possible. Instead of holding standing access, it requests short-lived tokens tied to each operation's execution plan. The token carries only the capabilities needed for that plan, expires quickly (minutes, not days), and is discarded after use. In practice, some systems still cache short-lived tokens or rely on scoped service accounts for infrastructure concerns. The goal is less about purity, and more about reducing the window in which any given credential is useful.
This pattern has several useful properties:
- The window for credential exposure incidents collapses, so a token leaked from an agent's memory is only useful for a short time.
- The blast radius of a compromised agent shrinks, because the agent can only act with whatever short-lived token it currently holds.
- The agent itself never touches the root credential. A separate component brokers tokens on the agent's behalf, so even if the agent process is compromised, the underlying OAuth refresh tokens or API keys are not.
Auth0's Token Vault implements this pattern at the identity layer. The vault securely stores OAuth tokens for connected services (Google, Slack, Salesforce, GitHub, and others), and the agent requests a just-in-time access token scoped to a specific task rather than handling the long-lived credential itself. Token Vault implements OAuth 2.0 Token Exchange (RFC 8693), giving it a standards-based foundation rather than a proprietary flow. Depending on the flow used, the agent may never touch the underlying refresh token at all; in the access-token-exchange flow designed for SPA-plus-backend architectures, the refresh token stays on the Auth0 side entirely.
For the support agent referenced in this article, this means that when it decides to issue a refund, it does not already hold a refund-capable token. The runtime first evaluates the request against the policy layer, asking questions like: is the amount within the agent's autonomous threshold, is the customer not flagged for fraud review, does the agent have the right relationship to this order, and only then requests a short-lived access token scoped to the refund capability and this specific customer. If the agent is compromised between tasks, there is no standing refund authority to exploit; any earlier token has already expired, and issuing a new one requires passing the policy checks again.
Identity, Authorization, and Execution Are Three Different Layers
A useful clarification when designing agent access control is to recognize that three distinct concerns are often collapsed into one implementation.
- Identity establishes who the agent is. It answers the question, "which agent, acting on behalf of which user, is making this request?" Identity is relatively stable; an agent typically has a consistent identity across many tasks.
- Authorization determines what an authenticated actor is permitted to do. It answers, "given this identity, what capabilities apply?" Authorization is a policy decision, and it should be evaluated fresh for each operation, not inherited from a long-lived grant.
- Execution enforcement determines what is actually allowed in a specific runtime context. It answers, "for this specific call, with this specific payload, does policy permit it?" This includes things like the refund amount, the target resource, and any contextual constraints that cannot be known until the request is actually made.
Conflating these leads to familiar failure modes. If identity and authorization are the same thing, then authority is frozen at authentication time and cannot adapt to the task being performed. Similarly, if authorization and execution are coupled, then policy cannot be centrally managed, audited, or updated. Each layer needs its own boundary, and each boundary should be enforced by a different component.
Architectural Separation
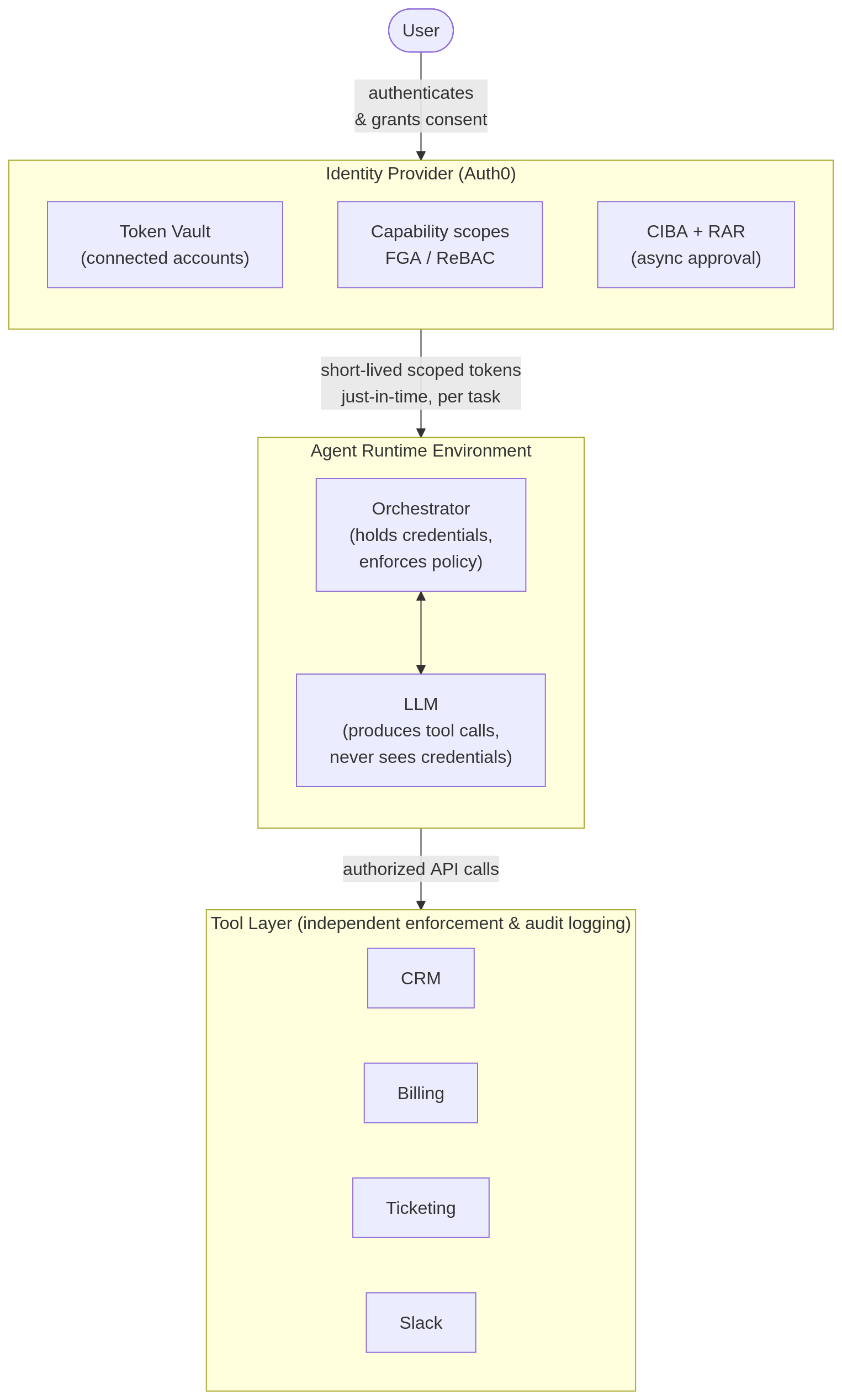
In practice, handling these three concerns means designing three distinct layers in any production agent system.
Identity provider layer
The identity provider layer handles authentication and token issuance. Auth0 authenticates users, manages connected accounts via Token Vault, issues scoped tokens, and handles delegation flows. The identity provider knows who the agent is and what capabilities are available to it, but does not execute business logic.
Runtime environment layer
The runtime environment layer interprets agent plans, requests credentials from the identity provider, and enforces policy before making calls to downstream tools. This is typically your agent orchestration code, often built on a framework like LangChain, LlamaIndex, or the Vercel AI SDK.
In a well-designed system, the runtime is separate from the LLM process itself: the LLM produces tool calls, but the runtime decides whether those calls are permitted, requests credentials for them, and makes the actual API calls. Many real-world agent systems fall short of this, passing API keys into tool wrappers or exposing tokens through tool configuration. Keeping credentials out of the LLM's reach is a design goal worth pursuing deliberately, not a property you get for free.
Tool layer
The tool layer is the downstream system, such as the CRM, billing service, or Slack API, that actually executes the operation. The tool layer is responsible for its own enforcement and logging, independent of whatever the agent or runtime believes is permitted. This defense ensures that even if the runtime is compromised, the tool still enforces its own authorization rules.
When this separation is maintained, it has a critical security benefit: the LLM process itself never holds credentials. The runtime brokers them, presents them for individual API calls, and discards them. A prompt injection attack that tries to convince the LLM to leak "its credentials" has nothing to leak, because the LLM was never given any.
Approval Boundaries for High-Risk Actions
Even with capability-scoped, task-scoped credentials, some actions warrant an extra step: explicit human approval at the moment of execution. This is not a fallback for a broken permission model. It's an intentional design choice for operations whose risk profile justifies the extra friction.
The question is, what actions cross that line. The support agent issuing a $5 USD refund probably should not require human approval; the automation value comes from handling those without intervention. The same agent attempting a $2,000 USD refund, a refund to an account flagged for fraud review, or any destructive action on a customer record is a different matter entirely. These are the operations where getting it right matters more than getting it fast.
Auth0 implements asynchronous approval using the Client-Initiated Backchannel Authentication (CIBA) standard, an OpenID Foundation specification that lets a client (such as an agent backend) request user approval out-of-band from a separate trusted device. Most production agent systems today handle approval through bespoke flows, internal policy engines, or workflow systems like Temporal. CIBA offers a standards-based alternative that slots into existing OAuth infrastructure rather than requiring a parallel approval system. When the support agent identifies that an operation exceeds its autonomous threshold, its backend sends a CIBA request to Auth0. The user receives a push notification on their enrolled mobile device via the Auth0 Guardian app (with sms or email also as supported channels), and the agent polls for a response. If the user approves, the agent receives a token scoped to that specific action. If the user denies or the request times out, nothing happens.
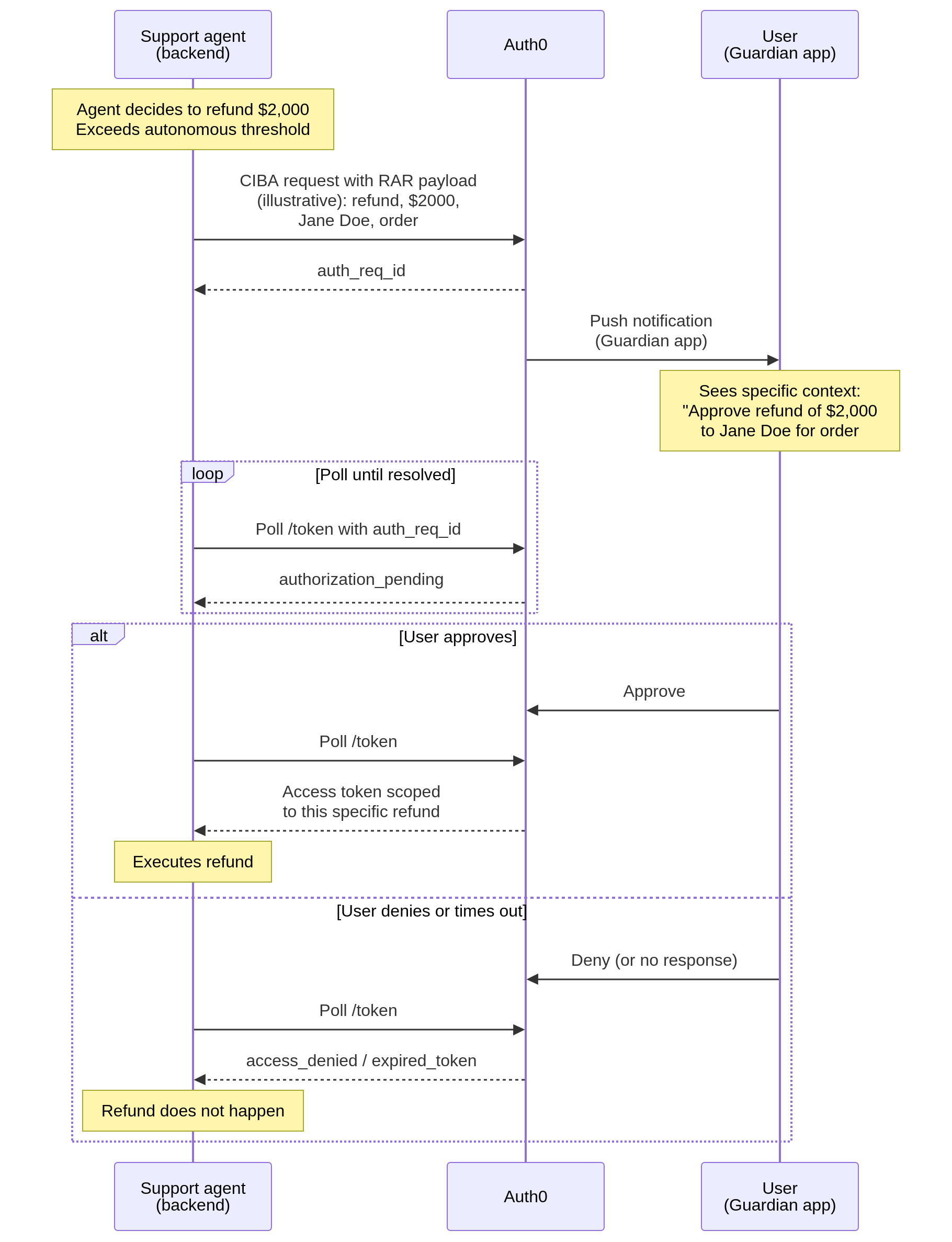
CIBA becomes more powerful when combined with Rich Authorization Requests (RAR), an OAuth 2.0 extension that lets the authorization request carry detailed, structured context about what is actually being approved. Rather than a generic "approve access to billing?" prompt, the user sees something specific, such as "approve refund of $2,000 to customer Jane Doe for order #12345." The structured authorization_details payload makes the approval verifiable and auditable in a way a broad scope grant cannot be.
This pattern directly addresses the $10,000 refund scenario. The agent's capability scope permits refunds under a low threshold autonomously. For anything above that, the agent cannot proceed without triggering a CIBA flow, and the user sees the exact amount and target before approving. The agent cannot bypass this because the token it needs to execute the refund is only issued after approval.
Observability and Control
The final layer is observability. An agent that operates under strict permission controls is still operating autonomously across many systems, and understanding what it did, why, and on whose behalf is essential for debugging, incident response, and compliance.
Three elements matter:
- Audit trails should capture agent decisions, not just actions. It's not enough to know that a refund was issued; you want to know which plan the agent was executing, which tool calls led to this point, and what context informed the decision.
- Delegation chains should be explicit, so a given API call is traceable back through
user → agent → sub-agent → tool → resource, with each hop recorded. - Revocation has to be fast and precise. If an agent is misbehaving, you need to revoke its standing grants, invalidate in-flight tokens, and halt further tool calls, without taking down the entire system.
Auth0's platform provides this infrastructure by centralizing token issuance, which means every token vended to an agent passes through a single control plane. Revoking a connection in Token Vault invalidates future token exchanges immediately, and the audit logs reflect every issuance and use.
A Permission Model for Agents
AI agents require access control models designed for non-deterministic, autonomous workflows. Permissions inherited wholesale from a human user, or from a static service account, are not fit for purpose. The agent will use them in ways neither the user nor the developer anticipated, and the existing access layer will not notice.
The three patterns that form the foundation of production-ready agent architectures are:
- capability-scoped permissions that encode specific actions and limits rather than broad resource verbs
- task-scoped credentials that are short-lived and tied to specific execution plans rather than persistent grants
- layered enforcement that separates identity, authorization, and execution into distinct components
Together, these patterns contain the blast radius of agent mistakes without removing the autonomy that makes agents useful.
About the author

Cameron Pavey
Senior Developer